Scrapy爬取博客内容
2015-11-19 17:50
190 查看
http://www.cnblogs.com/Jaryleely/p/careerOne.html
python中常用的写爬虫的库有urllib2、requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现。这里有一篇我之前写过的用urllib2+BeautifulSoup做的一个抓取百度音乐热门歌曲的例子,有兴趣可以看一下。本文介绍用Scrapy抓取我在博客园的博客列表,只抓取博客名称、发布日期、阅读量和评论量这四个简单的字段,以求用较简单的示例说明Scrapy的最基本的用法。
环境配置说明
操作系统:Ubuntu 14.04.2 LTS
Python:Python 2.7.6
Scrapy:Scrapy 1.0.3
注意:Scrapy1.0的版本和之前的版本有些区别,有些类的命名空间改变了。
创建项目
执行如下命令创建一个Scrapy项目
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
它的定义也很简单,只需要实现process_item方法即可,此方法有两个参数,一个是item,即要处理的Item对象,另一个参数是spider,即爬虫。
另外还有open_spider和close_spider两个方法,分别是在爬虫启动和结束时的回调方法。
本例中处理很简单,只是将接收的Item对象写到一个json文件中,在__init__方法中以“w+”的方式打开或创建一个item.json的文件,然后把对象反序列化为字符串,写入到item.json文件中。代码如下:
此例中的配置如下:
定义一个Spider需要如下几个变量和方法实现:
name:定义spider名字,这个名字应该是唯一的,在执行这个爬虫程序的时候,需要用到这个名字。
allowed_domains:允许爬取的域名列表,例如现在要爬取博客园,这里要写成cnblogs.com
start_urls:爬虫最开始爬的入口地址列表。
rules:如果要爬取的页面不是单独一个或者几个页面,而是具有一定的规则可循的,例如爬取的博客有连续多页,就可以在这里设置,如果定义了rules,则需要自己定义爬虫规则(以正则表达式的方式),而且需要自定义回调函数。
代码说话:
| 类 | 所在包 | |
| 1.0版本 | 之前版本 | |
Spider | scrapy.spiders | scrapy.spider |
CrawlSpider | scrapy.spiders | scrapy.contrib.spiders |
LinkExtractor | scrapy.linkextractors | scrapy.contrib.linkextractors |
Rule | scrapy.spiders | scrapy.contrib.spiders |
首先进入到我的博客页面http://www.cnblogs.com/fengzheng/,这是我的博客首页,以列表形式显示已经发布的博文,这是第一页,点击页面下面的下一页按钮,进入第二页,页面地址为http://www.cnblogs.com/fengzheng/default.html?page=2,由此看出网站以page作为参数来表示页数,这样看来爬虫的规则就很简单了, fengzheng/default.html\?page\=([\d]+),这个就是爬虫的规则,爬取default.html页面,page参数为数字的页面,这样无论有多少页都可以遍历到。当然,如果页面数量很少可以在start_urls列表中,将要爬取的页面都列出来,但是这样当博文数量增多就会出现问题,如下:

之后,分析网页源码,分析出xpath
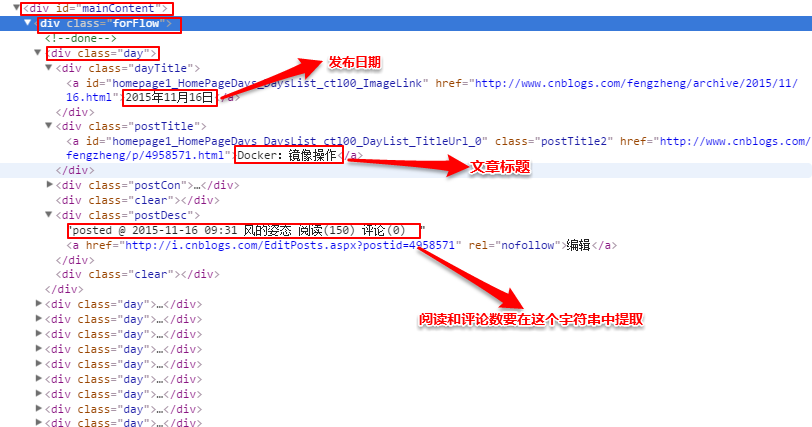
用如下代码找到所有的class为day的div,每一个就是一个博文区域:
因为有中文内容,要对获取的内容进行encode("utf-8")编码
由于评论数和阅读量混在一起,要对那个字符串再进行正则表达式提取
至此,简单的爬虫已经完成,接下来要运行这个爬虫,cd进入到爬虫项目所在的目录,执行以下命令:

之后会看到,根目录中多了一个item.json文件,cat此文件内容,可以看到信息已经被提取出来:

点击这里在github获取源码
人生没有回头路,珍惜当下。

相关文章推荐
- java 选择排序法
- mysql存储过程
- UIPageControl页控制器
- C语言公式--爱情的年轮
- struts2 ajax一个很经典的小例子
- PHP将编码转为UTF-8
- NSURLSession使用说明及后台工作流程分析
- 格形变算法(Linear rotation-invariant coordinates和As-Rigid-As-Possible)
- Mac OS上反编译android app的环境搭建
- jQuery插件之ajaxFileUpload API文档
- Delphi 10 Seattle Update 1 修复 iOS HTTP 协定需求
- Android 布局参数
- [python&php 网络编程]格式化IPv4地址
- oracle函数wmsys.wm_concat--有道笔记整理
- Thrift安装配置及使用python通过thrift连接HBase测试
- skynet1.0阅读笔记_skynet的启动
- 用HTML5播放IPCamera视频
- OpenGL 学习笔记(一)——开始以及OPENGL环境配置
- Android 下拉控件:Spinner
- bootstrap入门元素