junior-week6
2015-10-22 11:37
267 查看
由于第四周的托福考试,blog误了一期,此次补上。
character c(c是属于语言所规定的alphabet):S(c)={c};
ε:代表空串,S(ε)={}
concatenation e1e2: e1e2分别是reg-exp,S(e1e2)=S(e1)S(e2)
choice e1|e2:S(e1|e2)=S(e1) U S(e2)
kleen closure e*:S(e*)=S(ε) U S(e) U S(ee) U S(eee) U … = S(e0) U S(e1) U S(e2) U S(e3) U …
正闭包 e+:S(e+)=S(e) U S(ee) U S(eee) U …
我们只要正对五种模式设计相应的NFA,那么针对任何NFA我们都可以生成其NFA。
对character c & ε
concatenation e1e2

choice e1|e2
kleen closure e*
而对于正闭包 e+只需要将上图中起始状态直通接收状态的ε去掉
给出一个例子
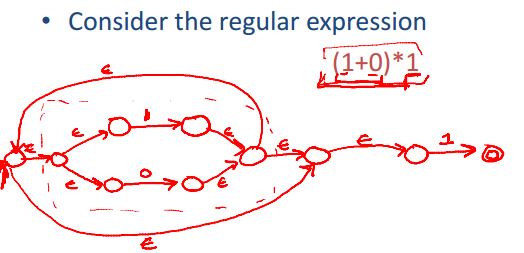
看一个例子,理解了即可
在词法分析的最后我们来说说reg-exp的限制性,reg-exp只能表示词法相关的语法,而要表示语法相关的语法,比如括号的匹配等等,reg-exp是无法做到的,因为fa是没有记忆功能的,所以要完成语法分析就要引出上下文无关文法。
将文本划分成一系列的token
給每个token附加上属性值
消除white space和注释
syntax analysis实际上是一个parser,他的作用是将
- input:sequence of tokens from lexer
转换成
- output : parse tree of the program
CFG有以下要素:
set of terminals T
set of non-terminals N
start symbol S(non-terminal)
set of productions,形式大概像是X—>Y1Y2…Yn,其中X为N,Yi为N∪T
现在对于一串字符,就可以根据productions将其中的N转换T,比如假设B->abc,那么ABC=>AabcC,=>表示将一串字符重写,=>*则表示经过一个或多个=>所转换成的形式。
有了CFG之后就可以定义语言了,一门语言就是start symbol S所能转换成的所有terminals组合的集合。
在这里再多提一点,有CFG就有CSG(context-sensitive grammar),所谓CSG就是指left-hand-side and right-hand-side 可能周围有terminal或者non-terminal symbols,因此context-sensitive grammar比cfg范围更广。
能够定义语言了之后所要考虑的肯定是how to recognize。对于不同的parsing techniques,一般可以分类如下

第一个空可以是L或者R,代表parse的时候from left to right还是from right to left.
第二个空也可以是L或者R,代表leftmost derivation 还是rightmost derivation,
第三个括号内的数字代表lookhead的characters
right most同理。
make all operators associate to left
group operators into precedence levels
if then else之类的语法不规范也要明确。
或者也可以用declaration的方式来处理ambiguity,而不是修改grammar。
但还是有一些问题,比如left recursion,会导致无限循环,这就需要hack grammar。
left recursion的语法形式S->Sa1 | Sa2 … | San | b1 | b2 … | bn
选择的那个production必然需要能够匹配输入的第一个token。
一个简单的例子是可以通过hand coding就可以解决parsing的问题了。
当然可能遇到问题,比如有多个production有着相同的前缀
NT->if then
NT->if then else
left factor之后的grammar就可以得到parsing table了。

grammar如上图所示,问题的关键其实就是First Set和Follow Set.
First Set,理解上来说就是一个NT所能产生T串中的第一个T。
Follow Set,就是考虑到NT产生的第一个NT可能为空,于是产生了一个follow set。
接下来介绍compute first set的算法

