特征选择(三)-K-L变换
2015-11-12 23:37
260 查看
上一讲说到,各个特征(各个分量)对分类来说,其重要性当然是不同的。
舍去不重要的分量,这就是降维。
聚类变换认为:重要的分量就是能让变换后类内距离小的分量。
类内距离小,意味着抱团抱得紧。
但是,抱团抱得紧,真的就一定容易分类么?
如图1所示,根据聚类变换的原则,我们要留下方差小的分量,把方差大(波动大)的分量丢掉,所以两个椭圆都要向y轴投影,这样悲剧了,两个重叠在一起,根本分不开了。而另一种情况却可以这么做,把方差大的分量丢掉,于是向x轴投影,很顺利就能分开了。因此,聚类变换并不是每次都能成功的。
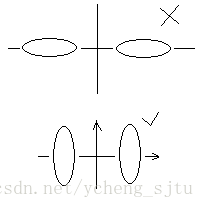
图1
摧枯拉朽的K-L变换
K-L变换是理论上“最好”的变换:是均方误差(MSE,MeanSquare Error)意义下的最佳变换,它在数据压缩技术中占有重要地位。
聚类变换还有一个问题是,必须一类一类地处理,把每类分别变换,让它们各自抱团。
K-L变换要把所有的类别放在一起变换,希望通过这个一次性的变换,让它们分的足够开。
K-L变换认为:各类抱团紧不一定好区分。目标应该是怎么样让类间距离大,或者让不同类好区分。因此对应于2种K-L变换。
其一:最优描述的K-L变换(沿类间距离大的方向降维)
首先来看个二维二类的例子,如图2所示。
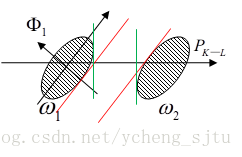
图2

如果使用聚类变换,

方向是方差最小的方向,因此降维向
方向投影,得到2类之间的距离即为2条红线之间的距离,但是这并不是相隔最远的投影方向。将椭圆投影到

方向,得到2类之间的距离为2条绿线之间的距离。这个方向就是用自相关矩阵的统计平均得到的特征向量

设共有M个类别,各类出现的先验概率为

以
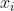
表示来自第i类的向量。则第i类集群的自相关矩阵为:

混合分布的自相关矩阵R是:

然后求出R的特征向量和特征值:

将特征值降序排列(注意与聚类变换区别)
为了降到m维,取前m个特征向量,构成变换矩阵A

以上便完成了最优描述的K-L变换。
为什么K-L变换是均方误差(MSE,MeanSquare Error)意义下的最佳变换?

其中

表示n维向量y的第j个分量,

表示第个特征分量。
引入的误差

均方误差为

从m+1开始的特征值都是最小的几个,所以均方误差得到最小。
以上方法称为最优描述的K-L变换,是沿类间距离大的方向降维,从而均方误差最佳。
本质上说,最优描述的K-L变换扔掉了最不显著的特征,然而,显著的特征其实并不一定对分类有帮助。我们的目标还是要找出对分类作用大的特征,而不应该管这些特征本身的强弱。这就诞生了第2种的K-L变换方法。
其二:最优区分的K-L变换(混合白化后抽取特征)
针对上述问题,最优区分的K-L变换先把混合分布白化,再来根据特征值的分离程度进行排序。
最优区分的K-L变换步骤
首先还是混合分布的自相关矩阵R
然后求出R的特征向量和特征值:

以上是主轴变换,实际上是坐标旋转,之前已经介绍过。
令变换矩阵

则有

这个

作用是白化R矩阵,这一步是坐标尺度变换,相当于把椭圆整形成圆,如图3所示。
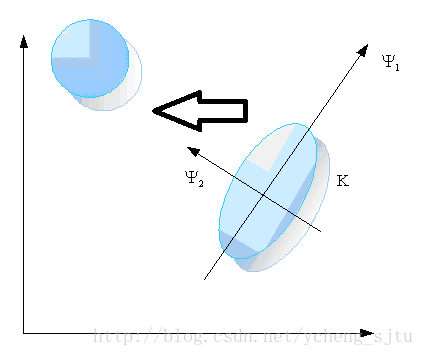
图3
以二类混合分布问题为例。

分别求出二类的特征向量和特征值,有

则二者的特征向量完全相同,唯一的据别在于其特征根,而且还负相关,即如果

取降序排列时,则

以升序排列。
为了获得最优区分,要使得两者的特征值足够不同。因此,需要舍弃特征值接近0.5的那些特征,而保留使

大的那些特征,按这个原则选出了m个特征向量记作

则总的最优区分的K-L变换就是:

