Spark入门_1_RddTransAction
2015-10-24 10:59
871 查看
ipython
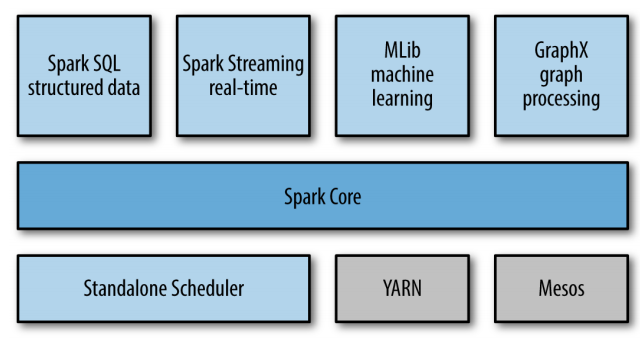
spark core concept
RDD
creating rdds
rdd operations
transformation
action
lazy evaluation
passing function
common transformation and action
transformation
action
caching
key-value pair
creating paired rdds
transformation
general
aggregation
turning the level of parallelism
grouping
joins
sorting data
action
general
partitioning
cause
example
determining partition
operations which benefits from partition
operations which affects partition
pagerank
custom

Spark UI: ipaddress:4040
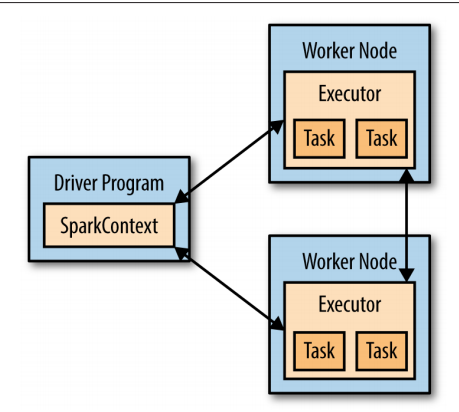
SparkContext:driver program通过SparkContext连接Spark(连接到计算机群)。shell中spark context自动创建。
RDD:用来指代分布的数据集,可以在上面进行tansform、action等操作。一旦SparkContext创建好(也就是driver program和Spark连接好了),就可以创建RDD。比如
pythonLines = lines.filter(lambda line: ‘Python’ in line)
write code in a single driver program and automatically have parts of it run on multiple nodes.
布置standalone program应用的时候,和shell方式唯一的不同就是需要初始化SparkContext,去和Spaek建立联系。
spark-submit在python脚本中添加了Spark 的依赖,建立了Spark’s Python API环境。
RDD is immutable distributed collection of objects.
Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster.
2 ways to create RDDS:
1. load an external dataset.
2. distribute a collection of objects(e.g. a list or set)
lazy fashion的好处,比如first这个action,如果不采用lazy fashion的话可能需要遍历整个文件。
If you would like to reuse an RDD in multiple actions, you can ask Spark to
persist it using RDD.persist().
In practice, you will often use persist() to load a subset of your data into memory and query it repeatedly.
步骤(spark program and shell session):
create some input RDDs from external data or a collection of objects.
transform them to define new RDDs using tansformations like filter().
ask spark to persist() or cache() any intermediate RDDs that will need to be reused.
launch actions such as count() and first() to kick off a parallel computation, which is then optimized and executed by spark.
Keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large
datasets.
It is important to note that each time we call a new action, the entire RDD must be computed “from scratch.” To avoid this inefficiency, users can persist intermediate results.
Loading data into an RDD is lazily evaluated in the same way trans‐
formations are. So, when we call sc.textFile(), the data is not loaded until it is nec‐essary. As with transformations, the operation (in this case, reading the data) can occur multiple times.
In systems like Hadoop MapReduce, developers often have to spend a lot of time considering how to group together operations to minimize the number of MapReduce passes. In Spark, there is no substantial benefit to writing a single complex map instead of chaining together many simple opera‐
tions. Thus, users are free to organize their program into smaller, more manageable operations.
one thing to watch out

