keepalived,代理及双主模型
2015-10-21 22:15
323 查看
Linux常见集群:将多台主机结合起来创造冗余集群,通过缩短平均修复时间提高系统可用性
LB:lvs,nginx
HA:Keepalived,heartbeat,corosync,cman
HP:高性能集群
并行处理:
分布式存储:HDFS:
分布式计算:YARN
batch:MapReduce
in-memory:spark
stream:sotrm 流式处理系统
Keepalived:
keepalived简介
keepalived是一个基于VRRP协议来实现IPVS的高可用的解决方案。对于LVS负载均衡来说,如果前端的调度器direct发生故障,则后端的realserver是无法接受请求并响应的。因此,保证前端direct的高可用性是非常关键的,否则后端的服务器是无法进行服务的。而我们的keepalived就可以用来解决单点故障(如LVS的前端direct故障)问题。keepalived的主要工作原理是:运行keepalived的两台服务器,其中一台为MASTER,另一台为BACKUP,正常情况下,所有的数据转换功能和ARP请求响应都是由MASTER开完成的,一旦MASTER发生故障,则BACKUP会马上接管MASTER的工作,这种切换时非常迅速的。
并且MASTER和BACKUP组成一个虚拟服务器,虚拟服务器有一个虚拟IP地址和一个虚拟MAC地址,这个虚拟IP地址就是对外服务的地址,虚拟IP地址总是运行在MASTER上。因此即便是MASTER发生故障,则BACKUP也参加竞选成为MASTER,因此也就具备了虚拟IP地址,继续向外提供服务。而keepalived之所以能够实现高可用功能,完全是因为它是基于VRRP协议来工作的,因此VRRP协议是keepalived的核心。所在在说keepalived之前,还是先来了解下VRRP协议吧。
VRRP协议
VRRP协议叫做虚拟路由冗余协议,从它的名称就可以知道它是用来提供冗余功能的。它是为了解决静态路由单点故障而设计的一个主从模式的协议,一旦MASTER节点发生故障,其该节点上的服务和IP地址会立刻转移到BACKUP节点上,从而继续提供高可用性。对于了解网络的朋友,都知道在设计网络的时候,必须要考虑到网络的冗余,这里的冗余指的是设备冗余。否则,一旦某一个单点路由器发生故障,其下行所有用户都不能上网了,这种现象是非常严重的。
而VRRP协议却可以很好的解决这个问题。VRRP协议设计的思想就是将多个物理路由器虚拟成一个路由器。这个路由器我们称作为虚拟路由器。虚拟路由器上有一个IP地址,叫做虚拟IP地址。这个虚拟IP地址是向外提供某种服务的地址或者当做某些主机或节点的网关地址。在这多个物理路由器上,拥有这个虚拟IP地址的路由器叫做MASTER路由器,其他的则是BACKUP路由器。只有MASTER路由器才能接受和转发数据,BACKUP路由器是不能转发数据的。对于谁能够成为MASTER路由器,需要根据每个路由器自身的优先级来判断的。对于虚拟路由器而言,只要有一台物理路由器是正常的,则虚拟路由器永远都不会发生故障,因此,即便MASTER路由器发生故障,其他的BACKUP也会立即参加竞选成为MASTER,从而继续提供数据转发功能和保证网络的连续性。
VRRP路由器
在这里先解释一下,这里所说的路由器在linux系统下则叫做服务器或者节点,而在网络中,专业的叫法则是称作为路由器。叫法虽不同,但是表达的都是一个意思。
VRRP路由器就是一台物理路由器,只是这台路由器上面运行了vrrp协议或者VRRPD程序。一台VRRP路由器可以位于多个虚拟路由器中。
虚拟路由器
虚拟路由器就是将多个VRRP路由器通过某种方式组成一个路由器,既然是虚拟的,就是说并不是实际存在的。虚拟路由器的标识符叫做虚拟路由器ID(VRID),其ID范围是0-255。
VRRP实例
VRRP实例就是提供某种相同服务或相同路由的一组路由器,每一个组就是一个实例。
MASTER和BACKUP
在一个虚拟路由器中,有多个VRRP路由器,这些VRRP路由器中又有一个叫做MASTER路由器,其他的则叫做BACKUP路由器。当VRRP协议在每一个物理路由器上初始启动时,则所有的路由器都会发送VRRP通告信息,且都会参加竞选成为MASTER路由器。其中每一个路由器都有一个priority,priority最大的路由器将会成为MASTER路由器,其他的则是BACKUP路由器。如果priority相同,则每个路由器上IP地址最大的路由器将会成为MASTER路由器。
MASTER路由器拥有虚拟IP地址,且负责响应ARP报文请求和转发数据。BACKUP只能接受VRRP报文通告。它不会抢占成为MASTER,除非它有更高的优先级。
VRRP协议的工作机制
VRRP路由器是通过竞选协议来实现虚拟路由器功能的,所有的VRRP报文都是通过多播的形式向外发送。虚拟路由器是由虚拟路由器ID(VRID)和虚拟IP地址组成的。虚拟路由器上有一个虚拟的MAC地址,其地址格式为:00-00-5E-00-01-{VRID}。所以,不管谁是MASTER路由器,其对外提供服务的IP(为VIP)和MAC地址(为虚拟MAC地址)都是相同的。客户端并不会因为MASTER的改变而改变,对他们来说,这种主从切换时透明的。
默认情况下,竞选成功后,只有MASTER路由器能够发送通告信息,且每个1秒钟发送一次。如果BACKUP路由器在这段时间内,没有收到MASTER路由器的VRRP通告信息,则认为MASTER路由器宕机,则BACKUP路由器中优先级最高的路由器会抢占成为为新的MASTER路由器。当然也可以通过VRRP接口跟踪功能来改变路由器的优先级以便让最高优先级的路由器成为MASTER。它的跟踪机制是:如果MASTER上监控的某个接口发生故障,则MASTER的priority值会相应降低,且降低后的priority值一定要小于BACKUP上的priority值。这样才可以保证,其他的BACKUP能够抢占成为新的MASTER路由器。
由于出于安全性的考虑,因此,MASTER和BACKUP之间的数据是加密传输的。
VRRP的主从模式
在这种模式下,只有一个MASTER,其他的则作为BACKUP。其中MASTER负责数据转发和响应ARP请求。
VRRP双主模式
在这种模式下,两台路由器都是MASTER路由器,每一台路由器上都运行着2个服务,其中每一台路由器即充当这个服务中的MASTER路由器又充当另一个服务的BACKUP路由器。在这种模式下,可以实现流量负载共享功能,即可以在多个设备上转发数据。
例如:有2个路由器,分别是server1和server2,且这两个路由器都运行着httpd和mysqld服务,对于server1来说,它即充当着httpd服务中的MASTER,又充当着mysqld服务中的BACKUP服务器。而server2即充当着mysqld服务中的MASTER,又充当着httpd服务中的BACKUP服务。
VRRP中的ARP处理机制
在VRRP协议中,只有MASTER才能够响应ARP请求,因此,当MASTER收到ARP请求时,它响应的是虚拟mac地址,而不是实际的物理机mac地址。因此,不管那台服务器作为MASTER其虚拟MAC地址都不会变,所以对于对端本机而言,其通信的目标mac地址仍然是虚拟mac地址,它是不会发生改变的。因此也就不会影响到对端主机的通信了。
VRRP的优势:
冗余性:可以使用多个路由器设备作为LAN客户端的默认网关,大大降低了默认网关成为单点故障的可能性;
负载共享:允许来自LAN客户端的流量由多个路由器设备所共享;
多VRRP组:在一个路由器物理接口上可配置多达255个VRRP组,每一个组就是一个实例;
多IP地址:基于接口别名在同一个物理接口上配置多个IP地址,从而支持在同一个物理接口上接入多个子网;
抢占:在master故障时允许优先级更高的backup成为master;
通告协议:使用IANA所指定的组播地址224.0.0.18进行VRRP通告;
VRRP接口追踪:基于接口状态来改变其VRRP优先级来确定最佳的VRRP路由器成为master;
Active/Passive(backup)
在多个节点提供相同服务,可能需要多个组件,入口
lvs:vip, ipvs rules
nginx: IP, nginx server
resource, 高可用集群中的资源
HA Service:resources

