ARM64的启动过程之(四):打开MMU
2015-10-24 15:30
295 查看
ARM64的启动过程之(四):打开MMU
http://www.wowotech.net/linux_kenrel/turn-on-mmu.html一、前言
经过漫长的前戏,我们终于迎来了打开MMU的时刻,本文主要描述打开MMU以及跳转到start_kernel之前的代码逻辑。这一节完成之后,我们就会离开痛苦的汇编,进入人民群众喜闻乐见的c代码了。
二、打开MMU前后的概述
对CPU以及其执行的程序而言,打开MMU是一件很有意思的事情,好象从现实世界一下子走进了奇妙的虚幻世界,本节,我们一起来看看内核是如何“穿越”的。下面这张图描述了两个不同的世界:

当没有打开MMU的时候,cpu在进行取指以及数据访问的时候是直接访问物理内存或者IO memory。虽然64bit的CPU理论上拥有非常大的address space,但是实际上用于存储kernel image的物理main memory并没有那么大,一般而言,系统的main memory在低端的一小段物理地址空间中,如上图右侧的图片所示。当打开MMU的时候,cpu对memory系统的访问不能直接触及物理空间,而是需要通过一系列的Translation table进行翻译。虚拟地址空间分成三段,低端是0x00000000_00000000~0x0000FFFF_FFFFFFFF,用于user
space。高端是0xFFFF0000_00000000~0xFFFFFFFF_FFFFFFFF,用于kernel space。中间的一段地址是无效地址,对其访问会产生MMU fault。虚拟地址空间如上图右侧的图片所示。
Linker感知的是虚拟地址,在将内核的各个object文件链接成一个kernel image的时候,kernel image binary code中访问的都是虚拟地址,也就是说kernel image应该运行在Linker指定的虚拟地址空间上。问题来了,kernel image运行在那个地址上呢?实际上,将kernel image放到kernel space的首地址运行是一个最直观的想法,不过由于各种原因,具体的arch在编译内核的时候,可以指定一个offset(TEXT_OFFSET),对于ARM64而言是512KB(0x00080000),因此,编译后的内核运行在0xFFFF0000_00080000的地址上。系统启动后,bootloader会将kernel
image copy到main memory,当然,和虚拟地址空间类似,kernel image并没有copy到main memory的首地址,也保持了一个同样size的offset。现在,问题又来了:在kernel的开始运行阶段,MMU是OFF的,也就是说kernel image是直接运行在物理地址上的,但是实际上kernel是被linker链接到了虚拟地址上去的,在这种情况下,在没有turn on MMU之前,kernel能正常运行吗?可以的,如果kernel在turn on MMU之前的代码都是PIC的,那么代码实际上是可以在任意地址上运行的。你可以仔细观察turn
on MMU之前的代码,都是位置无关的代码。
OK,解决了MMU turn on之前的问题,现在我们可以准备“穿越”了。真正打开MMU就是一条指令而已,就是将某个system register的某个bit设定为1之类的操作。这样我们可以把相关指令分成两组,turn on mmu之前的绿色指令和之后的橘色指令,如下图所示:
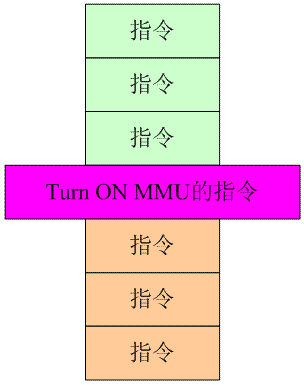
由于现代CPU的设计引入了pipe, super scalar,out-of-order execution,分支预测等等特性,实际上在turn on MMU的指令执行的那个时刻,该指令附近的指令的具体状态有些混乱,可能绿色指令执行的数据加载在实际在总线上发起bus transaction的时候已经启动了MMU,本来它是应该访问physical address space的。而也有可能橘色的指令提前执行,导致其发起的memory操作在MMU turn on之前就完成。为了解决这些混乱,可以采取一种投机取巧的办法,就是建立一致性映射:假设kernel
image对应的物理地址段是A~B这一段,那么在建立页表的时候就把A~B这段虚拟地址段映射到A~B这一段的物理地址。这样,在turn on MMU附近的指令是毫无压力的,无论你是通过虚拟地址还是物理地址,访问的都是同样的物理memory。
还有一种方法,就是清楚的隔离turn on MMU前后的指令,那就是使用指令同步工具,如下:
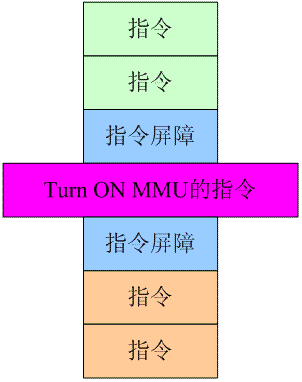
指令屏障可以清清楚楚的把指令的执行划分成三段,第一段是绿色指令,在执行turn on mmu指令执行之前全部完成,随后启动turn on MMU的指令,随后的指令屏障可以确保turn on MMU的指令完全执行完毕(整个计算机系统的视图切换到了虚拟世界),这时候才启动橘色指令的取指、译码、执行等操作。