舍去不重要的分量,这就是降维。
聚类变换认为:重要的分量就是能让变换后类内距离小的分量。
类内距离小,意味着抱团抱得紧。
但是,抱团抱得紧,真的就一定容易分类么?
如图1所示,根据聚类变换的原则,我们要留下方差小的分量,把方差大(波动大)的分量丢掉,所以两个椭圆都要向y轴投影,这样悲剧了,两个重叠在一起,根本分不开了。而另一种情况却可以这么做,把方差大的分量丢掉,于是向x轴投影,很顺利就能分开了。因此,聚类变换并不是每次都能成功的。
图1
摧枯拉朽的K-L变换
K-L变换是理论上“最好”的变换:是均方误差(MSE,MeanSquare Error)意义下的最佳变换,它在数据压缩技术中占有重要地位。
聚类变换还有一个问题是,必须一类一类地处理,把每类分别变换,让它们各自抱团。
K-L变换要把所有的类别放在一起变换,希望通过这个一次性的变换,让它们分的足够开。
K-L变换认为:各类抱团紧不一定好区分。目标应该是怎么样让类间距离大,或者让不同类好区分。因此对应于2种K-L变换。
其一:最优描述的K-L变换(沿类间距离大的方向降维)
首先来看个二维二类的例子,如图2所示。
图2
如果使用聚类变换,
方向是方差最小的方向,因此降维向
方向投影,得到2类之间的距离即为2条红线之间的距离,但是这并不是相隔最远的投影方向。将椭圆投影到
方向,得到2类之间的距离为2条绿线之间的距离。这个方向就是用自相关矩阵的统计平均得到的特征向量
设共有M个类别,各类出现的先验概率为
以
表示来自第i类的向量。则第i类集群的自相关矩阵为:
混合分布的自相关矩阵R是:
然后求出R的特征向量和特征值:
将特征值降序排列(注意与聚类变换区别)
为了降到m维,取前m个特征向量,构成变换矩阵A
以上便完成了最优描述的K-L变换。
为什么K-L变换是均方误差(MSE,MeanSquare Error)意义下的最佳变换?
其中
表示n维向量y的第j个分量,
表示第个特征分量。
引入的误差
均方误差为
从m+1开始的特征值都是最小的几个,所以均方误差得到最小。
以上方法称为最优描述的K-L变换,是沿类间距离大的方向降维,从而均方误差最佳。
本质上说,最优描述的K-L变换扔掉了最不显著的特征,然而,显著的特征其实并不一定对分类有帮助。我们的目标还是要找出对分类作用大的特征,而不应该管这些特征本身的强弱。这就诞生了第2种的K-L变换方法。
其二:最优区分的K-L变换(混合白化后抽取特征)
针对上述问题,最优区分的K-L变换先把混合分布白化,再来根据特征值的分离程度进行排序。
最优区分的K-L变换步骤
首先还是混合分布的自相关矩阵R
然后求出R的特征向量和特征值:
以上是主轴变换,实际上是坐标旋转,之前已经介绍过。
令变换矩阵
则有
这个
作用是白化R矩阵,这一步是坐标尺度变换,相当于把椭圆整形成圆,如图3所示。
图3
以二类混合分布问题为例。
分别求出二类的特征向量和特征值,有
则二者的特征向量完全相同,唯一的据别在于其特征根,而且还负相关,即如果
取降序排列时,则
以升序排列。
为了获得最优区分,要使得两者的特征值足够不同。因此,需要舍弃特征值接近0.5的那些特征,而保留使
大的那些特征,按这个原则选出了m个特征向量记作
则总的最优区分的K-L变换就是:

相关文章推荐
- windows装系统磁盘不能格式化的解决方法
- iOS/OS X内存管理(一):基本概念与原理
- CentOS_5x防火墙模板
- 特征选择(二)-聚类变换
- 循环比赛日程表(match)
- poj 2601 公式推导
- C++中子类继承父类构造器和析构器的执行顺序
- 旭说数据结构之栈的小题目
- 特征选择(一)-维数问题与类内距离
- java线程池学习
- C#学习笔记 特性
- 虚函数、纯虚函数、普通函数的区别
- 黑白棋子的移动
- 我的iOS学习历程 - 自定义视图
- 我的iOS学习历程 - 自定义视图
- Objective-C 程序设计 第十二章
- CGFloat,CGPoint,CGSize,CGRect,CGRectZero
- JavaScript 回调函数中的 return false 问题
- 常用、简单、便捷的windows命令
- Li ux shell 四则运算