编译器架构的王者LLVM——(5)语法树模型的基本结构
2015-11-10 12:01
671 查看
LLVM平台,短短几年间,改变了众多编程语言的走向,也催生了一大批具有特色的编程语言的出现,不愧为编译器架构的王者,也荣获2012年ACM软件系统奖 —— 题记
版权声明:本文为 西风逍遥游 原创文章,转载请注明出处 西风世界 http://blog.csdn.net/xfxyy_sxfancy
其实思路很简单,每一层其实就是一个链表,将兄弟节点串起来,这样就可以了。
于是我们构建一个Node类,这就是上次我们脚本中看到的那个节点类。是不是很简单呢?
另外我们在写个make_list,方便我们构造一个链表,至于怎么写,我们一会儿再谈。
而且不但有这个要求,更重要的是语法树能够方便的构造LLVM语句,所以方便的一个设计就是利用多态,虽然效率或内存占用不像用union那么实在,但确实比较方便。
于是我们建立了一堆类,分别从Node派生,当然Node也需要添加一些功能来判断当前的节点类型。
Node.h
IDNode.h 是我们的标识符类,就继承自Node,其他类型同理,我就不一一列举,详细代码请参考 github上的源码
于是我们的make_list和getList函数就是这样写出来的:
首先要介绍的是LLVM类型系统的使用,因为LLVM的每条语句都是带有类型的,LLVM语句可以转换成Value型指针,那么我们用如下的方法就可以获取到当前的类型:
Type类型也很容易使用,例如获取其指针就可以:
Type类型中还有很多静态函数可供生成基本类型:
我们刚才AST语法树中的基本类型,其实都是语法中的常量(除了IDNode),那么这些都应该是生成常量类型
常量类型的基类是Constant,而常用的一般是ConstantInt、ConstantFP和ConstantExpr
下面我们就直接写出整形、全局字符串、浮点数对应的LLVM代码
这里最复杂的应该就属常量字符串了,首先,常量字符串要用ConstantDataArray::getString类型,然而,往往函数却不接收一个字符串类型的变量,你需要像C语言一样,将它的首地址作为参数传进去,记得我们之前写过的printf函数的定义么?第一个参数就是一个char*指针。
所以我们这里用一条语句,ConstantExpr::getGetElementPtr,对其取地址,indices是一个数组,第一个值是假设指针是个数组,取数组的第几位的地址,第二个值是假设指针指向的是一个结构体,取结构体中第几条元素的地址。
这里我们都传常量0就可以了。另外一个需要注意的是,这里取地址的常量0好像不能用int64类型,大概是数据范围太大怕越界吧,一般int32长的数组也够用了。之前我没注意,用int64,总出莫名其妙的问题。
版权声明:本文为 西风逍遥游 原创文章,转载请注明出处 西风世界 http://blog.csdn.net/xfxyy_sxfancy
语法树模型的基本结构
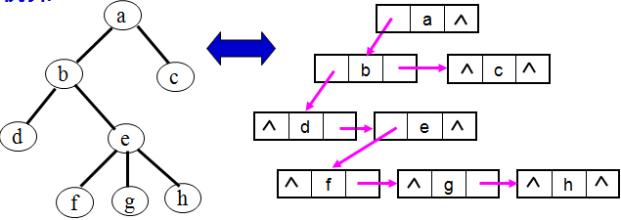
上次我们看了Lex和Yacc的翻译文件,可能一些朋友并不了解其中的执行部分,而且,对这个抽象语法树是怎么构建起来的还不清楚。今天我们就再详细介绍一下如果方便的构建一棵抽象语法树(AST)Node节点链接的左孩子,右兄弟二叉树
AST语法树,由于是一棵多叉树,直接表示不大好弄,所以我们采用计算机树中的一个经典转换,将多叉树转换为左孩子右兄弟的二叉树。其实思路很简单,每一层其实就是一个链表,将兄弟节点串起来,这样就可以了。
class Node
{
public:
Node();
Node(Node* n);
~Node();
// 构建列表部分
void addChildren(Node* n);
void addBrother (Node* n);
static Node* make_list(int num, ...);
static Node* getList(Node* node);
Node* getNext() { return next; }
Node* getChild() { return child; }
protected:
Node* next;
Node* child;
};于是我们构建一个Node类,这就是上次我们脚本中看到的那个节点类。是不是很简单呢?
