Linux内核原理-pid namespace
2015-11-19 13:31
465 查看
前言
这几晚在看进程相关的内核原理,正好看到了pid这块,看起来不是很复杂,但是引入了pid namespace后增加了一些数据结构,看起来不是那么清晰了,参考了Linux内核架构这本书,看完后感觉还没有理解。所以就在网上找了一些文章参考,其中我发现了一篇质量相当不错的文章,为什么说质量不错呢主要是因为笔者在博文中并没有乱贴代码一桶,也没有按照常规的代码分析,而是以一种追踪溯源的方法还原了整个pid的框架,读了这篇文章后感觉甚好,因此有了本文,本文算不上原创,只是在此基础上将自己的理解重新进行了梳理,相关的图表进行了重绘,加入了一些数据结构的含义表述。关于这篇文章的链接可以参考附录APID框架的设计
一个框架的设计会考虑很多因素,相信分析过Linux内核的读者来说会发现,内核的大量数据结构被哈希表和链表链接起来,最最主要的目的就是在于查找。可想而知一个好的框架,应该要考虑到检索速度,还有考虑功能的划分。那么在PID框架中,需要考虑以下几个因素.如何通过task_struct快速找到对应的pid
如何通过pid快速找到对应的task_struct
如何快速的分配一个唯一的pid
这些都是PID框架设计的时候需要考虑的一些基本的因素。也正是这些因素将PID框架设计的愈加复杂。
原始的PID框架
先考虑的简单一点,一个进程对应一个pidstruct task_struct
{
.....
pid_t pid;
.....
}是不是很easy,回到上文,看看是否符合PID框架的设计原则,通过task_struct找到pid,很方便,但是通过pid找到task_struct怎么办呢?好吧,基于现在的这种结构肯定是无法满足需求的,那就继续改进吧。
注: 以上的这种设计来自与linux 2.4内核的设计
引入hlist和pid位图
struct task_struct *pidhash[PIDHASH_SZ];
struct pidmap {
atomic_t nr_free; //表示当前可用的pid个数
void *page; //用来存放位图
};这样就很方便了,再看看PID框架设计的一些因素是否都满足了,如何分配一个唯一的pid呢,连续递增?,那么前面分配的进程如果结束了,那么分配的pid就需要回收掉,直到分配到PID的最大值,然后从头再继续。好吧,这或许是个办法,但是是不是需要标记一下那些pid可用呢?到此为此这看起来似乎是个解决方案,但是考虑到这个方案是要放进内核,开发linux的那帮家伙肯定会想近一切办法进行优化的,的确如此,他们使用了pid位图,但是基本思想没有变,同样需要标记pid是否可用,只不过使用pid位图的方式更加节约内存.想象一下,通过将每一位设置为0或者是1,可以用来表示是否可用,第1位的0和1用来表示pid为1是否可用,以此类推.到此为此一个看似还不错的pid框架设计完成了,下图是目前整个框架的整体效果.
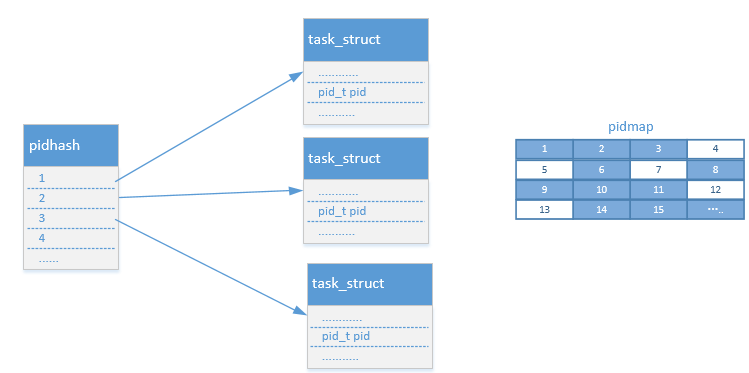
引入PID类型后的PID框架
熟悉linux的读者应该知道一个进程不光光只有一个进程pid,还会有进程组id,还有会话id,(关于进程组和会话请参考(进程之间的关系)那么引入pid类型后,框架变成了下面这个样子,struct task_struct
{
....
pid_t pid;
pid_t session;
struct task_struct *group_leader;
....
}
struct signal
{
....
pid_t __pgrp;
....
}
来自于kernel 2.6.24对于进程组id来说,信号需要知道这这个id,通过这个id,可以实现对一组进程进行控制,所以这个id出现在了signal这个结构体中.所以直到现在来说框架还不是那么复杂,但是有一个需要明确的就是无论是session id还是group id其实都不占用pid的资源,因为session id是和领导进程组的组id相同,而group id则是和这个进程组中的领导进程的pid相同.
