赫夫曼树与赫夫曼编码
2015-11-07 17:15
423 查看
1概念
路径:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。路径长度:路径上的分支数目。
树的路径长度:从树根到每一个结点的路径长度之和。
结点的带权路径长度:从该结点到树根之间的路径长度与结点上权的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和,通常记作WPL。

赫夫曼树或最优二叉树:假设有n个权值{W1,W2,…,Wn},试构造一颗有n个叶子结点的二叉树,每个叶子结点带权为Wi,则其中带权路径长度WPL最小的二叉树称为赫夫曼树。
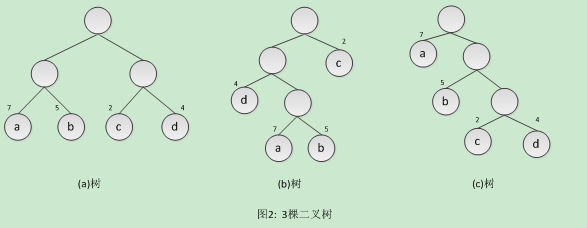
示例:如图2,有3棵二叉树,都有4个叶子结点a,b,c,d,分别带权7,5,2,4,它们的带权路径长度分别为:
(a)WPL = 7*2 + 5*2 + 2*2 + 4*2 = 36
(b)WPL = 7*3 + 5*3 + 2*1 + 4*2 = 46
(c)WPL = 7*1 + 5*2 + 2*3 + 4*3 = 35
其中,(c)树的WPL最小,它便是赫夫曼树,即其带权路径长度在所有带权为7、5、2、4的4个叶子结点的二叉树中居最小。
2构造赫夫曼树
利用赫夫曼最早给出的一个带有一般规律的算法,即赫夫曼算法。步骤如下:(1)根据给定的n个权值{W1,W2,…,
Wn}构成n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为Wi的根结点,其左右子树均为空。
(2)在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
(3)在F中删除这两棵树,同事将新得到的二叉树加入F中。
(4)重复(2)和(3),直到F只含一棵树为止。这棵树便是赫夫曼树。
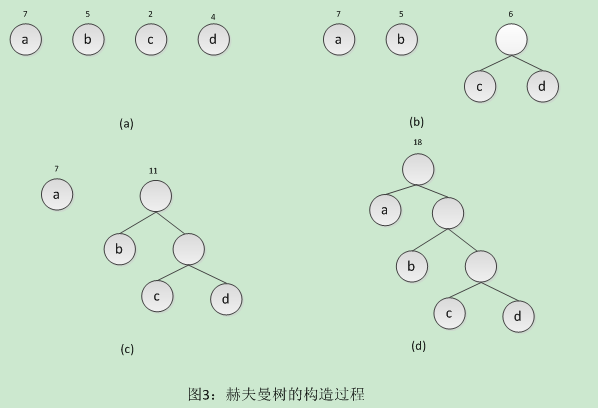
示例:如图3,展示了赫夫曼树的构造过程。
3赫夫曼编码
赫夫曼编码是赫夫曼树的应用,通常采用前缀编码,使得解码时不会产生混淆。前缀编码:任一个字符的编码都不是另一个字符的前缀,这种编码称为前缀编码。
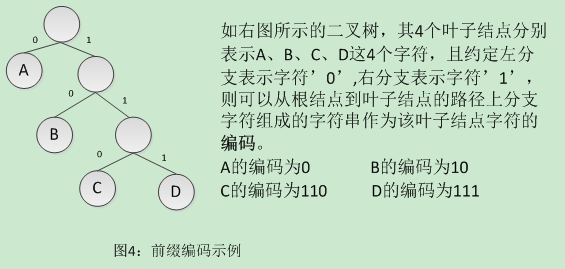
赫夫曼编码:从叶子出发走一条从叶子到根的路径,如字符C所在的叶子到根结点的路径为字符串011,再将所得的字符串反转得到110,便是该字符C的编码。
赫夫曼译码:从根出发走一条从根到叶子的路径,如根据字符C的编码110,从根出发,按字符’0’或’1’确定找左孩子或右孩子,直至叶子结点,便求得该编码字符串对应的字符。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 8
typedef struct
{
char leaf; /*结点的字符*/
unsigned int weight; /*结点的权重*/
}leaf_val_wgh_t;
/*赫夫曼树结点结构*/
typedef struct
{
char leaf; /*叶子结点的值*/
unsigned int weight; /*结点的权重*/
unsigned int parent,lchild,rchild;
}htnode, huffman_tree_t;
typedef char huffman_code_t;/*赫夫曼编码表类型*/
void select_min(huffman_tree_t *HT, int n, int *s1, int *s2)
{
int i,j;
int idx1, idx2;
int min1, min2;
/*先选择一个parent为0的权重作为min1*/
for (i = 1; i <=n; i++)
{
if (HT[i].parent == 0)
{
min1 = HT[i].weight;
idx1 = i;
break;
}
}
/*选出最小的min1*/
for (j = 1; j<=n; j++)
{
if (HT[j].weight < min1 && HT[j].parent == 0)
{
min1 = HT[j].weight;
idx1 = j;
}
}
/*i != idx1 是为了避免两个较小的权重却相等的情况出现时,idx2 等于idx1*/
for (i = 1; i <=n; i++)
{
if (HT[i].parent == 0 && i != idx1)
{
min2 = HT[i].weight;
idx2 = i;
break;
}
}
for (j = 1; j<=n; j++)
{
if (HT[j].weight < min2 && HT[j].parent == 0 && j != idx1)
{
min2 = HT[j].weight;
idx2 = j;
}
}
*s1 = idx1;
*s2 = idx2;
return ;
}
/*构造赫夫曼树*/
void huffman_tree(huffman_tree_t **HT, leaf_val_wgh_t lvw[], int n)
{
int i;
int m;/*赫夫曼树结点总数*/
int s1,s2;
huffman_tree_t *p = NULL;
huffman_tree_t *ht = NULL;
if (n <= 1)
{
return ;
}
m = 2*n - 1;
*HT = (huffman_tree_t *)malloc((m+1) * sizeof(huffman_tree_t));/*0号单元未用*/
if (*HT == NULL)
{
return ;
}
/*初始化*/
for (i = 1, p = *HT+1; i <= n; ++i, ++p, ++lvw)
{
p->leaf = lvw->leaf;
p->weight = lvw->weight;
p->parent = 0;
p->lchild = 0;
p->rchild = 0;
}
for (; i <= m; ++i)