时间同步:
ntp协议:network time protocol
CentOS7上已经有替换版本
课外内容:如何实现时间同步

Keepalived:
vrrp协议在linux主机上以守护进程方式的额实现
能够根据配置文件自动生成ipvs规则
对各RS做健康状态监测:
组件:
vrrp stack
checkers
ipvs wapper --> ipvs
配置和使用Keepalived:
keepalived实现高可用服务具有的特性
1、在keepalived实现IPVS的高可用服务中,当MASETR发生故障时,则MASTER上的IPVS规则被删除,且BACKUP上的IPVS增加
2、当后端的realserver或相关服务发生故障时,则在MASTER上与这个realserver相应的IPVS规则会被删除
2、keepalived的主从切换时非常迅速的,一般是秒级切换。keepalived配置文件详解
keepalived的所有配置都在一个配置文件里,但是所有的配置分为3部分:
1、全局配置(Global Configuration)
全局配置是对整个keepalived都起效的配置。
2、VRRPD配置
VRRPD配置是keepalived的核心配置
3、LVS配置
只有当使用keepalived来配置和管理LVS,才需要配置LVS这部分。否则,如果使用keepalived来做HA,LVS的配置完全不需要。HA Cluster配置前提
1.本机主机名与hosts中定义的主机名保持一致,要与hostname(uname -n)获得的名称保持一致
CentOS 6:/etc/sysconfig/network
CentOS 7: hostnamectl set-hostname HOSTNAME
各节点要能够互相解析主机名,一般建议通过hosts文件进行解析(尽可能少依赖外部环境)
2.各节点时间同步
3.确保iptables及seliux不会成为服务的阻碍
virtual_ipaddress {
<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
<IP><掩码><广播地址><网卡设备><作用域(默认全局)><网卡设备别名名称>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
nopreempt:非抢占模式,默认为抢占模式
VRRPD配置VRRPD配置端也包含2部分:VRRP同步组(synchroization Group)和VRRP实例(VRRP Instance)VRRP同步组的作用是:当VRRP路由器上接2个网段时,即一个内网和一个外网。只要当其中的一个网段出现问题,都会导致keepalived发生切换时事件。如果不使用同步组的话,一旦外网发生故障,VRRP路由器仍然认为自己是健康的,因此不会发生切换事件。从而会导致问题。VRRP同步组的配置
现有两部CentOS7主机www和web1,且相互开通基于秘钥文件认证,host文件如下


此处不需要Virtual_server,故注释掉(可用:.,$s/^/#/g回车)
<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
global_defs { #全局配置
notification_email { #当出现故障时发送邮件的目的邮箱
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #指明发件人
smtp_server 192.168.200.1 #指明邮件服务器
smtp_connect_timeout 30 #连接smtp的超时时长
router_id LVS_DEVEL #物理设备的ID,最好用本机主机名
vrrp_mcast_group4 224.0.0.16 #组播地址,生产中不需要定义该项,默认即可
<<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
改为如下定义项

