Python: Soft_max 分类器
2015-11-08 18:44
666 查看
我们可以建立如下的loss function:
Li=−log(pyi)=−log⎛⎝efyi∑jefj⎞⎠
L=1N∑iLi+12λ∑k∑lW2k,l
下面我们推导loss对W,b的偏导数,我们可以先计算loss对f的偏导数,利用链式法则,我们可以得到:
∂Li∂fk=∂Li∂pk∂pk∂fk∂pi∂fk=pi(1−pk)i=k∂pi∂fk=−pipki≠k∂Li∂fk=−1pyi∂pyi∂fk=(pk−1{yi=k})
进一步,由f=XW+b,可知∂f∂W=XT,∂f∂b=1,我们可以得到:
ΔW=∂L∂W=1N∂Li∂W+λW=1N∂Li∂p∂p∂f∂f∂W+λWΔb=∂L∂b=1N∂Li∂b=1N∂Li∂p∂p∂f∂f∂bW=W−αΔWb=b−αΔb
下面是用Python实现的soft max 分类器,基于Python 2.7.9, numpy, matplotlib.
代码来源于斯坦福大学的课程: http://cs231n.github.io/neural-networks-case-study/
基本是照搬过来,通过这个程序有助于了解python的语法。
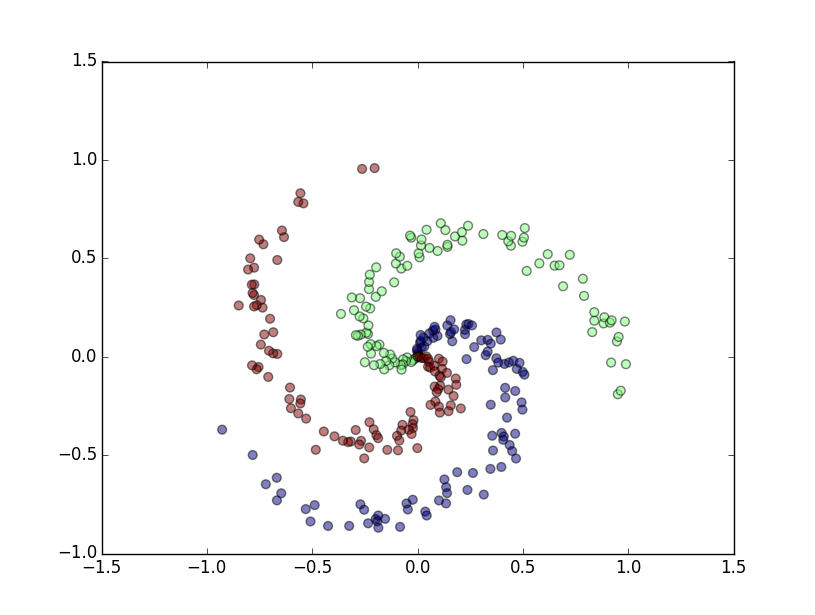
生成的随机数据
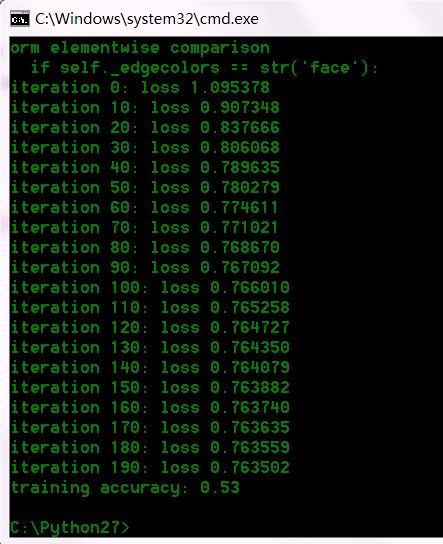
运行结果
Li=−log(pyi)=−log⎛⎝efyi∑jefj⎞⎠
L=1N∑iLi+12λ∑k∑lW2k,l
下面我们推导loss对W,b的偏导数,我们可以先计算loss对f的偏导数,利用链式法则,我们可以得到:
∂Li∂fk=∂Li∂pk∂pk∂fk∂pi∂fk=pi(1−pk)i=k∂pi∂fk=−pipki≠k∂Li∂fk=−1pyi∂pyi∂fk=(pk−1{yi=k})
进一步,由f=XW+b,可知∂f∂W=XT,∂f∂b=1,我们可以得到:
ΔW=∂L∂W=1N∂Li∂W+λW=1N∂Li∂p∂p∂f∂f∂W+λWΔb=∂L∂b=1N∂Li∂b=1N∂Li∂p∂p∂f∂f∂bW=W−αΔWb=b−αΔb
下面是用Python实现的soft max 分类器,基于Python 2.7.9, numpy, matplotlib.
代码来源于斯坦福大学的课程: http://cs231n.github.io/neural-networks-case-study/
基本是照搬过来,通过这个程序有助于了解python的语法。
import numpy as np import matplotlib.pyplot as plt N = 100 # number of points per class D = 2 # dimensionality K = 3 # number of classes X = np.zeros((N*K,D)) #data matrix (each row = single example) y = np.zeros(N*K, dtype='uint8') # class labels for j in xrange(K): ix = range(N*j,N*(j+1)) r = np.linspace(0.0,1,N) # radius t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] y[ix] = j # print y # lets visualize the data: plt.scatter(X[:,0], X[:,1], s=40, c=y, alpha=0.5) plt.show() #Train a Linear Classifier # initialize parameters randomly W = 0.01 * np.random.randn(D,K) b = np.zeros((1,K)) # some hyperparameters step_size = 1e-0 reg = 1e-3 # regularization strength # gradient descent loop num_examples = X.shape[0] for i in xrange(200): # evaluate class scores, [N x K] scores = np.dot(X, W) + b # compute the class probabilities exp_scores = np.exp(scores) probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K] # compute the loss: average cross-entropy loss and regularization corect_logprobs = -np.log(probs[range(num_examples),y]) data_loss = np.sum(corect_logprobs)/num_examples reg_loss = 0.5*reg*np.sum(W*W) loss = data_loss + reg_loss if i % 10 == 0: print "iteration %d: loss %f" % (i, loss) # compute the gradient on scores dscores = probs dscores[range(num_examples),y] -= 1 dscores /= num_examples # backpropate the gradient to the parameters (W,b) dW = np.dot(X.T, dscores) db = np.sum(dscores, axis=0, keepdims=True) dW += reg*W #regularization gradient # perform a parameter update W += -step_size * dW b += -step_size * db # evaluate training set accuracy scores = np.dot(X, W) + b predicted_class = np.argmax(scores, axis=1) print 'training accuracy: %.2f' % (np.mean(predicted_class == y))
生成的随机数据
运行结果

相关文章推荐
- python之模块colorsys颜色转换模块 暂不了解
- python爬虫工具及最佳实践
- vim 创建Python脚本时候自动补全解释器和编码方法
- Python初始基本数据类型
- python之模块cmath
- python之模块chunk,了解即可
- 基于python2【重要】怎么自行搭建简单的web服务器
- 业余时间没事做,可以试试这些......
- Python学习笔记
- python学习记——爬糗事百科
- NumPy-快速处理数据--ufunc运算--广播--ufunc方法
- 《用Python玩转数据》第1周学习笔记(Part 1)
- Python中定义字符串和修改字符串的原理
- 【重要】python之模块CGI 通用网关接口
- Python pickle 的 dump() & load()
- python之模块calendar(汇集了日历相关的操作)
- python列表相乘函数map函数
- python之模块base64
- 为Python添加默认模块搜索路径
- Python __name__ 和 __main__