{
p->leaf = 0;
p->weight = 0;
p->parent = 0;
p->lchild = 0;
p->rchild = 0;
}
ht = *HT;
/*构造赫夫曼树*/
for (i = n + 1; i <= m; i++)
{
/*在HT[1...i-1]选择parent为0且weight最小的两个结点,其序号分别为s1和s2*/
select_min(ht, i-1, &s1, &s2);
ht[s1].parent = i; ht[s2].parent = i;
ht[i].lchild = s1; ht[i].rchild = s2;
ht[i].weight = ht[s1].weight + ht[s2].weight;
}
return ;
}
/*赫夫曼编码*/
void huffman_encoding(huffman_tree_t *HT, huffman_code_t **HC, int n)
{
int i,j,k,start;
huffman_code_t *cd = (huffman_code_t *)malloc(n*sizeof(char));
if (cd == NULL) return ;
cd[n-1] = '\0';
for (i = 1; i <= n; i++)
{
start = n - 1;
for (j = i, k = HT[i].parent; k != 0; j = k, k = HT[k].parent)
{
if (HT[k].lchild == j)
{
cd[--start] = '0';
}
else
{
cd[--start] = '1';
}
}
HC[i] = (char *)malloc((n-start)*sizeof(char));
strcpy(HC[i], &cd[start]);
}
free(cd);
return ;
}
/*赫夫曼译码*/
void huffman_decoding(huffman_tree_t *HT, huffman_code_t **HC, char *ch, int n)
{
int i,j,k,start;
huffman_code_t *cd = NULL;
huffman_tree_t *root = NULL;
huffman_tree_t *node1 = NULL;
huffman_tree_t *node2 = NULL;
int cd_len;
/*找到根结点*/
for (i = 1; i<=2*n-1; i++)
{
if (HT[i].parent == 0)
{
root = &HT[i];
break;
}
}
for (i = 1; i <= n; i++)
{
cd = HC[i];
cd_len = strlen(cd);
node1 = root;
for (j = 0; j < cd_len; j++)
{
if (cd[j] == '0')
{
node2 = &HT[node1->lchild];
}
else
{
node2 = &HT[node1->rchild];
}
node1 = node2;
}
ch[i] = node1->leaf;
}
return ;
}
int main()
{
int i;
char ch[N+1];/*译码时用来存放字符*/
huffman_tree_t *HT = NULL; /*赫夫曼树*/
huffman_code_t *HC[N+1] = {NULL,};/*赫夫曼编码表*/
leaf_val_wgh_t lvw
= {{'A', 5},{'B', 29},{'C', 7},{'D', 8},{'E', 14},{'F', 23},{'G', 3},{'H', 11}};
/*构建赫夫曼树*/
huffman_tree(&HT, lvw, N);
/*赫夫曼编码*/
huffman_encoding(HT, HC, N);
printf("************赫夫曼编码************\n");
printf("字符 -> 编码\n");
for (i = 1; i<=N; i++)
{
printf("%3c -> %s\n", HT[i].leaf, HC[i]);
}
/*赫夫曼译码*/
huffman_decoding(HT, HC, ch, N);
printf("************赫夫曼译码************\n");
printf("编码 -> 字符\n");
for (i = 1; i<=N; i++)
{
printf("%-4s -> %2c\n", HC[i], ch[i]);
}
return 0;
}输出:
************赫夫曼编码************
字符 -> 编码
A -> 0001
B -> 10
C -> 1110
D -> 1111
E -> 110
F -> 01
G -> 0000
H -> 001
************赫夫曼译码************
编码 -> 字符
0001 -> A
10 -> B
1110 -> C
1111 -> D
110 -> E
01 -> F
0000 -> G
001 -> H

相关文章推荐
- 数据结构——赫夫曼编码
- 【数据结构与算法】Huffman树&&Huffman编码(附完整源码)
- 赫夫曼编码
- 赫夫曼树 赫夫曼编码
- 赫夫曼树和赫夫曼编码
- 赫夫曼树和赫夫曼编码
- 基于Huffman编码的Ascii文件压缩算法
- 数据结构_赫夫曼树、赫夫曼编码及其应用(数据的压缩和解压)
- 18. 树(7)
- 树的基本知识点
- 数据结构:树
- Huffman树及Huffman编码
- 《算法导论》学习分享——16. 贪心算法
- 赫夫曼树介绍与实现
- 贪心算法 赫夫曼编码 使用小顶堆性质 python 代码实现 示例
- AndroidL 开机展示Keyguard锁屏机制初探
- 初学Android,字符串,数字,尺寸,数组资源(十二)
- MangoDB环境搭建与学习
- ListView的使用
- 自定义布局控件