<<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>
vrrp_instance VI_1 { #虚拟路由实例 实例名称
state MASTER #本实例的初始状态(MASTER|BACKUP)
interface eth0 #流动的IP地址配置的网卡,自动执行,与实例绑定
virtual_router_id 51 #虚拟路由的标示符,唯一,VMAC最后一段地址
priority 100 #优先级,MASTER应高于BACKUP,数字越大越高
advert_int 1 #主节点发送心跳信息(一般通过广播或组播)的周期,默认1s
authentication { #做认证
auth_type PASS #认证方式,此处为简单字符串
auth_pass 1111 #1111:使用的字符串,建议随机生成
}
virtual_ipaddress { #虚拟IP地址,将配置在指定网卡(eth0)上或者该网卡的别名上
192.168.200.16
192.168.200.17
}
}
<<<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
编辑为如下字段:

复制到web1扔保持原文件名

修改web1的配置文件


在www上执行



启用日志功能:两台主机执行相同命令,此处只演示www主机


[root@www ~]# systemctl restart rsyslog.service


现在down掉www看看会发生什么情况:




如果想手动修改MASTER和BACKUP优先级,比如需要升级,可以通过添加一个脚本实现
# vim /etc/keepalived/keepalived.conf

[root@www ~]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'





定义同步组,在组内的多个网址是同步迁移的:(一般只有在net模型才需要)
vrrp_sync_group VG_1 {
group {
VI_1 # name of vrrp_instance (below)
VI_2 # One for each moveable IP.
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_2 {
eth1
dip
}

现有虚拟路由VI_1和VI_2,互为备份,要求当客户访问时,DNS随机轮巡分配给两个虚拟路由。若其中一个宕机,则该路由的VIP和DIP迁移至另一路由,服务不会下线
修改www的配置文件:

修改web1的配置文件

[root@www keepalived]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
[root@www keepalived]# touch down
[root@www keepalived]# ifconfig
[root@www keepalived]# tail -n 2 /var/log/keepalived.log
[root@web1 keepalived]# ifconfig
[root@web1 keepalived]# tail -n 2 /var/log/keepalived.log
[root@www keepalived]# rm -rf down
[root@www keepalived]# ifconfig
如果不成功,可能是多播地址的问题,实际生产不需要自定义,删除多播地址可解决该问题
在vi中的主机状态发生改变时发送通知:
# notify scripts, alert as above # 在vi中的主机状态繁盛改变时发送通知:
notify_master <STRING>|<QUOTED-STRING> # 只有当当前节点转换为主节点时发送指明的信息
notify_backup <STRING>|<QUOTED-STRING> # 只有当当前节点转换为backup时发送指明的信息
notify_fault <STRING>|<QUOTED-STRING> # 只有当当前节点转换为fault时发送指明的信息
notify <STRING>|<QUOTED-STRING> # 只要当前节点发生变化时就发送
smtp_alert
在www主机上编辑[root@www keepalived]# vim notify.sh 内容如下

#!/bin/bash
# Author: MageEdu <linuxedu@foxmail.com>
# description: An example of notify script
#
vip=172.16.100.1
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac
然后为notify.sh添加执行权限[root@www keepalived]# chmod +x notify.sh
[root@www keepalived]# scp -p notify.sh web1:/etc/keepalived/
编辑配置文件[root@www ~]# vim /etc/keepalived/keepalived.conf

在web1添加同样内容

[root@www keepalived]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'
然后试着down掉一台主机就会收到邮件

配置keepalived为实现haproxy高可用的配置文件示例:(需修改)
! Configuration File for keepalived
global_defs {
notification_email {
linuxedu@foxmail.com
mageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3
smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
}
vrrp_script chk_mantaince_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -2
}
vrrp_instance VI_1 {
interface eth0
state MASTER # BACKUP for slave routers
priority 101 # 100 for BACKUP
virtual_router_id 51
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.1/16 dev eth0 label eth0:0
}
track_script {
chk_haproxy
chk_mantaince_down
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
注意:
1、上面的state为当前节点的起始状态,通常在master/slave的双节点模型中,其一个默认为MASTER,而别一个默认为BACKUP。
2、priority为当关节点在当前虚拟路由器中的优先级,master的优先级应该大于slave的;
Virtual server(s)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
delay_loop <INT> 每隔多久向RS发送在线探测信息
lb_algo rr|wrr|lc|wlc|lblc|sh|dh 负载均衡支持的加密算法
ops 支持报文通过UDP发送
lb_kind NAT|DR|TUN lvs的类型
persistence_timeout <INT> 持久连接的持久时长(秒)
sorry_server <IPADDR> <PORT> 提示错误信息
real_server <IPADDR> <PORT> 定义一个虚拟服务当中的RS
weight <INT> 权重,默认1
notify_up <STRING>|<QUOTED-STRING> RS上线时邮件通知,或者靠脚本
notify_down <STRING>|<QUOTED-STRING>
# HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK
HTTP_GET|SSL_GET 应用层的两种健康状态监测,专用于该协议
url { 向哪个URL发送请求,一般需单独定义一个页面
path <STRING>
digest <STRING> 通过请求一个页面,可以计算其校验码
status_code <INT> 通过返回的状态码
nb_get_retry <INT> 重复连接的次数(如连接超时)
delay_before_retry <INT> 每次重试前等待的时间
connect_ip <IP ADDRESS> 指明连接检查的IP
connect_port <PORT> 指明连接的端口
bindto <IP ADDRESS> 在本机的哪个IP发出监测
bind_port <PORT> 发出监测的端口
指定IP和端口主要是为了方便记录日志,避免探测被记入日志
connect_timeout <INTEGER> 连接超时的时长
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< >>>>>>>>>>>>>>>>>>>>>>>>>>>>