拿到一个NT比如X,接着看它的产生式,产生式的右端有T,就直接放在First Set里面了,有NT的话,那么First(NT)属于First(X),或者有若干个NT的话,前面的NT可能为空,那么后面的First(NTi)属于First(X)。
在介绍compute follow set的算法

简单来说,对于每个production都可以找出这样一些Follow的包含集合,有些可以直接看出来,就通过这样一种计算来找出follow set。
这样算出来的parsing table如果任何entry multiple defined,说明该grammar不是LL(1)的,可能是
ambiguous
left recursive
not left-factored(多重选择)
other cases
在predicative parsing 的最后举一个例子来结束它。
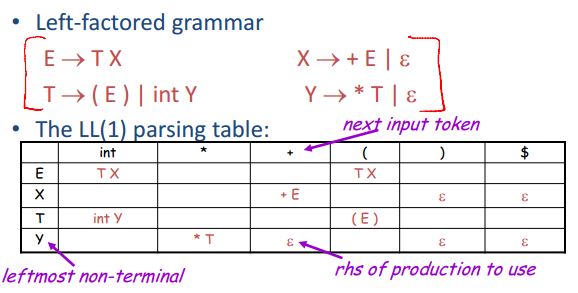
LL(1)parsing的过程其实也可以通过一个栈来完成


引出bottom-up parsing的方法之前先说说Grammar和automaton的对应关系。
bottom-up don’t need left-factored grammar
shift——shift current input symbol from input onto stack
reduce——if symbols on top of stack match rhs, then pop symbols off the stack and push lhs NT onto the stack
accept
要用push-down automata解析token stream存在的可能conflicts
reduce/reduce
shift/reduce
那么如何决定何时shift,何时reduce呢
将input token划分为a和w,a|w,a是已经在栈上的,w是剩余的
viable prefix:如果a|w是shift-reduce parser的一个状态那么a是一个viable prefix,可行的前缀。
important fact:for any grammar,the set of viable prefixes is a regula
7141
r language
item:a production with a “.” on the rhs
在栈上,我们通常只有rhs右边的前一部分

要注意pre组成的只是栈上的部分,后面还有其他的。其中ai是由Prefix(i)+后面一部分组成,当ai可以退回成Xi之后,那么现在Prefix(i-1)+Xi+后面一部分又组成a(i-1)又可以退回成X(i-1)。
因此栈上的东西又可以称之为“the stack of items”
现在要做的事情就是
认出一串的产生式的右半部分的前缀。
每一部分前缀最终可以转换成前面的前缀的后缀的一部分^_^
在这个NFA中
states:items of Grammar
transition:加上两类transition的规则
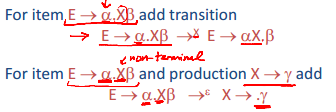
接收状态:每个状态都是
开始:S’->S
下面给出一个语法:

相应VP的NFA:
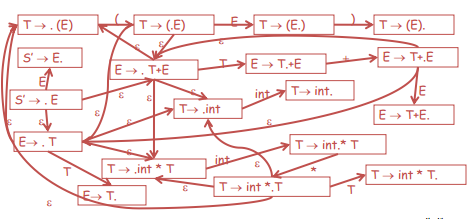
这时就可以开始parse token stream了,当进行reduce操作后,会改变原来的token stream,因此需要重头再来。
在LR(0)parsing中

很明显LR(0)parsing会出现conflicts

接下来提出的是SLR parsing,reduce的规则稍有不同
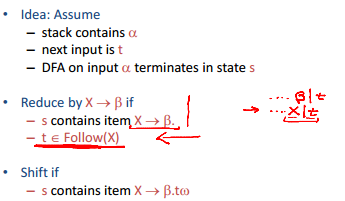
如果在这种情况下仍然出现conflicts,则不是SLR grammar,比如ambiguous的grammar都不是SLR,但经过前面的precedence之后可以变成SLR。
针对上图语法,给出一个实例:

