Using HDInsight tools to optimize hive script
2015-10-26 12:31
330 查看
Hive job issue
Below is a hive script coming from TPC-DS and I hadsubmitted to Microsoft Azure HDInsight cluster for a long time (more than twohours), but it was stillin running status. Why it was so slow?
use tpcds_text_2;
set hive.execution.engine=tez;
select avg(ss_quantity)
,avg(ss_ext_sales_price)
,avg(ss_ext_wholesale_cost)
,sum(ss_ext_wholesale_cost)
from store_sales
,store
,customer_demographics
,household_demographics
,customer_address
,date_dim
where store.s_store_sk = store_sales.ss_store_sk
and store_sales.ss_sold_date_sk = date_dim.d_date_sk and date_dim.d_year = 2001
and((store_sales.ss_hdemo_sk=household_demographics.hd_demo_sk
and customer_demographics.cd_demo_sk = store_sales.ss_cdemo_sk
and customer_demographics.cd_marital_status = 'M'
and customer_demographics.cd_education_status = '4 yr Degree'
and store_sales.ss_sales_price between 100.00 and 150.00
and household_demographics.hd_dep_count = 3
)or
(store_sales.ss_hdemo_sk=household_demographics.hd_demo_sk
and customer_demographics.cd_demo_sk = store_sales.ss_cdemo_sk
and customer_demographics.cd_marital_status = 'D'
and customer_demographics.cd_education_status = 'Primary'
and store_sales.ss_sales_price between 50.00 and 100.00
and household_demographics.hd_dep_count = 1
) or
(store_sales.ss_hdemo_sk=household_demographics.hd_demo_sk
and customer_demographics.cd_demo_sk = ss_cdemo_sk
and customer_demographics.cd_marital_status = 'U'
and customer_demographics.cd_education_status = 'Advanced Degree'
and store_sales.ss_sales_price between 150.00 and 200.00
and household_demographics.hd_dep_count = 1
))
and((store_sales.ss_addr_sk = customer_address.ca_address_sk