现有四部主机,如上图所示四部主机www、web1、web2、web3
先查看RS1和RS2的httpd包并提供主页面


启动httpd服务,查看端口确认已启动

尝试访问两台RS确认一下
然后在两台Dr安装ipvsadm包# yum -y install ipvsadm
在web2上:# vim 1.sh


复制一份到web3执行相同操作
[root@web2 ~]# scp 1.sh web3:/root
[root@web3 ~]# bash 1.sh start
添加IP:
[root@web3 ~]# ifconfig lo:0 192.168.3.13 netmask 255.255.255.255 broadcast 192.168.3.13 up
添加路由
[root@web3 ~]# route add -host 192.168.3.13 dev lo:0
[root@web2 ~]# ifconfig lo:0 192.168.3.13 netmask 255.255.255.255 broadcast 192.168.3.13 up
[root@web2 ~]# route add -host 192.168.3.13 dev lo:0
下面分别测试两台Dr主机是否能正常调度ipvs规则
为www主机添加IP地址或编辑网卡(本实例采用添加IP地址的方式实现)
[root@www ~]# ip addr add 192.168.3.13/32 dev eno16777736
[root@www ~]# ip addr list
为确认可以找其他主机ping一下
在www定义ipvs规则


证明调度有效,清空所有规则:[root@www ~]# ipvsadm -C
清空IP地址

web1主机相同方法测试,在此不细表
以下请忽略网卡命名方式,已改为回归传统命名
keepalived:
HTTP_GET
SSL_GET(https)
TCP_CHECK
示例:
下面为两台Dr分别执行下面三条命令,安装httpd服务,提供sorry-server
# yum -y install httpd
# echo "<h1> Sorry, under maintenance mode</h1>" > /var/www/html/index.html(可稍加区别)
# systemctl start httpd.service
保险起见可以测试一下
# yum -y install keepalived
然后配置两台主机的配置文件:

下图是keepalived.conf的配置:(提示:一个空格都不能少)





启动服务
[root@www keepalived]# systemctl start keepalived.service; ssh web1 'systemctl start keepalived.service'
抓包查看:注意不要在本机抓包
[root@www keepalived]# tcpdump -i eth0:0 -nn host 192.168.2.18
[root@web1 keepalived]# tcpdump -i eth0:0 -nn host 192.168.2.16
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig


现在VIP不在web1上,则web1的规则不生效
此时可以看到新邮件已经出现
请求页面出现如下结果

也可以尝试touch down,IP会流转
此时若down掉web2或web3会只剩下一个可访问;若再次上线,稍后会重新被加载,这就是健康监测机制
若web2和web3同时下线,我们就需要一个sorry_server,在两个Dr上编辑keepalived.conf

此时down掉web2和web3则显示sorry_server页面
[root@web2 ~]# service stop httpd
[root@web3 ~]# service httpd stop


<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
TCP_CHECK 用于virtual_server中
connect_ip <IP ADDRESS> 指明连接检查的IP,不指明则默认使用RSIP
connect_port <PORT> 指明连接的端口,不指明则默认使用80
bindto <IP ADDRESS> 在本机的哪个接口发出监测
bind_port <PORT> 发出监测的端口
connect_timeout <INTEGER> 连接超时的时长
<<<<<<<<<<<<<<<<<<<<<<<<< >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
分别修改两台Dr的keepalived.conf如图:


因此时没有RS在线,所以显示sorry_server,现在任意上线一台RS
[root@web2 ~]# service httpd start

配置keepalived高可用,首先最好将当前keepalived配置文件备份一个备用
首先将所有程序恢复初始,即四台主机,www,web1,web2,web3,www和web1为centos7,web2和web3为centos6,相互之间采用秘钥文件认证
首先为web2和web3安装httpd服务并提供主页,为www和web1提供nginx服务
接着配置www上的nginx为反向代理[root@www ~]# vim /etc/nginx/nginx.conf

[root@www ~]# nginx -t 检查一下语法
[root@www ~]# systemctl disable httpd.service 免得二者争用端口
[root@www ~]# systemctl start nginx.service
[root@www ~]# netstat -tnlp
最后尝试访问以下nginx看看反代结果
[root@www nginx]# scp nginx.conf web1:/etc/nginx
[root@web1 ~]# systemctl start nginx.service
[root@web1 ~]# systemctl disable httpd
[root@web1 ~]# netstat -tnlp
再次尝试访问web1看看结果
然后在www和web1上分别安装并配置keeplived
VIP在哪个主机,哪个主机就是负载均衡器,那么,若nginx出现问题,VIP如果依然指向本机,服务依然无法正常访问,那么就需要一种机制,一旦nginx服务不能正常访问,就让keepalived优先级降低,这种方式可以通过让keepalived监控nginx是否能够正常访问来作为判断标准,由此,下面来尝试通过脚本实现
提示:如下图


kiall -0 PROCESS 就是查看进程是否正常在线,那么就可以作为判断本机上nginx服务是否在线的基本标准
[root@www ~]# vim /etc/keepalived/keepalived.conf

[root@www keepalived]# scp keepalived.conf web1:/etc/keepalived/
[root@web1 ~]# cd /etc/keepalived/
[root@web1 keepalived]# vim keepalived.conf

notify.sh文件同上
[root@www keepalived]# systemctl start keepalived.service; ssh web1 'systemctl start keepalived.service'
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
查看日志:# systemctl status keepalived.service可以看到已经可以检测nginx信息
web访问192.168.3.13已经可以访问,并基于rr调调度
[root@www keepalived]# systemctl stop nginx.service

