Spark GraphX(一)
2015-11-08 19:29
597 查看
1.基础
Spark中属性图是由VertexRDD和EdgeRDD两个参数构成的。其中,每个vertex由一个唯一的64位长的标识符(VertexId)作为key。同时,属性图也和RDD一样,是不可变的、分布式的、可容错的。属性图Graph的定义如下:abstract class Graph[VD, ED]{
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED
val triplets: RDD[EdgeTriplet[VD, ED]]]
}即Graph中包含了三个属性点集、边集、triplets集(三元组)。可以用图形象的表示为:

Vertices:由VertexId(Long类型)、attribute(属性描述或距离)构成。如,(3L, ("San Francisco", "CA")),(1L, 10)。
Edges:由srcId(起始结点VertexId)、dstId(终结点VertexId)、attribute(边的权值)构成。如,Edge(1L, 2L, 20)
Triplets:由srcId、srcAttr(起始Vertex)和dstId、dstAttr(终止Vertex),以及attr构成。如,((1, (Santa Clara, CA)), (2, (Fremont, CA)), 20)
2.操作符
正如RDDs有基本的操作map、filter和reduceByKey一样,Graph也有基本操作,这些操作采用用户自定义的函数并产生包含转换特征和结构的新图。定义在Graph中的核心操作时经过优化的实现,表示核心操作的组合的便捷操作定义在GraphOps中。因为Scala的隐式转换,定义在GraphOps中的操作可以作为Graph的成员自动使用。例如,初始化Graph的时候调用mapVertices:val initialGraph = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
Graph有很多操作,具体的可以参考Spark API。
3.Pregel
在GraphX中,更高级的Pregel操作是一个约束到图拓扑的批量同步(bulk-synchronous)并行消息抽象。Pregel操作者执行一系列的超级步骤(super steps),在这些步骤中,顶点从之前的超级步骤中接收进入(inbound)消息的总和,为顶点属性计算一个新的值,然后在以后的超级步骤中发送消息到邻居顶点。不像Pregel而更像GraphLab,消息作为一个边为三元组的函数被并行计算,消息计算既访问了源顶点特征也访问了目的顶点特征。在super steps中,没有收到消息的顶点被跳过。当没有消息遗留时,Pregel操作停止迭代并返回最终的图。与更标准的Pregel实现不同的是,GraphX中的顶点仅仅能发送消息给邻居顶点,并利用用户自定义的消息函数构造消息。这些限制允许在GraphX进行额外的优化。
Pregel有两个参数列表(graph.pregel(argslist)(argslist))。第一个参数列表包含配置参数初始消息、最大迭代次数、发送消息的边的方向(默认是沿边的方向)。第二个参数列表包含用户自定义的函数用来接收消息(vprog)、计算消息(sendMsg)、合并消息(mergeMsg)。
而Pregel处理的数据流(Dataflow)是:1.每一次迭代计算从计算指定点的邻结点和出边开始;2.使用triplets视图,重新计算每个triplet的消息,然后在终结点合并消息;3.在所有顶点,信息被vertex programs收到。在伯克利的论文《GraphX: Graph Processing in a Distributed Dataflow Framework》中,关于Graph计算的数据流的描述如下:
Each iteration begins by executing the join stage to bind active vertices with their outbound edges. Using the triplets view, messages are computed along each triplet in a map stage and then aggregated at their destination vertex in a groupby stage.
Finally, the messages are received by the vertex programs in a map stage over the vertices.