三、打开MMU的代码
具体打开MMU的代码在__enable_mmu函数中如下:
__enable_mmu:
ldr x5, =vectors
msr vbar_el1, x5 ---------------------------(1)
msr ttbr0_el1, x25 // load TTBR0 -----------------(2)
msr ttbr1_el1, x26 // load TTBR1
isb
msr sctlr_el1, x0 ---------------------------(3)
isb
br x27 -------------跳转到__mmap_switched执行,不设定lr寄存器
ENDPROC(__enable_mmu)
传入该函数的参数有四个,一个是x0寄存器,该寄存器中保存了打开MMU时候要设定的SCTLR_EL1的值(在__cpu_setup函数中设定),第二个是个是x25寄存器,保存了idmap_pg_dir的值。第三个参数是x26寄存器,保存了swapper_pg_dir的值。最后一个参数是x27,是执行完毕该函数之后,跳转到哪里去执行(__mmap_switched)。
(1)VBAR_EL1, Vector Base Address Register (EL1),该寄存器保存了EL1状态的异常向量表。在ARMv8中,发生了一个exception,首先需要确定的是该异常将送达哪一个exception level。如果一个exception最终送达EL1,那么cpu会跳转到这里向量表来执行。具体异常的处理过程由其他文档描述,这里就不说了。
(2)idmap_pg_dir是为turn on MMU准备的一致性映射,未来将会用于用户空间的进程,在进程切换的时候,其地址空间的切换实际就是修改TTBR0的值。TTBR1用于kernel space,所有的内核线程都是共享一个空间就是swapper_pg_dir。
(3)打开MMU。实际上在这条指令的上下都有isb指令,理论上已经可以turn on MMU之前之后的代码执行顺序严格的定义下来,其实我感觉不必要再启用idmap_pg_dir的那些页表了,当然,这只是猜测。
四、通向start_kernel
我痛恨汇编,如果能不使用汇编那绝对不要使用汇编,还好我们马上就要投奔start_kernel:
__mmap_switched:
adr_l x6, __bss_start
adr_l x7, __bss_stop
1: cmp x6, x7
b.hs 2f
str xzr, [x6], #8 ---------------clear BSS
b 1b
2:
adr_l sp, initial_sp, x4
str_l x21, __fdt_pointer, x5 // Save FDT pointer
str_l x24, memstart_addr, x6 // Save PHYS_OFFSET
mov x29, #0
b start_kernel
ENDPROC(__mmap_switched)
这段代码分成两个部分,一部分是清BSS,另外一部分是为进入c代码做准备(主要是stack)。clear BSS段就是把未初始化的全局变量设定为0的初值,没有什么可说的。要进入start_kernel这样的c代码,没有stack可不行,那么如何设定stack呢?熟悉kernel的人都知道,用户空间的进程当陷入内核态的时候,stack切换到内核栈,实际上就是该进程的thread info内存段(4K或者8K)的顶部。对于swapper进程,原理是类似的:
.set initial_sp, init_thread_union + THREAD_START_SP
为了方便后面的代码的访问,这里还初始化了两个变量,分别是__fdt_pointer(设备树信息,物理地址)和memstart_addr(kernel space的物理地址,main memory的首地址)。
五、参考文献
1、ARM Architecture Reference Manual

相关文章推荐
- IOS动画Core Animation详解
- What does the yield keyword do in Python?
- Android中JNI 的一些常用Method说明
- 装饰器与子类化
- uva 10790
- eclipse启动tomcat无法访问
- 洛谷1341 无序字母对
- iOS 实现SOAP协议
- android调用web service(cxf)实例
- 一看就会Android之列表视图组件ListView结合Adapter的使用及监听
- 加载动态图片
- HorizontalScrollView
- 使用读写锁实现同步数据访问
- apicloud代码压缩和全局加密
- Cocoa Touch框架浅析
- c#换ip代理源码
- 网络流_Dinic
- JAVA泛型详解2 转载
- searchView黑框问题--如何不显示黑框
- 冗余字段