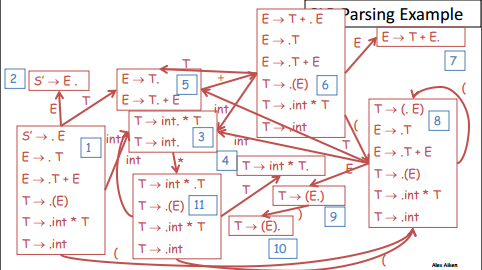
compiler
lexical analysis
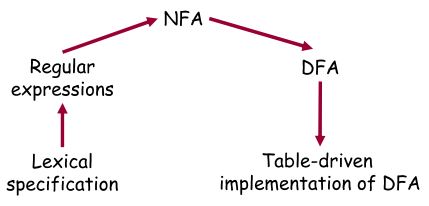
上次实际上是在lexical analysis的过程中,我们已经用reg-exp定义好了一门语言,接下来要想识别我们的语言,reg-exp对应的正是finite automaton,fa又分为NFA和DFA,下表描述了这一过程。reg-exp to NFA
上次说到reg-exp有五种模式character c(c是属于语言所规定的alphabet):S(c)={c};
ε:代表空串,S(ε)={}
concatenation e1e2: e1e2分别是reg-exp,S(e1e2)=S(e1)S(e2)
choice e1|e2:S(e1|e2)=S(e1) U S(e2)
kleen closure e*:S(e*)=S(ε) U S(e) U S(ee) U S(eee) U … = S(e0) U S(e1) U S(e2) U S(e3) U …
正闭包 e+:S(e+)=S(e) U S(ee) U S(eee) U …
我们只要正对五种模式设计相应的NFA,那么针对任何NFA我们都可以生成其NFA。
对character c & ε
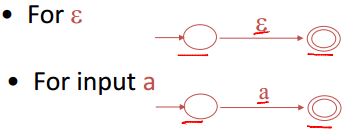
concatenation e1e2
choice e1|e2
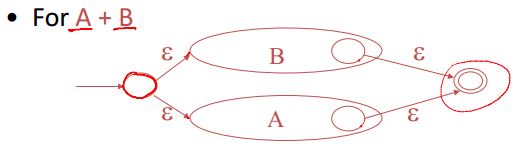
kleen closure e*
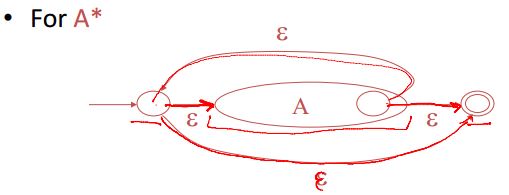
而对于正闭包 e+只需要将上图中起始状态直通接收状态的ε去掉
给出一个例子
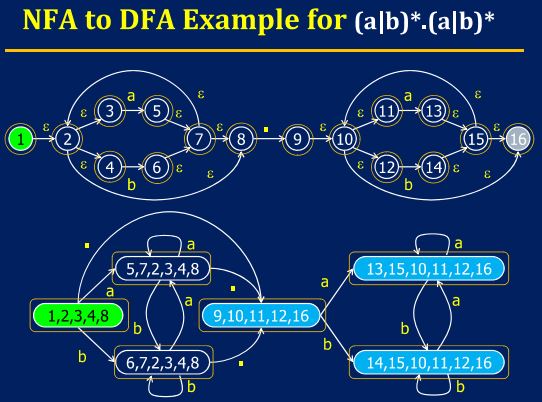
NFA to DFA
由于NFA的一个state可以通过ε自由转移状态,因此NFA转换到DFA,DFA中的一个状态将是NFA中某个状态所能到达的状态的集合。看一个例子,理解了即可
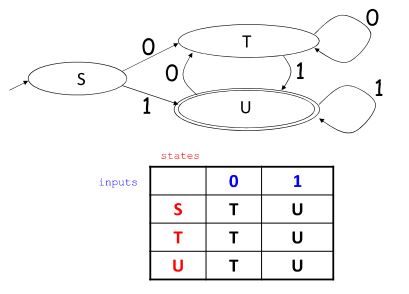
DFA to implementation
通过二维数组即可实现DFA的状态转换在词法分析的最后我们来说说reg-exp的限制性,reg-exp只能表示词法相关的语法,而要表示语法相关的语法,比如括号的匹配等等,reg-exp是无法做到的,因为fa是没有记忆功能的,所以要完成语法分析就要引出上下文无关文法。
syntax analysis(1)——Basic
前面lexical analysis完成的工作是将文本划分成一系列的token
給每个token附加上属性值
消除white space和注释
syntax analysis实际上是一个parser,他的作用是将
- input:sequence of tokens from lexer
转换成
- output : parse tree of the program
context-free grammar
前面说到reg-exp的限制性,在程序中经常出现各种嵌套的结构,比如一个expr又是expr+expr之类的,context-free-grammar比reg-exp要强大,能够描述这类结构,因此我们先要引入CFG。CFG有以下要素:
set of terminals T
set of non-terminals N
start symbol S(non-terminal)
set of productions,形式大概像是X—>Y1Y2…Yn,其中X为N,Yi为N∪T
现在对于一串字符,就可以根据productions将其中的N转换T,比如假设B->abc,那么ABC=>AabcC,=>表示将一串字符重写,=>*则表示经过一个或多个=>所转换成的形式。
有了CFG之后就可以定义语言了,一门语言就是start symbol S所能转换成的所有terminals组合的集合。
在这里再多提一点,有CFG就有CSG(context-sensitive grammar),所谓CSG就是指left-hand-side and right-hand-side 可能周围有terminal或者non-terminal symbols,因此context-sensitive grammar比cfg范围更广。