[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
再次通过WEB访问可查看结果正常

[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
可再次通过WEB访问查看
但是这样就必须保证nginx服务始终处于运行状态,因一旦nginx停止,keepalived的权限就会降低,这时当备节点故障,主节点无法重新运行,那么,修改notify.sh(两个节点)如下图
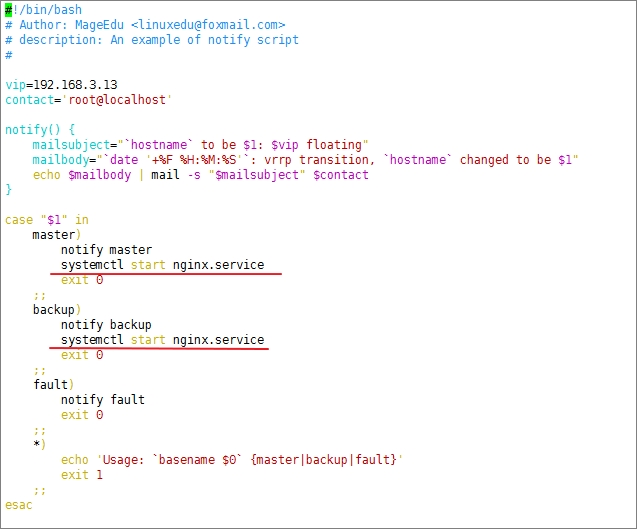

此时若强制停止主节点nginx
[root@www keepalived]# systemctl stop nginx.service; systemctl start httpd.service
稍等一会,备用节点就会启动了

此时,停掉主节点的httpd服务依然没用,之后再停掉备用节点的nginx,就会重新选举


此时nginx仍然是单主模式,那么下面来定义双主模式
[root@www keepalived]# vim keepalived.conf
添加一个vrrp_instance如下图

