8 - 机器学习中的噪音与错误(Noise and Error)
2015-11-10 10:25
232 查看
噪音与概率目标函数(Noise and Probalistic Target)
实际应用中的数据基本都是有干扰的:
还是用信用卡发放问题举例子:

标记错误:应该发卡的客户标记成不发卡,或者两个数据相同的客户一个发卡一个不发卡;
输入错误:用户的数据本身就有错误,例如年收入少写一个0、性别写反了什么的。
-------------------------------------------------------------------------------------------------------------
VC Bound怎么在有噪音的数据下工作?
还记得那个从罐子里拿小球的试验不?
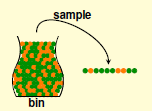
之前我们规定凡是 h(x)≠f(x) 的数据(小球),就把他漆成橘色,否则绿色。橘色小球在所有小球中占据的比重就是错误率。
但是现在有干扰了,一条数据可能有h(x)≠f(x),但我们错误的把它漆成了绿色,或者反之。这影响了对错误率的判断。如果我们知道在单条数据上犯错的概率,对于每个x,其输出y服从如下分布:
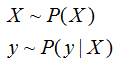
把 P(y|X) 叫做目标分布(Target Distribution),有它可以得到 mini target function f(x)。
举例说明,如果有目标分布:
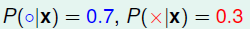
得到圈圈的概率比较大,所以他的 mini target function f(x)= "圈圈"。
在确定性的情况下,实际上就是犯错的概率为0:
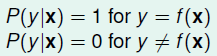
错误衡量(Error Measure)
有两种错误计算方法:
第一种叫0/1错误,只要【预测≠目标】则认为犯错,通常用于分类;
第二种叫平方错误,它衡量【预测与目标之间的距离】,通常用于回归。
举例说明:

有三种可能的输出:1、2、3,对应的概率分别为 0.2, 0.7, 0.1。
如果用0/1错误衡量,对于任一输入,输出2犯错概率最低,所以 mini target f(x) = 2;
如果用平方错误衡量, 对于任一输入,输出1.9犯错概率最低,所以 mini
target f(x) = 1.9。
错误加权
以指纹识别为例:
目标函数识别指纹以区分合法身份与非法身份,这里的错误是0/1错误。一种是false reject叫错误拒绝,即本来合法的识别成了非法;另一种叫false accept叫错误接受,即本来非法的识别成了合法。
想象一个应用场景,一家超市通过指纹鉴别会员,如果是会员就给一定折扣。如果某个会员被错误拒绝了,他很可能因为没有享受到本该拥有的权益而愤怒并拒绝再来这家超市,而超市将失去一个稳定的客源;如果某个普通顾客被错误接受了,超市给了他一些折扣,并无太大损失,这名顾客可能因为占了小便宜而经常光顾这家超市。
所以,false reject与false accept在这里有不同的cost,它们对超市造成的损失不同,所以我们需要给他们加上不同的权重,以便学习算法在选择近似函数时对错误地衡量有所偏重:

同理,CIA的绝密资料库只能向有权限的人敞开,如果通过指纹核实人员身份,false accept的代价就变得非常大,这意味着一个没有权限的人接触到了国家机密!不能忍啊,于是工程师给false accept加了一个巨大的权重,训练时如果出现false accept,这个备选函数基本是要被毙掉了。

而如果是false reject,无所谓啦,最多被上司骂一顿而已。
加权分类模型
继续CIA问题,于是它的错误计算就变成:
给这个特殊的E-in换个名字:
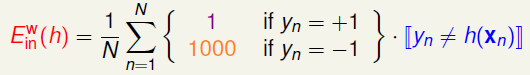
W上标代表weighted。
数学家们想了个办法来改造数据,以体现权重的影响:

比如false accept( 将-1识别成+1 )权重为1000,我们将训练数据中所有标记为-1的点复制1000次,如果近似函数在这些点上犯错,将会有1000倍的惩罚。这样问题就被转化为无权重问题:
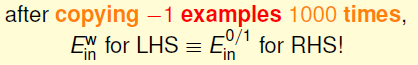
并且我们已经知道Pokect算法可以解决无权重问题。
其实在应用中我们也不会真的把某些数据复制1000次,我们只需在计算Error时,将权重高的数据被拜访的概率提高1000倍即可,这与复制是等效的。
不过,如果你是遍历整个测试集(不是抽样)来计算错误,就没必要修改拜访概率了,只需给相应的错误乘上它们的权重再相加并除以N即可。
到现在为止,我们拓展了VC Bound,它在多元分类问题上同样成立!

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 初识机器学习算法有哪些?
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 自动编程体系设想(一)
- 自动编程体系设想(一)
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 常用的分类评估--基于R语言
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 关于机器学习的学习笔记(二):决策树算法