and customer_address.ca_country = 'United States'
and customer_address.ca_state in ('KY', 'GA', 'NM')
and store_sales.ss_net_profit between 100 and 200
) or
(store_sales.ss_addr_sk = customer_address.ca_address_sk
and customer_address.ca_country = 'United States'
and customer_address.ca_state in ('MT', 'OR', 'IN')
and store_sales.ss_net_profit between 150 and 300
) or
(store_sales.ss_addr_sk = customer_address.ca_address_sk
and customer_address.ca_country = 'United States'
and customer_address.ca_state in ('WI', 'MO', 'WV')
and store_sales.ss_net_profit between 50 and 250
));Using HDInsight Tool to find Issue
In order to find the root cause for slow job, it isnecessary to know what the job was doing (blocked at somewhere). One option isto read job log, but it is not so intuitionistic. I prefer to using a morevisualtool. Microsoft HDInsight tools is the one I choose.
Using it, we can get below job execution graph
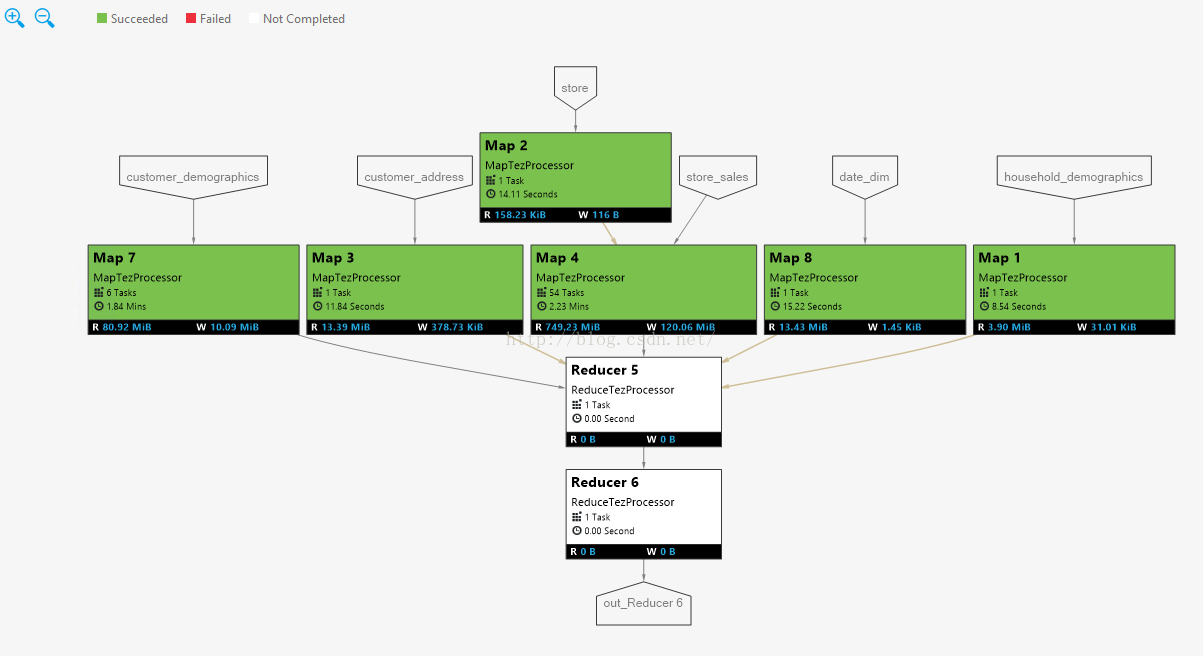
Through the graph, we can see all the map vertices hadfinished and the hive job is blocked at the Reducer5. Next, let us see what theexecution plan for Reducer 5. Double-click Reduce 5 node and below graphs
show up.

It is clear what execution plan for reducer5 is. Merge JoinàmapJoinà mapJoinà map
JoinàfilteràselectàGroupby. It is easy tounderstand what “four joins” do. Map7 and map4 do the merger join, then do mapjoin with map3,
map8, map1 (these three maps only several kb data, so do themap side join).
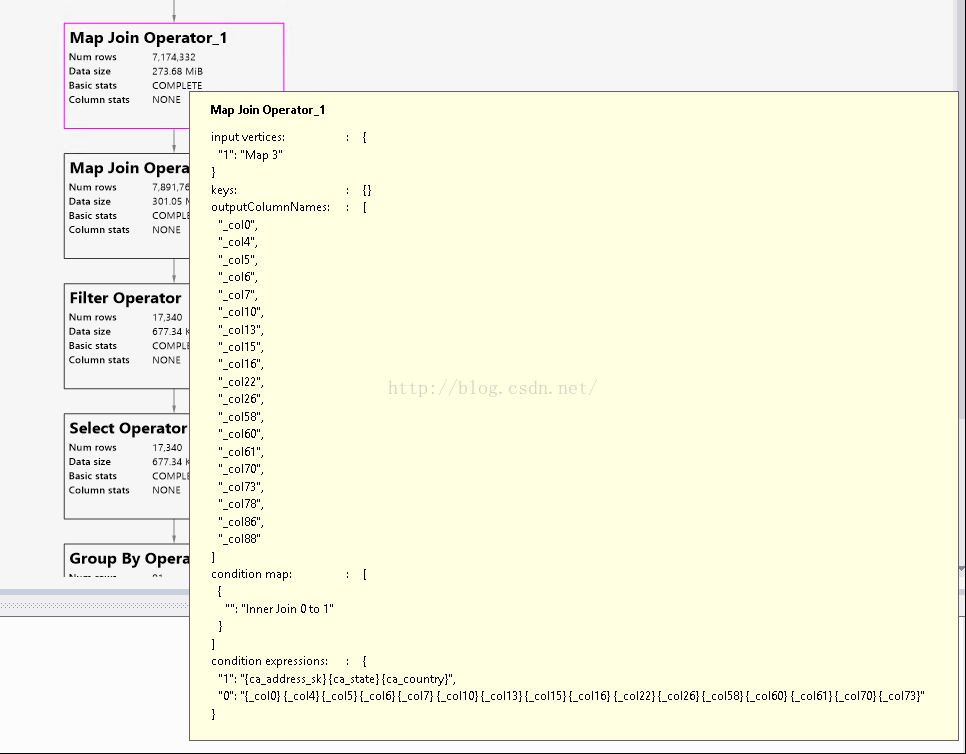
Putting mouse on three Mapside Join operator, I found somethingstrange, the mapside join for Map3 and Map1 are cross join because there nojoin keys for both of them. It is quite different with map side join
for Map8.