web1节点也要添加,但要作为MASTER

此时nginx是否在线已不能作为评判标准,所以修改两个nogify.sh如图



若不成功请尝试多重启一次服务,此时双主模型已经实现,两个VIP都可以实现访问
此时若www宕机


此时再次访问两个VIP依然没问题,只不过通过同一主机调度,手动启动www上的nginx

[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
配置keepalived为实现haproxy高可用的双主模型配置文件示例:
说明:其基本实现思想为创建两个虚拟路由器,并以两个节点互为主从。
! Configuration File for keepalived
global_defs {
notification_email {
linuxedu@foxmail.com
mageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3
smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
}
vrrp_script chk_mantaince_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight 2
}
vrrp_instance VI_1 {
interface eth0
state MASTER # BACKUP for slave routers
priority 101 # 100 for BACKUP
virtual_router_id 51
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.1/16 dev eth0 label eth0:0
}
track_script {
chk_haproxy
chk_mantaince_down
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
interface eth0
state BACKUP # BACKUP for slave routers
priority 100 # 100 for BACKUP
virtual_router_id 52
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.2/16 dev eth0 label eth0:1
}
track_script {
chk_haproxy
chk_mantaince_down
}
}
说明:
1、对于VI_1和VI_2来说,两个节点要互为主从关系;
HA Services:
nginx
keepalived中文文档:
http://yunpan.cn/cFHTsspFZVfCp 访问密码 bfa2
LB:lvs,nginx
HA:Keepalived,heartbeat,corosync,cman
HP:高性能集群
并行处理:
分布式存储:HDFS:
分布式计算:YARN
batch:MapReduce
in-memory:spark
stream:sotrm 流式处理系统
Keepalived:
keepalived简介
keepalived是一个基于VRRP协议来实现IPVS的高可用的解决方案。对于LVS负载均衡来说,如果前端的调度器direct发生故障,则后端的realserver是无法接受请求并响应的。因此,保证前端direct的高可用性是非常关键的,否则后端的服务器是无法进行服务的。而我们的keepalived就可以用来解决单点故障(如LVS的前端direct故障)问题。keepalived的主要工作原理是:运行keepalived的两台服务器,其中一台为MASTER,另一台为BACKUP,正常情况下,所有的数据转换功能和ARP请求响应都是由MASTER开完成的,一旦MASTER发生故障,则BACKUP会马上接管MASTER的工作,这种切换时非常迅速的。
并且MASTER和BACKUP组成一个虚拟服务器,虚拟服务器有一个虚拟IP地址和一个虚拟MAC地址,这个虚拟IP地址就是对外服务的地址,虚拟IP地址总是运行在MASTER上。因此即便是MASTER发生故障,则BACKUP也参加竞选成为MASTER,因此也就具备了虚拟IP地址,继续向外提供服务。而keepalived之所以能够实现高可用功能,完全是因为它是基于VRRP协议来工作的,因此VRRP协议是keepalived的核心。所在在说keepalived之前,还是先来了解下VRRP协议吧。
VRRP协议
VRRP协议叫做虚拟路由冗余协议,从它的名称就可以知道它是用来提供冗余功能的。它是为了解决静态路由单点故障而设计的一个主从模式的协议,一旦MASTER节点发生故障,其该节点上的服务和IP地址会立刻转移到BACKUP节点上,从而继续提供高可用性。对于了解网络的朋友,都知道在设计网络的时候,必须要考虑到网络的冗余,这里的冗余指的是设备冗余。否则,一旦某一个单点路由器发生故障,其下行所有用户都不能上网了,这种现象是非常严重的。
而VRRP协议却可以很好的解决这个问题。VRRP协议设计的思想就是将多个物理路由器虚拟成一个路由器。这个路由器我们称作为虚拟路由器。虚拟路由器上有一个IP地址,叫做虚拟IP地址。这个虚拟IP地址是向外提供某种服务的地址或者当做某些主机或节点的网关地址。在这多个物理路由器上,拥有这个虚拟IP地址的路由器叫做MASTER路由器,其他的则是BACKUP路由器。只有MASTER路由器才能接受和转发数据,BACKUP路由器是不能转发数据的。对于谁能够成为MASTER路由器,需要根据每个路由器自身的优先级来判断的。对于虚拟路由器而言,只要有一台物理路由器是正常的,则虚拟路由器永远都不会发生故障,因此,即便MASTER路由器发生故障,其他的BACKUP也会立即参加竞选成为MASTER,从而继续提供数据转发功能和保证网络的连续性。
VRRP路由器
在这里先解释一下,这里所说的路由器在linux系统下则叫做服务器或者节点,而在网络中,专业的叫法则是称作为路由器。叫法虽不同,但是表达的都是一个意思。
VRRP路由器就是一台物理路由器,只是这台路由器上面运行了vrrp协议或者VRRPD程序。一台VRRP路由器可以位于多个虚拟路由器中。
虚拟路由器
虚拟路由器就是将多个VRRP路由器通过某种方式组成一个路由器,既然是虚拟的,就是说并不是实际存在的。虚拟路由器的标识符叫做虚拟路由器ID(VRID),其ID范围是0-255。
VRRP实例
VRRP实例就是提供某种相同服务或相同路由的一组路由器,每一个组就是一个实例。
MASTER和BACKUP
在一个虚拟路由器中,有多个VRRP路由器,这些VRRP路由器中又有一个叫做MASTER路由器,其他的则叫做BACKUP路由器。当VRRP协议在每一个物理路由器上初始启动时,则所有的路由器都会发送VRRP通告信息,且都会参加竞选成为MASTER路由器。其中每一个路由器都有一个priority,priority最大的路由器将会成为MASTER路由器,其他的则是BACKUP路由器。如果priority相同,则每个路由器上IP地址最大的路由器将会成为MASTER路由器。
MASTER路由器拥有虚拟IP地址,且负责响应ARP报文请求和转发数据。BACKUP只能接受VRRP报文通告。它不会抢占成为MASTER,除非它有更高的优先级。
VRRP协议的工作机制
VRRP路由器是通过竞选协议来实现虚拟路由器功能的,所有的VRRP报文都是通过多播的形式向外发送。虚拟路由器是由虚拟路由器ID(VRID)和虚拟IP地址组成的。虚拟路由器上有一个虚拟的MAC地址,其地址格式为:00-00-5E-00-01-{VRID}。所以,不管谁是MASTER路由器,其对外提供服务的IP(为VIP)和MAC地址(为虚拟MAC地址)都是相同的。客户端并不会因为MASTER的改变而改变,对他们来说,这种主从切换时透明的。
默认情况下,竞选成功后,只有MASTER路由器能够发送通告信息,且每个1秒钟发送一次。如果BACKUP路由器在这段时间内,没有收到MASTER路由器的VRRP通告信息,则认为MASTER路由器宕机,则BACKUP路由器中优先级最高的路由器会抢占成为为新的MASTER路由器。当然也可以通过VRRP接口跟踪功能来改变路由器的优先级以便让最高优先级的路由器成为MASTER。它的跟踪机制是:如果MASTER上监控的某个接口发生故障,则MASTER的priority值会相应降低,且降低后的priority值一定要小于BACKUP上的priority值。这样才可以保证,其他的BACKUP能够抢占成为新的MASTER路由器。
由于出于安全性的考虑,因此,MASTER和BACKUP之间的数据是加密传输的。
VRRP的主从模式
在这种模式下,只有一个MASTER,其他的则作为BACKUP。其中MASTER负责数据转发和响应ARP请求。
VRRP双主模式
在这种模式下,两台路由器都是MASTER路由器,每一台路由器上都运行着2个服务,其中每一台路由器即充当这个服务中的MASTER路由器又充当另一个服务的BACKUP路由器。在这种模式下,可以实现流量负载共享功能,即可以在多个设备上转发数据。