引入进程PID命名空间后的PID框架
随着内核不断的添加新的内核特性,尤其是PID Namespace机制的引入,这导致PID存在命名空间的概念,并且命名空间还有层级的概念存在,高级别的可以被低级别的看到,这就导致高级别的进程有多个PID,比如说在默认命名空间下,创建了一个新的命名空间,占且叫做level1,默认命名空间这里称之为level0,在level1中运行了一个进程在level1中这个进程的pid为1,因为高级别的pid namespace需要被低级别的pid namespace所看见,所以这个进程在level0中会有另外一个pid,为xxx.套用上面说到的pid位图的概念,可想而知,对于每一个pid namespace来说都应该有一个pidmap,上文中提到的level1进程有两个pid一个是1,另一个是xxx,其中pid为1是在level1中的pidmap进行分配的,pid为xxx则是在level0的pidmap中分配的. 下面这幅图是整个pidnamespace的一个框架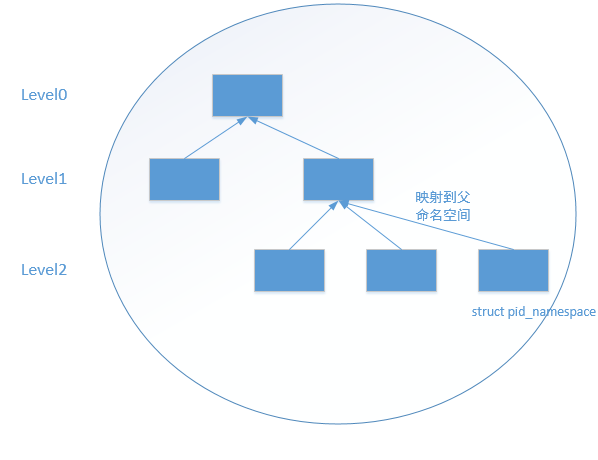
.引入了PID命名空间后,一个pid就不仅仅是一个数值那么简单了,还要包含这个pid所在的命名空间,父命名空间,命名空间多对应的pidmap,命名空间的pid等等.因此内核对pid做了一个封装,封装成struct pid,一个名为pid的结构体,下面是其定义:
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
struct pid
{
unsigned int level; //这个pid所在的层级
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; //一个hash表,又三个表头,分别是pid表头,进程组id表头,会话id表头,后面再具体介绍
struct upid numbers[1]; //这个pid对应的命名空间,一个pid不仅要包含当前的pid,还有包含父命名空间,默认大小为1,所以就处于根命名空间中
};
struct upid { //包装命名空间所抽象出来的一个结构体
int nr; //pid在该命名空间中的pid数值
struct pid_namespace *ns; //对应的命名空间
struct hlist_node pid_chain; //通过pidhash将一个pid对应的所有的命名空间连接起来.
};
struct pid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES]; //上文说到的,一个pid命名空间应该有其独立的pidmap
int last_pid; //上次分配的pid
unsigned int nr_hashed;
struct task_struct *child_reaper; //这个pid命名空间对应的init进程,因为如果父进程挂了需要找养父啊,这里指明了该去找谁
struct kmem_cache *pid_cachep;
unsigned int level; //所在的命名空间层次
struct pid_namespace *parent; //父命名空间,构建命名空间的层次关系
struct user_namespace *user_ns;
struct work_struct proc_work;
kgid_t pid_gid;
int hide_pid;
int reboot; /* group exit code if this pidns was rebooted */
unsigned int proc_inum;
};
//上面还有一些复杂的成员,这里的讨论占且用不到引入了pid namespace后,的确变得很复杂了,多了很多看不懂的数据结构.进程如何和struct pid关联起来呢,内核为了统一管理pid,进程组id,会话id,将这三类id,进行了整合,也就是现在task_struct要和三个struct pid关联,还要区分struct pid的类型.所以内核又引入了中间结构将task_struct和pid进行了1:3的关联.其结构如下:
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
struct task_struct
{
.............
pid_t pid;
struct pid_link pids[PIDTYPE_MAX];
.............
}
struct pid
{
unsigned int level; //这个pid所在的层级
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; //一个hash表,又三个表头,分别是pid表头,进程组id表头,会话id表头,用于和task_struct进行关联
struct upid numbers[1]; //这个pid对应的命名空间,一个pid不仅要包含当前的pid,还有包含父命名空间,默认大小为1,所以就处于根命名空间中
};
使用pid的tasks hash表和task_struct中pids结构中的hlist_node关联起来了.到此为止一个看起来已经比较完善的pid框架构建完成了,整个框架的效果如下:
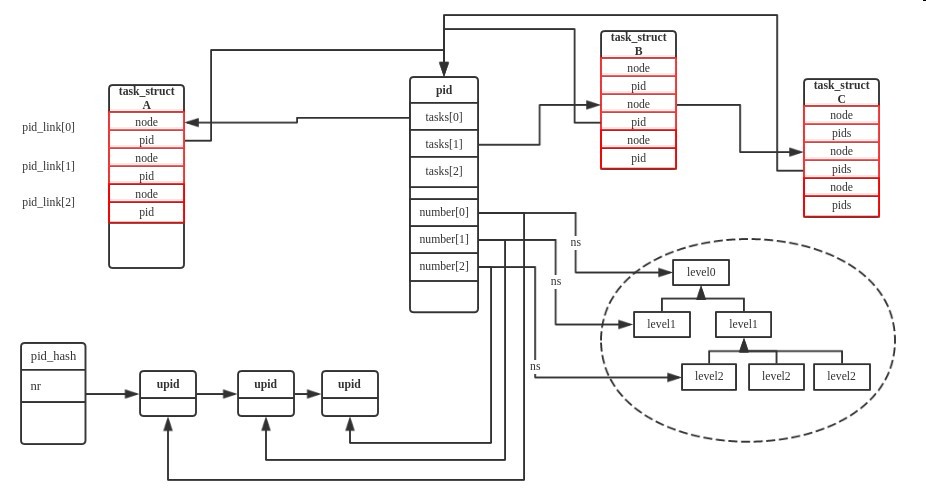
其中进程A,B,C是一个进程组的,A是组长进程,所以B,和C的task_struct结构体中的pid_link成员的node字段就被邻接到进程A对应的struct pid中的tasks[1].struct upid通过pid_hash和pid数值关联了起来,这样就可以通过pid数值快速的找到所有命名空间的upid结构,numbers是一个struct pid的最后一个成员,利用可变数组来表示这个pid结构当前有多少个命名空间.