It can explain why the job are blocked here. Even you runthis job for two days, it will still stay here!

Optimize hive script
Though finding the reason for running slowly, it is alsoworth investigating why it generate such bad execution plan.Apache hive document
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins said
Version 0.13.0+: Implicit join notation Implicit join notation is supported starting with Hive 0.13.0 (see HIVE-5558). This allows the FROM clause to join a comma-separated list of tables, omitting the JOIN keyword. For example: SELECT * FROM table1 t1, table2 t2, table3 t3 WHERE t1.id = t2.id AND t2.id = t3.id AND t1.zipcode = '02535';
Go back to our hive script, it has the similar code withabove and should be an implicit join. But why some mapside joins are convertedto cross joins?
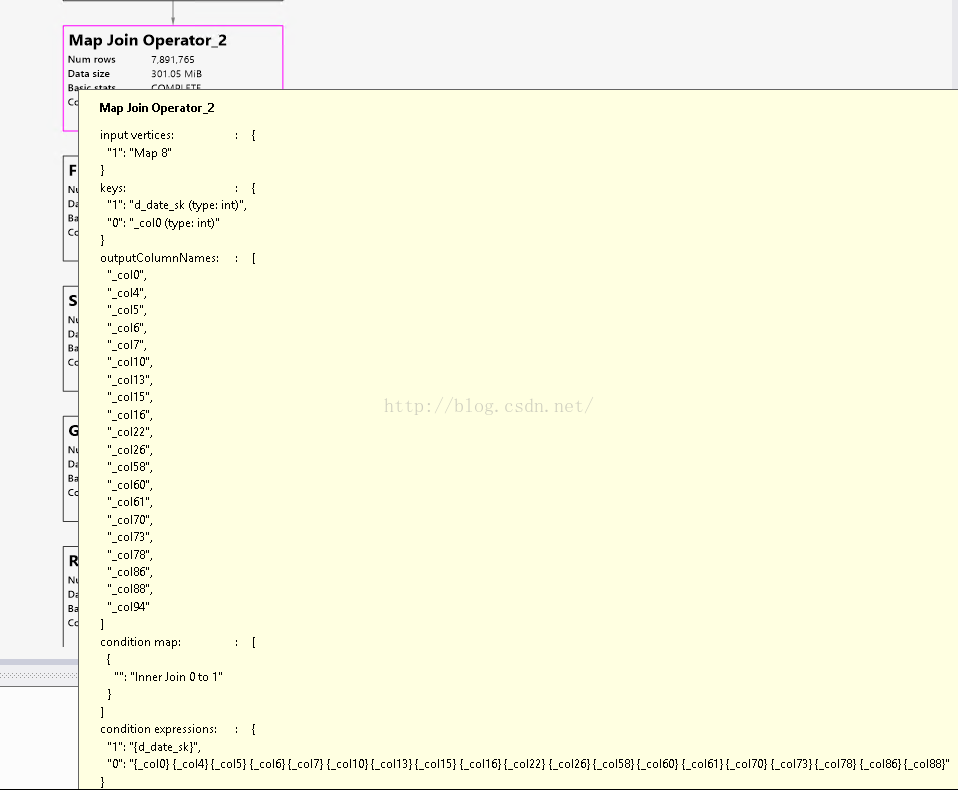
Map8 is the only mapsidejoin converted to inner join as we expected, its corresponding table is “data_dim”and look up it in script andits where condition is “store_sales.ss_sold_date_sk = date_dim.d_date_sk
anddate_dim.d_year = 2001”.Compared with other two mapside join conditions,it is much simple. So I think perhaps it is an optimization issue for hive and itcannot deal with some complex situations for implicit join. I also wonder the latest hive version
can solve this issue.