能够定义语言了之后所要考虑的肯定是how to recognize。对于不同的parsing techniques,一般可以分类如下
第一个空可以是L或者R,代表parse的时候from left to right还是from right to left.
第二个空也可以是L或者R,代表leftmost derivation 还是rightmost derivation,
第三个括号内的数字代表lookhead的characters
derivation
所谓的derivation其实就是start symbol S生成这门语言的表达式的时候的一个规则,left most即是指最左的,每次拿生成表达式中最左的NT开刀,这说明这个NT左边的已经都是T了。right most同理。
ambiguity
对一个token stream有multiple parse trees,就说明一个grammar是ambiguous,常见消除ambiguity的方法是重写grammar,将grammar改成make all operators associate to left
group operators into precedence levels
if then else之类的语法不规范也要明确。
或者也可以用declaration的方式来处理ambiguity,而不是修改grammar。
syntax analysis(2)——Top-down parsing
recursive descent parsing
基本思路就是以生成语言的方式进行解析。就是由S出发,每次将S转换,利用left most的策略,形成一个parse tree,在转换的过程中将最左的T和输入字符串比较。假如中途某一步转换出现错误,就backtracting,相当于一个遍历,直到能够解析token stream为止。但还是有一些问题,比如left recursion,会导致无限循环,这就需要hack grammar。
left recursion的语法形式S->Sa1 | Sa2 … | San | b1 | b2 … | bn
S ->b1S'| … | bnS' S'->a1S'| … | anS' | ε
predictive parsing LL(1)
basic idea是通过look ahead来解决选择哪个production。选择的那个production必然需要能够匹配输入的第一个token。
一个简单的例子是可以通过hand coding就可以解决parsing的问题了。
当然可能遇到问题,比如有多个production有着相同的前缀
NT->if then
NT->if then else
left factor之后变成 NT ->if then NT' NT'->else NT'->ε
left factor之后的grammar就可以得到parsing table了。
constructing parsing table
grammar如上图所示,问题的关键其实就是First Set和Follow Set.
First Set,理解上来说就是一个NT所能产生T串中的第一个T。
Follow Set,就是考虑到NT产生的第一个NT可能为空,于是产生了一个follow set。
接下来介绍compute first set的算法
拿到一个NT比如X,接着看它的产生式,产生式的右端有T,就直接放在First Set里面了,有NT的话,那么First(NT)属于First(X),或者有若干个NT的话,前面的NT可能为空,那么后面的First(NTi)属于First(X)。
在介绍compute follow set的算法
简单来说,对于每个production都可以找出这样一些Follow的包含集合,有些可以直接看出来,就通过这样一种计算来找出follow set。
这样算出来的parsing table如果任何entry multiple defined,说明该grammar不是LL(1)的,可能是
ambiguous
left recursive
not left-factored(多重选择)
other cases
在predicative parsing 的最后举一个例子来结束它。
LL(1)parsing的过程其实也可以通过一个栈来完成
syntax analysis(3)——Bottom_up_parsing
前面讲到的策略是top_down,大概意思是从S开始推导生成parse tree,匹配token stream,现在是bottom up的方式。从token stream开始,从底部生成parse tree。引出bottom-up parsing的方法之前先说说Grammar和automaton的对应关系。