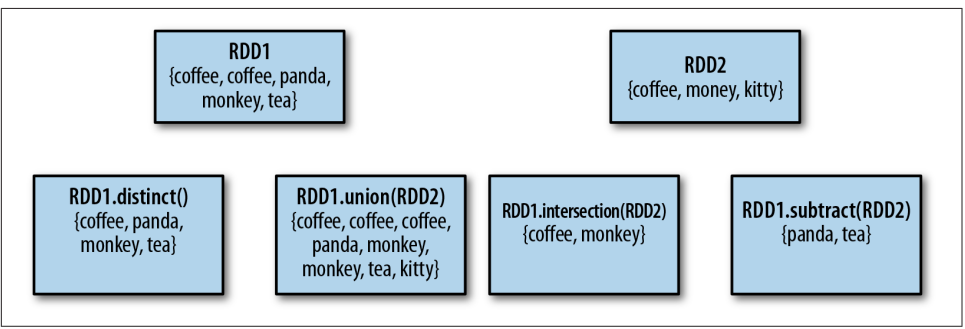
distinct() intersection() is expensive.

foreach() action lets us perform computations on each element in the RDD without
bringing it back locally.


use the same RDD multiple times. If we do this naively, Spark will recompute the
RDD and all of its dependencies each time we call an action on the RDD. This can be
especially expensive for iterative algorithms, which look at the data many times.







When performing aggregations or grouping operations, we can ask Spark to use a specific number of partitions.






对于分布式系统,communication非常昂贵,因此放置数据去最小化网络的沟通消耗会极大地提高系统的效率。
这就是partition发挥威力的地方,尤其在

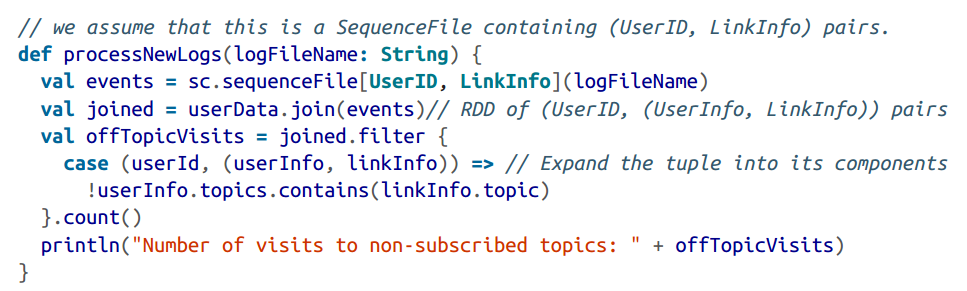
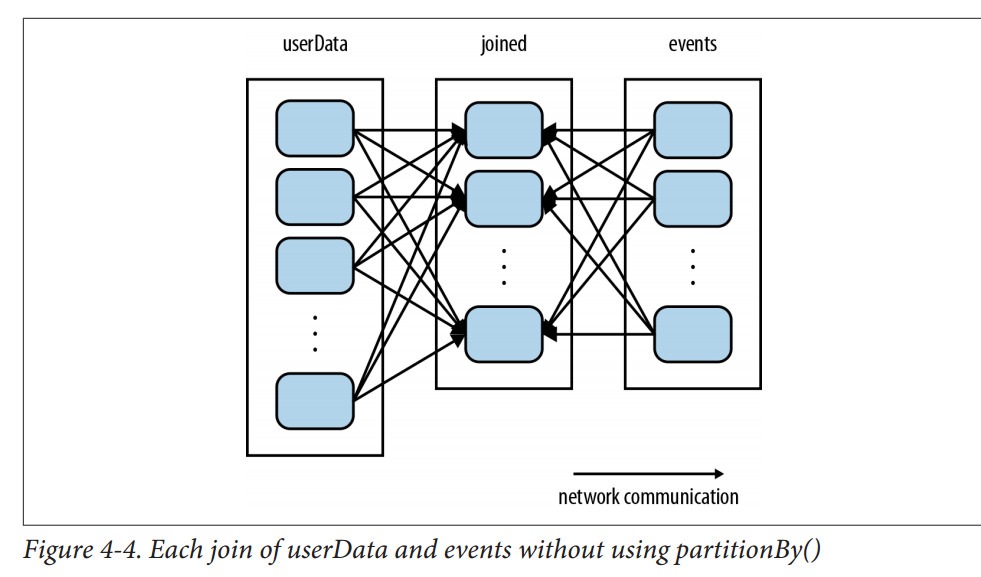
partition越大越好