Let us change this script by handand we get below script. the only difference is to extract some common “where condition” and their logic aretotally same, then rerun it.
use tpcds_text_2;
set hive.execution.engine=tez;
select avg(ss_quantity)
,avg(ss_ext_sales_price)
,avg(ss_ext_wholesale_cost)
,sum(ss_ext_wholesale_cost)
from store_sales
,store
,customer_demographics
,household_demographics
,customer_address
,date_dim
where store_sales.ss_store_sk=store.s_store_sk
and store_sales.ss_sold_date_sk = date_dim.d_date_sk
and store_sales.ss_hdemo_sk=household_demographics.hd_demo_sk
and store_sales.ss_cdemo_sk=customer_demographics.cd_demo_sk
and store_sales.ss_addr_sk = customer_address.ca_address_sk
and date_dim.d_year = 2001
and((
customer_demographics.cd_marital_status = 'M'
and customer_demographics.cd_education_status = '4 yr Degree'
and store_sales.ss_sales_price between 100.00 and 150.00
and household_demographics.hd_dep_count = 3
)or
(customer_demographics.cd_marital_status = 'D'
and customer_demographics.cd_education_status = 'Primary'
and store_sales.ss_sales_price between 50.00 and 100.00
and household_demographics.hd_dep_count = 1
) or
(customer_demographics.cd_marital_status = 'U'
and customer_demographics.cd_education_status = 'Advanced Degree'
and store_sales.ss_sales_price between 150.00 and 200.00
and household_demographics.hd_dep_count = 1
))
and((customer_address.ca_country = 'United States'
and customer_address.ca_state in ('KY', 'GA', 'NM')
and store_sales.ss_net_profit between 100 and 200
) or
(
customer_address.ca_country = 'United States'
and customer_address.ca_state in ('MT', 'OR', 'IN')
and store_sales.ss_net_profit between 150 and 300
) or
(customer_address.ca_country = 'United States'
and customer_address.ca_state in ('WI', 'MO', 'WV')
and store_sales.ss_net_profit between 50 and 250
));Below is job execution graph, it took1 minute and 46 seconds to complete.
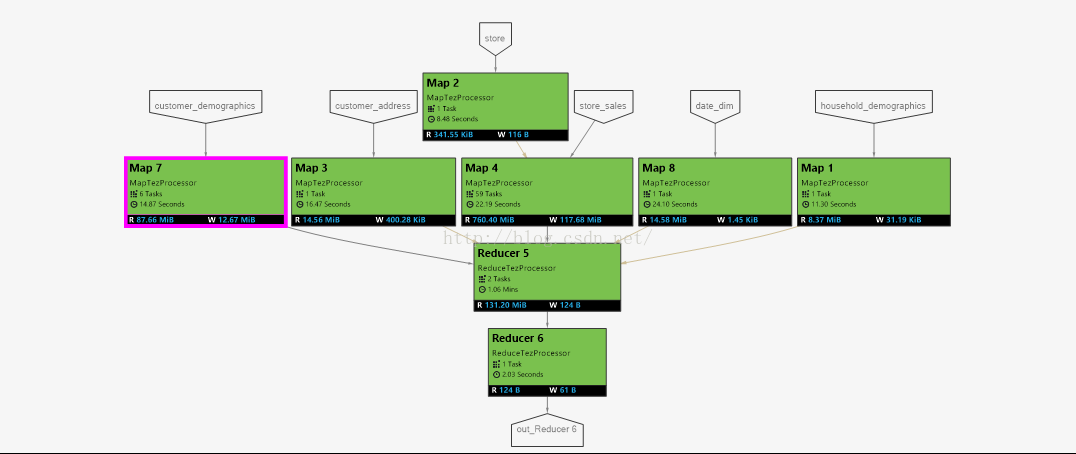
Compared this graph with above, bothhive job execution plan and Reducer5 execu
a5af
tion plan are same, the difference isall the mapside joins at reduce5 are inner join.
Go further, we continue to changethis script to using Join on operation explicitly. After moving some conditionsin “where” to “join on”,we get below script.