另外我们在写个make_list,方便我们构造一个链表,至于怎么写,我们一会儿再谈。
类型支持
我们发现,我们的语法树还不能保存任何数据,我们写AST,是为了在每个节点上存储数据的,有字符串、字符、整数、浮点数、标识符等等。而且不但有这个要求,更重要的是语法树能够方便的构造LLVM语句,所以方便的一个设计就是利用多态,虽然效率或内存占用不像用union那么实在,但确实比较方便。
于是我们建立了一堆类,分别从Node派生,当然Node也需要添加一些功能来判断当前的节点类型。
Node.h
enum NodeType // 类型枚举
{
node_t = 0, int_node_t, float_node_t, char_node_t, id_node_t, string_node_t
};
class CodeGenContext;
class Node
{
public:
Node();
Node(Node* n); // 直接将n作为孩子加入这个节点下
~Node();
// 构建列表部分
void addChildren(Node* n);
void addBrother (Node* n);
bool isSingle();
static Node* make_list(int num, ...);
static Node* getList(Node* node);
void print(int k); // 打印当前节点
Node* getNext() { return next; }
Node* getChild() { return child; }
virtual Value* codeGen(CodeGenContext* context); LLVM的代码生成
// 这里负责获取或设置当前节点的LLVM类型, 未知类型返回NULL
virtual Type* getLLVMType();
virtual void setLLVMType(Type* t);
// 如果是含有字符串的节点,则返回所含字符串,否则将报错
std::string& getStr();
// 类型相关
std::string getTypeName();
virtual NodeType getType();
bool isNode();
bool isIntNode();
bool isFloatNode();
bool isIDNode();
bool isStringNode();
bool isCharNode();
protected:
virtual void printSelf(); // 打印自己的名字
void init();
Type* llvm_type;
Node* next;
Node* child;
};IDNode.h 是我们的标识符类,就继承自Node,其他类型同理,我就不一一列举,详细代码请参考 github上的源码
#include "Node.h"
#include <string>
using namespace std;
class IDNode: public Node {
public:
IDNode(const char* _value){
this->value = _value;
}
IDNode(char _value){
this->value = _value;
}
std::string& getStr() { return value; }
virtual Value* codeGen(CodeGenContext* context);
virtual NodeType getType();
protected:
virtual void printSelf();
private:
string value;
};AST构建中的一个问题
语法树构建时,有一个特别的问题,主要是因为这里有个地方设计的不大好,我没有单独做一个List类型,来存储孩子元素,而是将其直接打包到Node中了。那么当前正等待构建的节点,是一个元素,还是一个元素列表就很难判断。于是我制作了一个isSingle函数来判断当前元素是不是单独的元素,方法就是检测其Next指针是否为空即可。如果是单一元素,构建列表时,可以将其直接插入到当前序列的末尾,如果不是,则新建一个Node节点,然后将其孩子指针指向待插入元素。于是我们的make_list和getList函数就是这样写出来的:
Node* Node::make_list(int num, ...) {
va_list argp; Node* para = NULL;
Node* ans = NULL;
va_start( argp, num );
for (int i = 0; i < num; ++i) {
para = va_arg( argp, Node* );
if (!para->isSingle()) para = new Node(para);
if ( ans == NULL )
ans = para;
else ans->addBrother(para);
}
va_end( argp );
return ans;
}
Node* Node::getList(Node* node) {
if (!node->isSingle()) return new Node(node);
return node;
}基本的LLVM语句生成
我们构建这么多类的目的是用其生成LLVM语句的,那么我们就先来生成几个简单的语句首先要介绍的是LLVM类型系统的使用,因为LLVM的每条语句都是带有类型的,LLVM语句可以转换成Value型指针,那么我们用如下的方法就可以获取到当前的类型:
Type* t = value->getType();
Type类型也很容易使用,例如获取其指针就可以:
PointerType* ptr_type = t->getPointerTo();
Type类型中还有很多静态函数可供生成基本类型:
// 获取基本类型 static Type * getVoidTy (LLVMContext &C) static Type * getFloatTy (LLVMContext &C) static Type * getDoubleTy (LLVMContext &C) static Type * getMetadataTy (LLVMContext &C) // 获取不同长度整形类型 static IntegerType * getInt8Ty (LLVMContext &C) static IntegerType * getInt16Ty (LLVMContext &C) static IntegerType * getInt32Ty (LLVMContext &C) static IntegerType * getInt64Ty (LLVMContext &C) // 获取指向不同类型的指针类型 static PointerType * getFloatPtrTy (LLVMContext &C, unsigned AS=0) static PointerType * getDoublePtrTy (LLVMContext &C, unsigned AS=0) static PointerType * getInt8PtrTy (LLVMContext &C, unsigned AS=0) static PointerType * getInt16PtrTy (LLVMContext &C, unsigned AS=0) static PointerType * getInt32PtrTy (LLVMContext &C, unsigned AS=0) static PointerType * getInt64PtrTy (LLVMContext &C, unsigned AS=0)
我们刚才AST语法树中的基本类型,其实都是语法中的常量(除了IDNode),那么这些都应该是生成常量类型
常量类型的基类是Constant,而常用的一般是ConstantInt、ConstantFP和ConstantExpr
下面我们就直接写出整形、全局字符串、浮点数对应的LLVM代码
Value* IntNode::codeGen(CodeGenContext* context) {
Type* t = Type::getInt64Ty(*(context->getContext()));
setLLVMType(t);
return ConstantInt::get(t, value);
}
Value* FloatNode::codeGen(CodeGenContext* context) {
Type* t = Type::getFloatTy(*(context->getContext()));
