SOM学习笔记1
2015-10-31 13:20
211 查看
SOM学习笔记小编打算写两篇,内容来自小编前阶段在工作要解决的预警产品质量在多个ATE上走低的问题。第一篇从理论的角度介绍SOM的网络模型、学习算法,第二篇从应用的角度以demo的形式展示实际的应用。
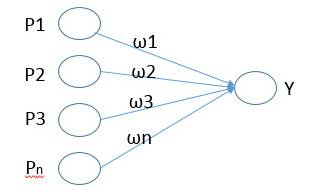
假设输入信息为n维向量,该向量与权值向量连接,输出到输出神经元Y中,Y采用硬限幅函数作为传递函数,限定输出为1和0
内星模型训练的目标使得神经元Y只对某些特定的输入向量产生兴奋,即在Y出的神经元输出为1
通过学习速率η对权值进行调整,当Y=1时,权值进行调整,当Y=0时,权值不做调整,最终得到的网络权值趋近于各输入向量的平均值
初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X’ = x/||x||
ω’i(k)= ωi(k)/||ωi(k)||
||x||和||ωi(k)||分别为输入向量和权值向量的欧几里得范数
将样本输入网络:样本与权值向量做内积,内积值最大的输出神经元赢得竞争,记为获胜神经元
更新权值:对获胜的神经元拓扑邻域内的神经元采用内星规则进行更新
ω(k+1)= ω(k)+ η(x- ω(k))
更新学习速率η及拓扑邻域,并对学习后的权值重新归一化
判断是否收敛。如果中心改变很小或达到预设的迭代次数,结束算法
表示的结果非常容易理解,这点将在第二篇demo中看到
实现起来比较简单
缺点
计算复杂度高,对相似性的度量非常敏感
不能应用存在缺失值的数据集
1.SOM是什么
SOM英文全拼是Self-Organizing Maps,中文一般译作自组织映射网络,它是神经网络的一种,由kohonen提出,属于非监督式学习,它模仿人脑神经元对信息的处理方式,通过自身训练,自动对输入的模式进行聚类。2.SOM网络模型
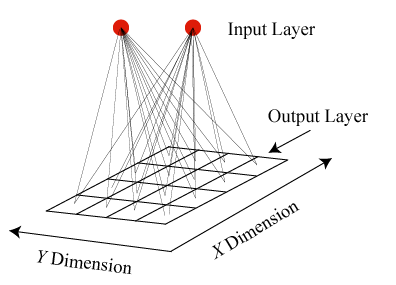
SOM网络有两层,分别是InputLayer和OutputLayer。InputLayer与OutputLayer通过权值相连,InputLayer即输入层,其输入一般为高维度向量。OutputLayer的神经元一般放置在二维网格中,输出层近邻的神经元也通过权值连接3.内星学习规则
SOM是基于内星学习规则而来的,有必要学习下该规则:假设输入信息为n维向量,该向量与权值向量连接,输出到输出神经元Y中,Y采用硬限幅函数作为传递函数,限定输出为1和0
内星模型训练的目标使得神经元Y只对某些特定的输入向量产生兴奋,即在Y出的神经元输出为1
通过学习速率η对权值进行调整,当Y=1时,权值进行调整,当Y=0时,权值不做调整,最终得到的网络权值趋近于各输入向量的平均值
4.SOM学习算法
设定变量:X=[x1,x2,x3,…,xm]为输入样本,每个样本为m维向量。ωi(k)=[ωi1(k), ω i2(k),…,ωin(k)]为第i个输入节点与输出神经元之间的权值向量初始化:权值使用较小的随机值进行初始化,并对输入向量和权值做归一化处理
X’ = x/||x||
ω’i(k)= ωi(k)/||ωi(k)||
||x||和||ωi(k)||分别为输入向量和权值向量的欧几里得范数
将样本输入网络:样本与权值向量做内积,内积值最大的输出神经元赢得竞争,记为获胜神经元
更新权值:对获胜的神经元拓扑邻域内的神经元采用内星规则进行更新
ω(k+1)= ω(k)+ η(x- ω(k))
更新学习速率η及拓扑邻域,并对学习后的权值重新归一化
判断是否收敛。如果中心改变很小或达到预设的迭代次数,结束算法
5.SOM的优缺点
优点表示的结果非常容易理解,这点将在第二篇demo中看到
实现起来比较简单
缺点
计算复杂度高,对相似性的度量非常敏感
不能应用存在缺失值的数据集

相关文章推荐
- Some Information in Study
- MATLAB 自编3*3中值滤波(含边缘)
- 51nod 1393 0和1相等串 (连续区间)
- 周六干点儿啥
- line
- Android仿微信通通讯录
- oracle监听开启trace file
- unity3d 获取系统硬件信息
- HDU 2864 Repository 字典树
- 程序读取特定目录下的字符数
- 共用体(联合体)简介及在大小端判断的巧妙运用
- 程序读取特定目录下的字符数
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
- 牛逼的架构 vs ‘牛逼’ 的人生
- 图学java基础篇之集合工具
- coderforce A. Case of the Zeros and Ones
- LeetCode(155) Min Stack
- cocos2dx 苹果5分辨率 适配错误
- [转]SQL注入攻防入门详解
- LeetCode(155) Min Stack