use tpcds_text_2;
set hive.execution.engine=tez;
select avg(ss_quantity)
,avg(ss_ext_sales_price)
,avg(ss_ext_wholesale_cost)
,sum(ss_ext_wholesale_cost)
from store_sales JOIN store On store.s_store_sk = store_sales.ss_store_sk
Join date_dim on store_sales.ss_sold_date_sk = date_dim.d_date_sk
Join household_demographics on store_sales.ss_hdemo_sk=household_demographics.hd_demo_sk
Join customer_demographics on customer_demographics.cd_demo_sk = store_sales.ss_cdemo_sk
Join customer_address ON store_sales.ss_addr_sk = customer_address.ca_address_sk
where date_dim.d_year = 2001
and((customer_demographics.cd_marital_status = 'M'
and customer_demographics.cd_education_status = '4 yr Degree'
and store_sales.ss_sales_price between 100.00 and 150.00
and household_demographics.hd_dep_count = 3
)or
(customer_demographics.cd_marital_status = 'D'
and customer_demographics.cd_education_status = 'Primary'
and store_sales.ss_sales_price between 50.00 and 100.00
and household_demographics.hd_dep_count = 1
) or
(customer_demographics.cd_marital_status = 'U'
and customer_demographics.cd_education_status = 'Advanced Degree'
and store_sales.ss_sales_price between 150.00 and 200.00
and household_demographics.hd_dep_count = 1
))
and((customer_address.ca_country = 'United States'
and customer_address.ca_state in ('KY', 'GA', 'NM')
and store_sales.ss_net_profit between 100 and 200
) or
(customer_address.ca_country = 'United States'
and customer_address.ca_state in ('MT', 'OR', 'IN')
and store_sales.ss_net_profit between 150 and 300
) or
(customer_address.ca_country = 'United States'
and customer_address.ca_state in ('WI', 'MO', 'WV')
and store_sales.ss_net_profit between 50 and 250
));Below it its job execution graph and its exaction plan haschanged. It took 1 minute 26 seconds to complete and 20 seconds faster thanabove script.
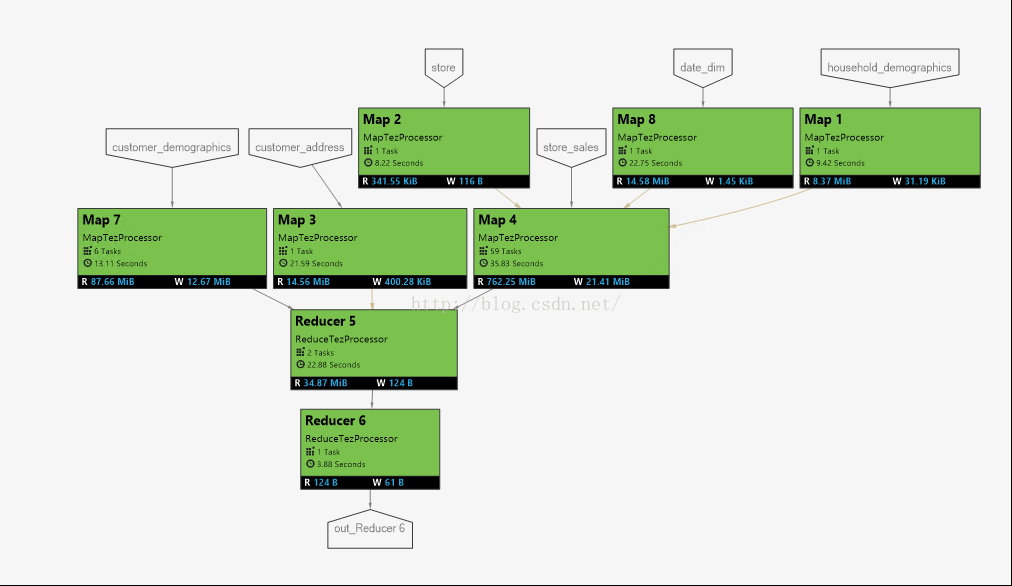
Conclusion
HDInsight tool is an excellent tool to do hivejob analysisUsing explicit join on if the script is complex

相关文章推荐
- 分享Hive的一份胶片资料
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- 将Hive的默认数据库Derby改为Postgresql
- kettle中对hive操作时需要知道的东西
- #Note# Analyzing Twitter Data with Apache Hadoo...
- [翻译]Hive wiki GettingStarted
- 启动hive命令报错 “Metastore contains multiple versions”
- sparksql与hive整合
- hive on spark 编译
- sqoop 中文文档 User guide 一
- sqoop 中文文档 User guide 二 import
- sqoop 中文文档 User guide 二 import续
- sqoop 中文文档 User guide 三 export
- sqoop 中文文档 User guide 四 validation
- sqoop 中文文档 User guide 五 job,metastore,merge,codegen
- sqoop 中文文档 User guide 六
- sqoop 中文文档 User guide 七
- Hadoop Hive的限制
- HIVEQL
- hive 安装配置