例如:有2个路由器,分别是server1和server2,且这两个路由器都运行着httpd和mysqld服务,对于server1来说,它即充当着httpd服务中的MASTER,又充当着mysqld服务中的BACKUP服务器。而server2即充当着mysqld服务中的MASTER,又充当着httpd服务中的BACKUP服务。
VRRP中的ARP处理机制
在VRRP协议中,只有MASTER才能够响应ARP请求,因此,当MASTER收到ARP请求时,它响应的是虚拟mac地址,而不是实际的物理机mac地址。因此,不管那台服务器作为MASTER其虚拟MAC地址都不会变,所以对于对端本机而言,其通信的目标mac地址仍然是虚拟mac地址,它是不会发生改变的。因此也就不会影响到对端主机的通信了。
VRRP的优势:
冗余性:可以使用多个路由器设备作为LAN客户端的默认网关,大大降低了默认网关成为单点故障的可能性;
负载共享:允许来自LAN客户端的流量由多个路由器设备所共享;
多VRRP组:在一个路由器物理接口上可配置多达255个VRRP组,每一个组就是一个实例;
多IP地址:基于接口别名在同一个物理接口上配置多个IP地址,从而支持在同一个物理接口上接入多个子网;
抢占:在master故障时允许优先级更高的backup成为master;
通告协议:使用IANA所指定的组播地址224.0.0.18进行VRRP通告;
VRRP接口追踪:基于接口状态来改变其VRRP优先级来确定最佳的VRRP路由器成为master;
Active/Passive(backup)
在多个节点提供相同服务,可能需要多个组件,入口
lvs:vip, ipvs rules
nginx: IP, nginx server
resource, 高可用集群中的资源
HA Service:resources
时间同步:
ntp协议:network time protocol
CentOS7上已经有替换版本
课外内容:如何实现时间同步
Keepalived:
vrrp协议在linux主机上以守护进程方式的额实现
能够根据配置文件自动生成ipvs规则
对各RS做健康状态监测:
组件:
vrrp stack
checkers
ipvs wapper --> ipvs
配置和使用Keepalived:
keepalived实现高可用服务具有的特性
1、在keepalived实现IPVS的高可用服务中,当MASETR发生故障时,则MASTER上的IPVS规则被删除,且BACKUP上的IPVS增加
2、当后端的realserver或相关服务发生故障时,则在MASTER上与这个realserver相应的IPVS规则会被删除
2、keepalived的主从切换时非常迅速的,一般是秒级切换。keepalived配置文件详解
keepalived的所有配置都在一个配置文件里,但是所有的配置分为3部分:
1、全局配置(Global Configuration)
全局配置是对整个keepalived都起效的配置。
2、VRRPD配置
VRRPD配置是keepalived的核心配置
3、LVS配置
只有当使用keepalived来配置和管理LVS,才需要配置LVS这部分。否则,如果使用keepalived来做HA,LVS的配置完全不需要。HA Cluster配置前提
1.本机主机名与hosts中定义的主机名保持一致,要与hostname(uname -n)获得的名称保持一致
CentOS 6:/etc/sysconfig/network
CentOS 7: hostnamectl set-hostname HOSTNAME
各节点要能够互相解析主机名,一般建议通过hosts文件进行解析(尽可能少依赖外部环境)
2.各节点时间同步
3.确保iptables及seliux不会成为服务的阻碍
virtual_ipaddress {
<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
<IP><掩码><广播地址><网卡设备><作用域(默认全局)><网卡设备别名名称>
192.168.200.17/24 dev eth1
192.168.200.18/24 dev eth2 label eth2:1
}
nopreempt:非抢占模式,默认为抢占模式
VRRPD配置VRRPD配置端也包含2部分:VRRP同步组(synchroization Group)和VRRP实例(VRRP Instance)VRRP同步组的作用是:当VRRP路由器上接2个网段时,即一个内网和一个外网。只要当其中的一个网段出现问题,都会导致keepalived发生切换时事件。如果不使用同步组的话,一旦外网发生故障,VRRP路由器仍然认为自己是健康的,因此不会发生切换事件。从而会导致问题。VRRP同步组的配置
现有两部CentOS7主机www和web1,且相互开通基于秘钥文件认证,host文件如下
此处不需要Virtual_server,故注释掉(可用:.,$s/^/#/g回车)
<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
global_defs { #全局配置
notification_email { #当出现故障时发送邮件的目的邮箱
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc #指明发件人
smtp_server 192.168.200.1 #指明邮件服务器
smtp_connect_timeout 30 #连接smtp的超时时长
router_id LVS_DEVEL #物理设备的ID,最好用本机主机名
vrrp_mcast_group4 224.0.0.16 #组播地址,生产中不需要定义该项,默认即可
<<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
改为如下定义项
<<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>
vrrp_instance VI_1 { #虚拟路由实例 实例名称
state MASTER #本实例的初始状态(MASTER|BACKUP)
interface eth0 #流动的IP地址配置的网卡,自动执行,与实例绑定
virtual_router_id 51 #虚拟路由的标示符,唯一,VMAC最后一段地址
priority 100 #优先级,MASTER应高于BACKUP,数字越大越高
advert_int 1 #主节点发送心跳信息(一般通过广播或组播)的周期,默认1s
authentication { #做认证
auth_type PASS #认证方式,此处为简单字符串
auth_pass 1111 #1111:使用的字符串,建议随机生成
}
virtual_ipaddress { #虚拟IP地址,将配置在指定网卡(eth0)上或者该网卡的别名上
192.168.200.16
192.168.200.17
}
}
<<<<<<<<<<<<<<<<<<<<<<<<<<<>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
编辑为如下字段:
复制到web1扔保持原文件名
修改web1的配置文件
在www上执行
启用日志功能:两台主机执行相同命令,此处只演示www主机
[root@www ~]# systemctl restart rsyslog.service
现在down掉www看看会发生什么情况:
如果想手动修改MASTER和BACKUP优先级,比如需要升级,可以通过添加一个脚本实现
# vim /etc/keepalived/keepalived.conf
[root@www ~]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'
定义同步组,在组内的多个网址是同步迁移的:(一般只有在net模型才需要)
vrrp_sync_group VG_1 {
group {
VI_1 # name of vrrp_instance (below)
VI_2 # One for each moveable IP.
}
}
vrrp_instance VI_1 {
eth0
vip
}
vrrp_instance VI_2 {
eth1
dip
}
现有虚拟路由VI_1和VI_2,互为备份,要求当客户访问时,DNS随机轮巡分配给两个虚拟路由。若其中一个宕机,则该路由的VIP和DIP迁移至另一路由,服务不会下线
修改www的配置文件:
修改web1的配置文件
[root@www keepalived]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
[root@www keepalived]# touch down
[root@www keepalived]# ifconfig
[root@www keepalived]# tail -n 2 /var/log/keepalived.log
[root@web1 keepalived]# ifconfig
[root@web1 keepalived]# tail -n 2 /var/log/keepalived.log
[root@www keepalived]# rm -rf down
[root@www keepalived]# ifconfig