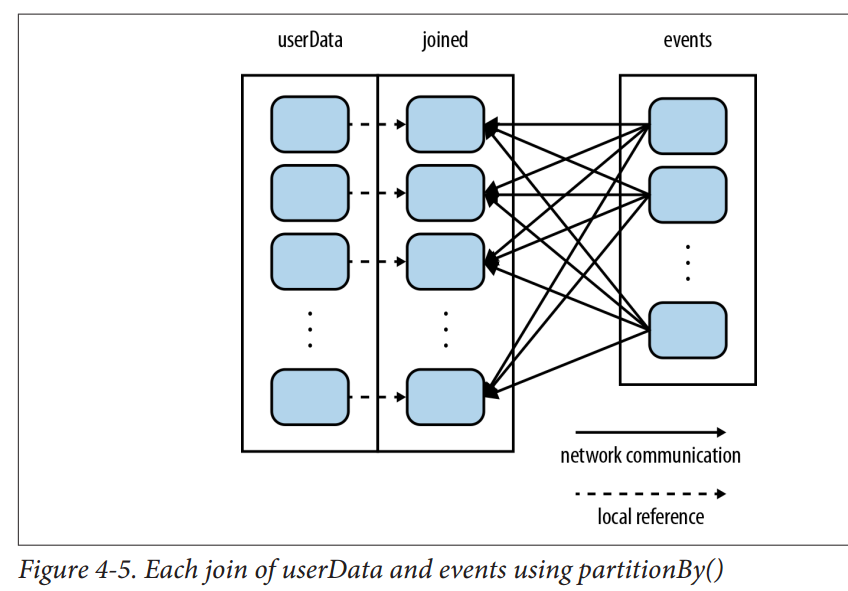


有一些操作,比如sortByKey, groupByKey本身就会产生partition的RDD。







spark core concept
RDD
creating rdds
rdd operations
transformation
action
lazy evaluation
passing function
common transformation and action
transformation
action
caching
key-value pair
creating paired rdds
transformation
general
aggregation
turning the level of parallelism
grouping
joins
sorting data
action
general
partitioning
cause
example
determining partition
operations which benefits from partition
operations which affects partition
pagerank
custom
ipython
Spark UI: ipaddress:4040
spark core concept
driver program: 每个spark的应用都包括一个driver program。driver program包含应用的主要函数并且定义了集群中的分布数据集,然后对数据集进行一定的操作。spark-shell,pyspark就是一个driver program。SparkContext:driver program通过SparkContext连接Spark(连接到计算机群)。shell中spark context自动创建。
RDD:用来指代分布的数据集,可以在上面进行tansform、action等操作。一旦SparkContext创建好(也就是driver program和Spark连接好了),就可以创建RDD。比如
sc.textFile('1.txt')。pythonLines = lines.filter(lambda line: ‘Python’ in line)
write code in a single driver program and automatically have parts of it run on multiple nodes.
布置standalone program应用的时候,和shell方式唯一的不同就是需要初始化SparkContext,去和Spaek建立联系。
spark-submit在python脚本中添加了Spark 的依赖,建立了Spark’s Python API环境。
spark-submit my_script.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
f = sc.textFile("/usr/local/spark/README.md")
print f.count()
#shutdown spark
sc.stop()
sys.exit()RDD
In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result.RDD is immutable distributed collection of objects.
Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster.
2 ways to create RDDS:
1. load an external dataset.
2. distribute a collection of objects(e.g. a list or set)
lazy fashion的好处,比如first这个action,如果不采用lazy fashion的话可能需要遍历整个文件。
If you would like to reuse an RDD in multiple actions, you can ask Spark to
persist it using RDD.persist().