setLLVMType(t);
return ConstantFP::get(t, value);
}
Value* StringNode::codeGen(CodeGenContext* context) {
Module* M = context->getModule();
LLVMContext& ctx = M->getContext(); // 千万别用Global Context
Constant* strConstant = ConstantDataArray::getString(ctx, value);
Type* t = strConstant->getType();
setLLVMType(t);
GlobalVariable* GVStr = new GlobalVariable(*M, t, true,
GlobalValue::InternalLinkage, strConstant, "");
Constant* zero = Constant::getNullValue(IntegerType::getInt32Ty(ctx));
Constant* indices[] = {zero, zero};
Constant* strVal = ConstantExpr::getGetElementPtr(GVStr, indices, true);
return strVal;
}这里最复杂的应该就属常量字符串了,首先,常量字符串要用ConstantDataArray::getString类型,然而,往往函数却不接收一个字符串类型的变量,你需要像C语言一样,将它的首地址作为参数传进去,记得我们之前写过的printf函数的定义么?第一个参数就是一个char*指针。
所以我们这里用一条语句,ConstantExpr::getGetElementPtr,对其取地址,indices是一个数组,第一个值是假设指针是个数组,取数组的第几位的地址,第二个值是假设指针指向的是一个结构体,取结构体中第几条元素的地址。
这里我们都传常量0就可以了。另外一个需要注意的是,这里取地址的常量0好像不能用int64类型,大概是数据范围太大怕越界吧,一般int32长的数组也够用了。之前我没注意,用int64,总出莫名其妙的问题。
附: Node类的完整实现
/*
* @Author: sxf
* @Date: 2015-09-22 19:21:40
* @Last Modified by: sxf
* @Last Modified time: 2015-11-01 21:05:14
*/
#include "Node.h"
#include <stdarg.h>
#include <stdio.h>
#include "nodes.h"
#include <iostream>
void Node::init() {
llvm_type = NULL;
next = child = NULL;
}
Node::Node() {
init();
}
Node::Node(Node* n) {
init();
addChildren(n);
}
Node::~Node() {
}
void Node::addChildren(Node* n) {
if (child == NULL) {
child = n;
} else {
child->addBrother(n);
}
}
void Node::addBrother (Node* n) {
Node* p = this;
while (p->next != NULL) {
p = p->next;
}
p->next = n;
}
void Node::print(int k) {
for (int i = 0; i < k; ++i)
printf(" ");
printSelf();
printf("\n");
Node* p = child; int t = 0;
while (p != NULL) {
p->print(k+1);
p = p->next;
++t;
}
if (t >= 3) printf("\n");
}
void Node::printSelf() {
printf("Node");
}
NodeType Node::getType() {
return node_t;
}
bool Node::isSingle() {
return next == NULL;
}
Node* Node::make_list(int num, ...) { va_list argp; Node* para = NULL; Node* ans = NULL; va_start( argp, num ); for (int i = 0; i < num; ++i) { para = va_arg( argp, Node* ); if (!para->isSingle()) para = new Node(para); if ( ans == NULL ) ans = para; else ans->addBrother(para); } va_end( argp ); return ans; } Node* Node::getList(Node* node) { if (!node->isSingle()) return new Node(node); return node; }
Type* Node::getLLVMType() {
return llvm_type;
}
void Node::setLLVMType(Type* t) {
llvm_type = t;
}
bool Node::isNode() {
return getType() == node_t;
}
bool Node::isIntNode() {
return getType() == int_node_t;
}
bool Node::isFloatNode() {
return getType() == float_node_t;
}
bool Node::isIDNode() {
return getType() == id_node_t;
}
bool Node::isStringNode() {
return getType() == string_node_t;
}
bool Node::isCharNode() {
return getType() == char_node_t;
}
std::string Node::getTypeName() {
switch (getType()) {
case node_t: return "Node";
case int_node_t: return "IntNode";
case string_node_t: return "StringNode";
case id_node_t: return "IDNode";
case char_node_t: return "CharNode";
case float_node_t: return "FloatNode";
}
}
std::string& Node::getStr() {
if (this->isStringNode()) {
StringNode* string_this = (StringNode*)this;
return string_this->getStr();
}
if (this->isIDNode()) {
IDNode* string_this = (IDNode*)this;
return string_this->getStr();
}
std::cerr << "getStr() - 获取字符串错误, 该类型不正确:" << getTypeName() << std::endl;
exit(1);
}

相关文章推荐
- Windows Clang开发环境备忘
- 浅谈汇编器、编译器和解释器
- 让我们做个简单的解释器(三)
- 让我们做个简单的解释器(一)
- 架构纵横谈之二 ---- 架构的模式与要点
- 用 350 行代码从零开始,将 Lisp 编译成 JavaScript
- BS项目中的CSS架构_仅加载自己需要的CSS
- 关于三种主流WEB架构的思考
- Android操作系统的架构设计分析
- w3c技术架构介绍
- linux学习笔记 linux目录架构
- 基于JSP编译器基本语法的使用详解
- C#命令行编译器配置方法
- Java虚拟机JVM性能优化(二):编译器
- mysql数据库应付大流量网站的的3种架构扩展方式介绍
- 从零开始搭建MySQL MMM架构
- C/S和B/S两种架构的概念、区别和联系
- AngularJS HTML编译器介绍