| Grammar | Automaton |
|---|---|
| regular grammar | finite-state automaton |
| context-free grammar | push-down automaton |
| context-sensitive grammar | turning machine |
push-down automata
consist of three actionsshift——shift current input symbol from input onto stack
reduce——if symbols on top of stack match rhs, then pop symbols off the stack and push lhs NT onto the stack
accept
要用push-down automata解析token stream存在的可能conflicts
reduce/reduce
shift/reduce
viable prefix,handles,item
在shift/reduce parsing的过程中,从左到右读取input tokens。shift和reduce的含义在前面已经解释过。那么如何决定何时shift,何时reduce呢
将input token划分为a和w,a|w,a是已经在栈上的,w是剩余的
viable prefix:如果a|w是shift-reduce parser的一个状态那么a是一个viable prefix,可行的前缀。
important fact:for any grammar,the set of viable prefixes is a regula
7141
r language
item:a production with a “.” on the rhs
在栈上,我们通常只有rhs右边的前一部分
要注意pre组成的只是栈上的部分,后面还有其他的。其中ai是由Prefix(i)+后面一部分组成,当ai可以退回成Xi之后,那么现在Prefix(i-1)+Xi+后面一部分又组成a(i-1)又可以退回成X(i-1)。
因此栈上的东西又可以称之为“the stack of items”
现在要做的事情就是
认出一串的产生式的右半部分的前缀。
每一部分前缀最终可以转换成前面的前缀的后缀的一部分^_^
recognizing VP
前面说了vp实际组成了一个正则语言,因此用一个NFA来识别。在这个NFA中
states:items of Grammar
transition:加上两类transition的规则
接收状态:每个状态都是
开始:S’->S
下面给出一个语法:
相应VP的NFA:
这时就可以开始parse token stream了,当进行reduce操作后,会改变原来的token stream,因此需要重头再来。
在LR(0)parsing中
很明显LR(0)parsing会出现conflicts
接下来提出的是SLR parsing,reduce的规则稍有不同
如果在这种情况下仍然出现conflicts,则不是SLR grammar,比如ambiguous的grammar都不是SLR,但经过前面的precedence之后可以变成SLR。
针对上图语法,给出一个实例:

相关文章推荐
- WebSphere MQ 入门指南-1
- iOS - 定位服务
- update 追加一个字段的内容,或替换一个字段里面某些 字符
- iOS如何把所有界面的状态栏的字体颜色都设置为白色
- 学习技术的注意要点
- ubuntu 无法识别Usb
- Neutron命令测试3
- UVA 11478 Halum (差分约束)
- Algorithms: Design and Analysis Note
- 如何区分U盘和硬盘
- 2015年10月18日-10月24日课程作业(HA Cluster)
- InputStream OutputStream 操作文件
- springMVC初学实例(非注解)
- RSSI简介
- 【微信公众平台开发】php开发环境搭建设置(一)
- Log4J积累
- android自定义控件之ListView上拉加载与下拉刷新
- ubuntu12.04下 安装虚拟主机
- Android 源码阅读笔记
- ASP新手必备的基础知识