In practice, you will often use persist() to load a subset of your data into memory and query it repeatedly.
pythonLines.persist pythonLines.count() pythonLines.first()
步骤(spark program and shell session):
create some input RDDs from external data or a collection of objects.
transform them to define new RDDs using tansformations like filter().
ask spark to persist() or cache() any intermediate RDDs that will need to be reused.
launch actions such as count() and first() to kick off a parallel computation, which is then optimized and executed by spark.
creating rdds
#from a collection of objects
#outside of prototyping and testing, this is not widely used since
it requires that you have your entire dataset in memory on one machine.
lines = sc.parallelize(["pandas", "i like pandas"])
#load data from external storage
lines = sc.textFile("/path/to/README.md")rdd operations
transformation
lazy evaluationinputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda x: "error" in x)
#rdd is immutable, so filter command creates a new rdd
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
badLinesRDD = inputRDD.filter(lambda x: "warning" in x or "error" in x)action
return a final value to the driver program or write data to an external storage system.print "Input had " + badLinesRDD.count() + " concerning lines" print "Here are 10 examples:" for line in badLinesRDD.take(10): print line rdd.saveAsTextFile() rdd.saveAsTextFile()
Keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large
datasets.
It is important to note that each time we call a new action, the entire RDD must be computed “from scratch.” To avoid this inefficiency, users can persist intermediate results.
lazy evaluation
Rather than thinking of an RDD as containing specific data, it is best to think of each RDD as consisting of instructions on how to compute the data that we build up through transformations.Loading data into an RDD is lazily evaluated in the same way trans‐
