数据的归一化
2015-10-27 15:35
239 查看
【转】:http://www.cnblogs.com/LBSer/p/4440590.html
机器学习模型被互联网行业广泛应用,如排序(参见:排序学习实践)、推荐、反作弊、定位(参见:基于朴素贝叶斯的定位算法)等。一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?很多同学并未搞清楚,维基百科给出的解释:1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。下面我简单扩展解释下这两点。
斯坦福机器学习视频做了很好的解释:https://class.coursera.org/ml-003/lecture/21
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。

一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
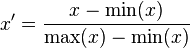
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
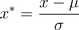
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等
需要说明的事并不是任何问题都必须事先把原始数据进行规范化 , 也就是数据规范化这一步并不是必须要做的 , 要具体问题具体看待 , 测试表明有时候规范化后的预测准确率比没有规范化的预测准确率低很多 . 就最大最小值法而言 , 当你用这种方式将原始数据规范化后 , 事实上意味着你承认了一个假设就是测试数据集的每一模式的所有特征分量的最大值 ( 最小值 ) 不会大于 ( 小于 ) 训练数据集的每一模式的所有特征分量的最大值 ( 最小值 ), 但这条假设显然过于强 , 实际情况并不一定会这样 . 使用平均数方差法也会有同样类似的问题 . 故数据规范化这一步并不是必须要做的 , 要具体问题具体看待 .
机器学习模型被互联网行业广泛应用,如排序(参见:排序学习实践)、推荐、反作弊、定位(参见:基于朴素贝叶斯的定位算法)等。一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?很多同学并未搞清楚,维基百科给出的解释:1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。下面我简单扩展解释下这两点。
1 归一化为什么能提高梯度下降法求解最优解的速度?
斯坦福机器学习视频做了很好的解释:https://class.coursera.org/ml-003/lecture/21如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
2 归一化有可能提高精度
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
3 归一化的类型
1)线性归一化
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
2)标准差标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
3)非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等需要说明的事并不是任何问题都必须事先把原始数据进行规范化 , 也就是数据规范化这一步并不是必须要做的 , 要具体问题具体看待 , 测试表明有时候规范化后的预测准确率比没有规范化的预测准确率低很多 . 就最大最小值法而言 , 当你用这种方式将原始数据规范化后 , 事实上意味着你承认了一个假设就是测试数据集的每一模式的所有特征分量的最大值 ( 最小值 ) 不会大于 ( 小于 ) 训练数据集的每一模式的所有特征分量的最大值 ( 最小值 ), 但这条假设显然过于强 , 实际情况并不一定会这样 . 使用平均数方差法也会有同样类似的问题 . 故数据规范化这一步并不是必须要做的 , 要具体问题具体看待 .

相关文章推荐
- 026.While 循环语句
- setTag()
- 开园了,将以此记录个人web前端之路
- 【句柄和指针】
- j2ee学习struts2 笔记
- 面向对象编程中如何描述对象之间的关系?
- solr-5.3部署到tomcat
- Oracle数据库学习第一天
- 027.Do While 循环语句
- 利用fastjson进行json字符串与对象互转
- docker hub使用
- 028.For 循环
- linux 常用命令
- iOS9问题汇总
- 软件测试中条件覆盖,路径覆盖,语句覆盖,分支覆盖的区别
- 初学NDK
- iOS bundle id的作用
- 讯飞语音识别Android-Demo
- win8系统配置开发环境记录
- 030.For 循环代替 While 循环