注: 2016/08/28 修正上图的一个错误,pid_hash的key并不是nr,应该是
pid_hashfn(upid->nr, upid->ns)]唯一确定一个upid结构(具体可以参考pid_hashfn的实现),这样就可以通过nr和ns来找到其对应的upid结构了。
为了验证我们这个框架,下面是一些PID相关的函数,通过函数的实现来验证下这个框架.
进程PID相关的API分析
获取三种类型的pid结构
static inline struct pid *task_pid(struct task_struct *task)
{
return task->pids[PIDTYPE_PID].pid;
}
/*
* Without tasklist or rcu lock it is not safe to dereference
* the result of task_pgrp/task_session even if task == current,
* we can race with another thread doing sys_setsid/sys_setpgid.
*/
static inline struct pid *task_pgrp(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_PGID].pid;
}
static inline struct pid *task_session(struct task_struct *task)
{
return task->group_leader->pids[PIDTYPE_SID].pid;
}获取pid结构中的某一个名字空间的pid数值
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
{
struct upid *upid;
pid_t nr = 0;
//判断传入的pid namespace层级是否符合要求
if (pid && ns->level <= pid->level) {
upid = &pid->numbers[ns->level]; //去到对应pid namespace的strut upid结构
if (upid->ns == ns) //判断命名空间是否一致
nr = upid->nr; //获取pid数值
}
return nr;
}看看如何分配一个pid吧
struct pid *alloc_pid(struct pid_namespace *ns) //pid分配要依赖与pid namespace,也就是说这个pid是属于哪个pid namespace
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
//分配一个pid结构
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
tmp = ns;
pid->level = ns->level; //初始化level
//递归到上面的层级进行pid的分配和初始化
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp); //从当前pid namespace开始知道全局pid namespace,每一个层级都分配一个pid
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr; //初始化upid结构
pid->numbers[i].ns = tmp;
tmp = tmp->parent; //递归到父亲pid namespace
}
if (unlikely(is_child_reaper(pid))) { //如果是init进程需要做一些设定,为其准备proc目录
if (pid_ns_prepare_proc(ns))
goto out_free;
}
get_pid_ns(ns);
atomic_set(&pid->count, 1);
for (type = 0; type < PIDTYPE_MAX; ++type) //初始化pid中的hlist结构
INIT_HLIST_HEAD(&pid->tasks[type]);
upid = pid->numbers + ns->level; //定位到当前namespace的upid结构
spin_lock_irq(&pidmap_lock);
if (!(ns->nr_hashed & PIDNS_HASH_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]); //建立pid_hash,让pid和pid namespace关联起来
upid->ns->nr_hashed++;
}
spin_unlock_irq(&pidmap_lock);
out:
return pid;
out_unlock:
spin_unlock_irq(&pidmap_lock);
put_pid_ns(ns);
out_free:
while (++i <= ns->level)
free_pidmap(pid->numbers + i);
kmem_cache_free(ns->pid_cachep, pid);
pid = NULL;
goto out;
}附录
附录A 参考链接
Linux 内核进程管理之进程ID
相关文章推荐
- Flex Namespace的用法
- PowerShell获取当前进程PID的小技巧
- linux mysql 报错:MYSQL:The server quit without updating PID file
- ajax使用不同namespace的action的方法
- iisapp.vbs iis pid了解对应的网站或应用池
- w3wp.exe占用cpu过高的解决方法第1/2页
- 怎样通过iisapp命令查找pid来解决IIS的cpu占用率过高问题
- thinkphp autoload 命名空间自定义 namespace
- PHP命名空间(namespace)的使用基础及示例
- MySQL下PID文件丢失的相关错误的解决方法
- C++ namespace相关语法实例分析
- PHP命名空间(Namespace)简明教程
- PHP命名空间(Namespace)的使用详解
- JavaScript创建命名空间(namespace)的最简实现
- ASP.Net中命名空间Namespace浅析和使用例子
- Android中的UID和PID意义,及查看方式
- C++ 匿名namespace的作用以及它与static的区别
- 这个小例子也许能帮助大家理解一下SIGUSR1的用法
- 不要在头文件中使用 using
- namespace的用法