formations are. So, when we call sc.textFile(), the data is not loaded until it is nec‐essary. As with transformations, the operation (in this case, reading the data) can occur multiple times.
In systems like Hadoop MapReduce, developers often have to spend a lot of time considering how to group together operations to minimize the number of MapReduce passes. In Spark, there is no substantial benefit to writing a single complex map instead of chaining together many simple opera‐
tions. Thus, users are free to organize their program into smaller, more manageable operations.
passing function
word = rdd.filter(lambda s: "error" in s) def containsError(s): return "error" in s word = rdd.filter(containsError)
one thing to watch out
common transformation and action
transformation
map()
filter()
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print "%i " % (num)
lines = sc.parallelize(["hello world", "hi"])
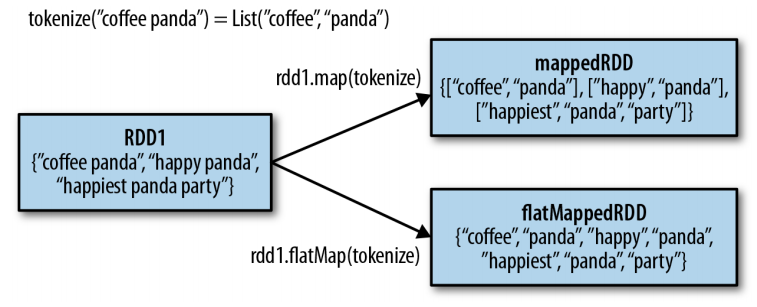
words = lines.flatMap(lambda line: line.split(" "))
words.first() # returns "hello"distinct() intersection() is expensive.
action
sum = rdd.reduce(lambda x, y: x + y) sumCount = nums.aggregate((0, 0), (lambda acc, value: (acc[0] + value, acc[1] + 1), (lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1])))) return sumCount[0] / float(sumCount[1])
foreach() action lets us perform computations on each element in the RDD without
bringing it back locally.
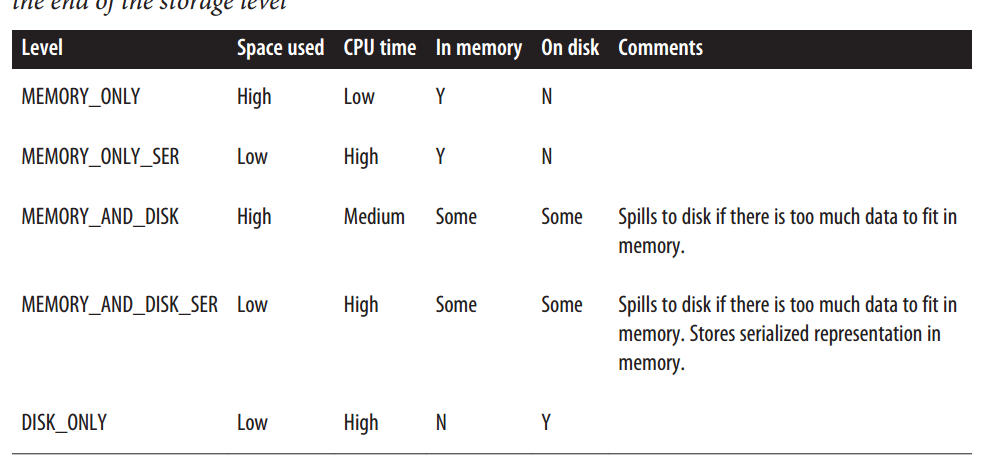
caching
As discussed earlier, Spark RDDs are lazily evaluated, and sometimes we may wish touse the same RDD multiple times. If we do this naively, Spark will recompute the
RDD and all of its dependencies each time we call an action on the RDD. This can be
especially expensive for iterative algorithms, which look at the data many times.
val result = input.map(x => x*x)
println(result.count())