在Google关于Pregel的论文《Pregel: A System for Large-Scale Graph Processing》中,举了一个图形化的例子描述如下:
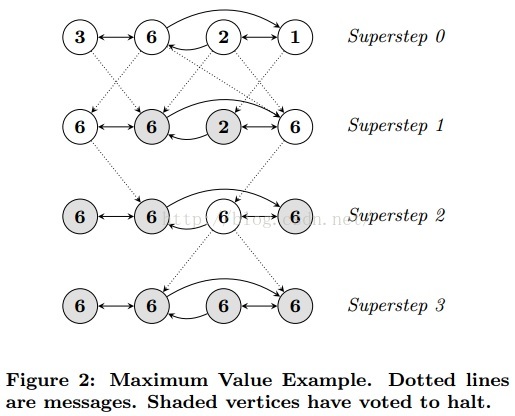
pregel的定义如下:
def pregel[A: ClassTag]( initialMsg: A, maxIterations: Int = Int.MaxValue, activeDirection: EdgeDirection = EdgeDirection.Either)( vprog: (VertexId, VD, A) => VD, sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)], mergeMsg: (A, A) => A)
例一,我们可以用Pregel操作表达计算单源最短路径( single source shortest path)。
import org.apache.spark.graphx._
// Import random graph generation library
import org.apache.spark.graphx.util.GraphGenerators
// A graph with edge attributes containing distances
val graph: Graph[Int, Double] = GraphGenerators.logNormalGraph(sc, numVertices = 100).mapEdges(e => e.attr.toDouble)
val sourceId: VertexId = 42 // The ultimate source
// Initialize the graph such that all vertices except the root have distance infinity.
val initialGraph = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
val sssp = initialGraph.pregel(Double.PositiveInfinity)(
vprog = (id, dist, newDist) => math.min(dist, newDist), // Vertex Program
sendMsg = triplet => { // Send Message
if (triplet.srcAttr + triplet.attr < triplet.dstAttr) {
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else {
Iterator.empty
}
},
mergeMsg = (a,b) => math.min(a,b) // Merge Message
)
println(sssp.vertices.collect.mkString("\n"))例二,用Pregel实现广度优先遍历(Breadth First Search)
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.graphx.GraphLoader
/**
* @author Administrator
*/
object BFS {
def main(args: Array[String]): Unit = {
if(args.length != 4){
System.err.println("Usage: BFS <input file> <output file> <source vertex> <iteration number>")
System.exit(1)
}
val sAllTime = System.currentTimeMillis()
val conf = new SparkConf()
val sc = new SparkContext(conf)
val fname = args(0)
val outPath = args(1)
val srcVertex = args(2).toInt
val numIter = args(3).toInt
val sLoadTime = System.currentTimeMillis()
val graphFile = GraphLoader.edgeListFile(sc, fname).cache()
val eLoadTime = System.currentTimeMillis()
val graph = graphFile.mapVertices((id, _) => if (id == srcVertex) 0.0 else Double.PositiveInfinity)
val sComTime = System.currentTimeMillis()
val bfs = graph.pregel(Double.PositiveInfinity, numIter)(
vprog = (id, attr, msg) => math.min(attr, msg),
sendMsg = triplet => {
if (triplet.srcAttr != Double.PositiveInfinity) {
Iterator((triplet.dstId, triplet.srcAttr+1))
}
else {
Iterator.empty
}
},
mergeMsg = (a,b) => math.min(a,b) )
val eComTime = System.currentTimeMillis()
//bfs.vertices.saveAsTextFile(outPath)
sc.stop()
val eAllTime = System.currentTimeMillis()
println("Load time: " + (eLoadTime - sLoadTime) / 1000)
println("Compute time: " + (eComTime - sComTime) / 1000)
println("Total time: " + (eAllTime - sAllTime) / 1000)
}
}

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Spark中将对象序列化存储到hdfs
- Spark初探
- Spark Streaming初探
- 搭建hadoop/spark集群环境
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark 性能相关参数配置详解-任务调度篇
- 基于spark1.3.1的spark-sql实战-01
- 基于spark1.3.1的spark-sql实战-02
- 在 Databricks 可获得 Spark 1.5 预览版
- spark standalone模式 zeppelin安装
- Apache Spark 1.5.0正式发布
- Tachyon 0.7.1伪分布式集群安装与测试
- spark取得lzo压缩文件报错 java.lang.ClassNotFoundException
- tachyon与hdfs,以及spark整合
- hive on spark 编译