println(result.collect().mkString(","))
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))
#remove from cache
rdd.uppersist()key-value pair
creating paired rdds
pairs = lines.map(lambda x: (x.split(" ")[0], x))
SparkContext.parallelize([(1,'m'),(1,'f'),(2,'m')])transformation
general
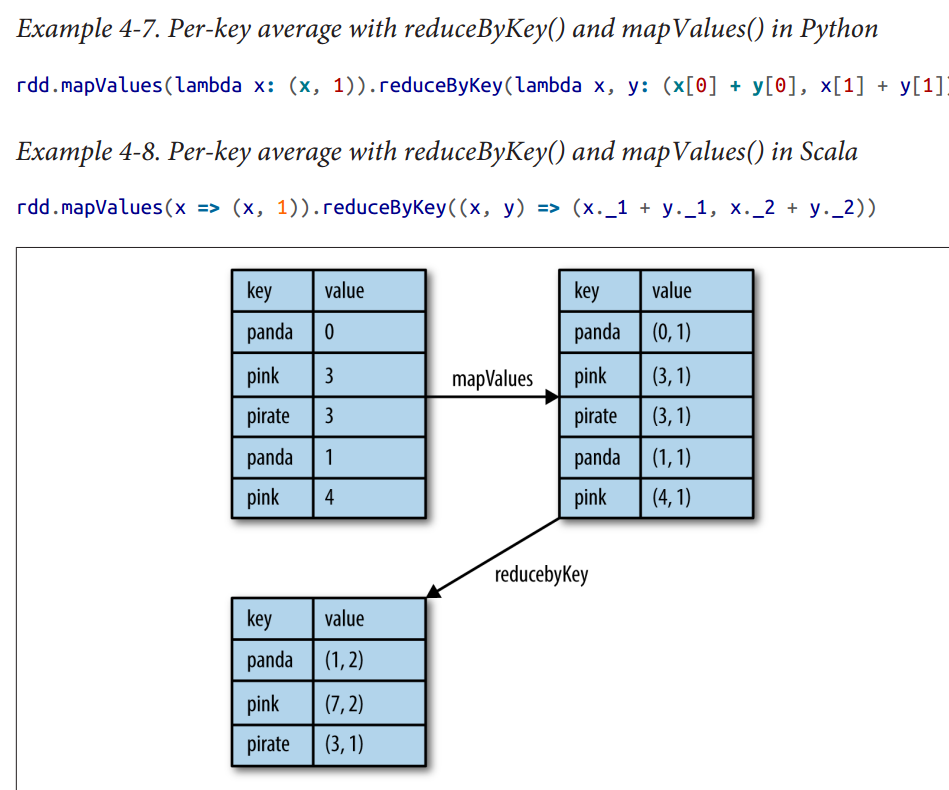
aggregation
turning the level of parallelism
Every RDD has a fixed number of paritions that determine the degree of parallelism to use when executing operations on the RDD.When performing aggregations or grouping operations, we can ask Spark to use a specific number of partitions.
#somes, we want to change the partitioning of an RDD outside the context of grouping and aggregation operations. rdd.repartition() #shufle data across the network, which is very expensive. rdd.coalesce() #avoid data movement, but only if you are decreasing the number of partition. rdd.partitions.size() rdd.getNumPartitions() #show partition size
grouping
joins
sorting data
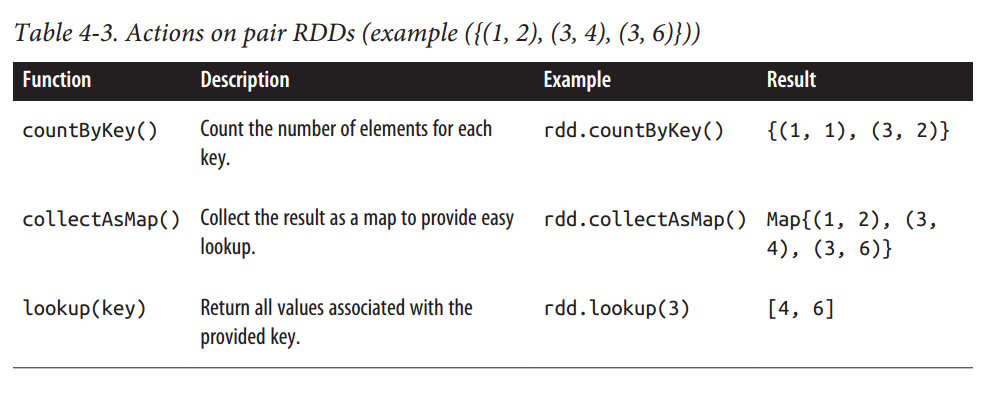
action
general
partitioning
cause
类比单节点的程序需要有好的数据结构去存储数据方便查询提高效率。对于分布式系统,communication非常昂贵,因此放置数据去最小化网络的沟通消耗会极大地提高系统的效率。
这就是partition发挥威力的地方,尤其在
datasets is reused multiple times的情况下。
example
partition越大越好
有一些操作,比如sortByKey, groupByKey本身就会产生partition的RDD。
determining partition
operations which benefits from partition
operations which affects partition
pagerank
custom

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Spark初探
- Spark Streaming初探
- 搭建hadoop/spark集群环境
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark 性能相关参数配置详解-任务调度篇
- 基于spark1.3.1的spark-sql实战-01
- 基于spark1.3.1的spark-sql实战-02
- 在 Databricks 可获得 Spark 1.5 预览版
- spark standalone模式 zeppelin安装
- Apache Spark 1.5.0正式发布
- Tachyon 0.7.1伪分布式集群安装与测试
- spark取得lzo压缩文件报错 java.lang.ClassNotFoundException
- tachyon与hdfs,以及spark整合
- hive on spark 编译
- 使用openfire,spark,fastpath webchat搭建在线咨询服务详细图文解说