如果不成功,可能是多播地址的问题,实际生产不需要自定义,删除多播地址可解决该问题
在vi中的主机状态发生改变时发送通知:
# notify scripts, alert as above # 在vi中的主机状态繁盛改变时发送通知:
notify_master <STRING>|<QUOTED-STRING> # 只有当当前节点转换为主节点时发送指明的信息
notify_backup <STRING>|<QUOTED-STRING> # 只有当当前节点转换为backup时发送指明的信息
notify_fault <STRING>|<QUOTED-STRING> # 只有当当前节点转换为fault时发送指明的信息
notify <STRING>|<QUOTED-STRING> # 只要当前节点发生变化时就发送
smtp_alert
在www主机上编辑[root@www keepalived]# vim notify.sh 内容如下
#!/bin/bash
# Author: MageEdu <linuxedu@foxmail.com>
# description: An example of notify script
#
vip=172.16.100.1
contact='root@localhost'
notify() {
mailsubject="`hostname` to be $1: $vip floating"
mailbody="`date '+%F %H:%M:%S'`: vrrp transition, `hostname` changed to be $1"
echo $mailbody | mail -s "$mailsubject" $contact
}
case "$1" in
master)
notify master
exit 0
;;
backup)
notify backup
exit 0
;;
fault)
notify fault
exit 0
;;
*)
echo 'Usage: `basename $0` {master|backup|fault}'
exit 1
;;
esac
然后为notify.sh添加执行权限[root@www keepalived]# chmod +x notify.sh
[root@www keepalived]# scp -p notify.sh web1:/etc/keepalived/
编辑配置文件[root@www ~]# vim /etc/keepalived/keepalived.conf
在web1添加同样内容
[root@www keepalived]# systemctl restart keepalived.service; ssh web1 'systemctl restart keepalived.service'
然后试着down掉一台主机就会收到邮件
配置keepalived为实现haproxy高可用的配置文件示例:(需修改)
! Configuration File for keepalived
global_defs {
notification_email {
linuxedu@foxmail.com
mageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3
smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
}
vrrp_script chk_mantaince_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight -2
}
vrrp_instance VI_1 {
interface eth0
state MASTER # BACKUP for slave routers
priority 101 # 100 for BACKUP
virtual_router_id 51
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.1/16 dev eth0 label eth0:0
}
track_script {
chk_haproxy
chk_mantaince_down
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
注意:
1、上面的state为当前节点的起始状态,通常在master/slave的双节点模型中,其一个默认为MASTER,而别一个默认为BACKUP。
2、priority为当关节点在当前虚拟路由器中的优先级,master的优先级应该大于slave的;
Virtual server(s)
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
delay_loop <INT> 每隔多久向RS发送在线探测信息
lb_algo rr|wrr|lc|wlc|lblc|sh|dh 负载均衡支持的加密算法
ops 支持报文通过UDP发送
lb_kind NAT|DR|TUN lvs的类型
persistence_timeout <INT> 持久连接的持久时长(秒)
sorry_server <IPADDR> <PORT> 提示错误信息
real_server <IPADDR> <PORT> 定义一个虚拟服务当中的RS
weight <INT> 权重,默认1
notify_up <STRING>|<QUOTED-STRING> RS上线时邮件通知,或者靠脚本
notify_down <STRING>|<QUOTED-STRING>
# HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK
HTTP_GET|SSL_GET 应用层的两种健康状态监测,专用于该协议
url { 向哪个URL发送请求,一般需单独定义一个页面
path <STRING>
digest <STRING> 通过请求一个页面,可以计算其校验码
status_code <INT> 通过返回的状态码
nb_get_retry <INT> 重复连接的次数(如连接超时)
delay_before_retry <INT> 每次重试前等待的时间
connect_ip <IP ADDRESS> 指明连接检查的IP
connect_port <PORT> 指明连接的端口
bindto <IP ADDRESS> 在本机的哪个IP发出监测
bind_port <PORT> 发出监测的端口
指定IP和端口主要是为了方便记录日志,避免探测被记入日志
connect_timeout <INTEGER> 连接超时的时长
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< >>>>>>>>>>>>>>>>>>>>>>>>>>>>
现有四部主机,如上图所示四部主机www、web1、web2、web3
先查看RS1和RS2的httpd包并提供主页面
启动httpd服务,查看端口确认已启动
尝试访问两台RS确认一下
然后在两台Dr安装ipvsadm包# yum -y install ipvsadm
在web2上:# vim 1.sh
复制一份到web3执行相同操作
[root@web2 ~]# scp 1.sh web3:/root
[root@web3 ~]# bash 1.sh start
添加IP:
[root@web3 ~]# ifconfig lo:0 192.168.3.13 netmask 255.255.255.255 broadcast 192.168.3.13 up
添加路由
[root@web3 ~]# route add -host 192.168.3.13 dev lo:0
[root@web2 ~]# ifconfig lo:0 192.168.3.13 netmask 255.255.255.255 broadcast 192.168.3.13 up
[root@web2 ~]# route add -host 192.168.3.13 dev lo:0
下面分别测试两台Dr主机是否能正常调度ipvs规则
为www主机添加IP地址或编辑网卡(本实例采用添加IP地址的方式实现)
[root@www ~]# ip addr add 192.168.3.13/32 dev eno16777736
[root@www ~]# ip addr list
为确认可以找其他主机ping一下
在www定义ipvs规则
证明调度有效,清空所有规则:[root@www ~]# ipvsadm -C
清空IP地址
web1主机相同方法测试,在此不细表
以下请忽略网卡命名方式,已改为回归传统命名
keepalived:
HTTP_GET
SSL_GET(https)
TCP_CHECK
示例:
下面为两台Dr分别执行下面三条命令,安装httpd服务,提供sorry-server
# yum -y install httpd
# echo "<h1> Sorry, under maintenance mode</h1>" > /var/www/html/index.html(可稍加区别)
# systemctl start httpd.service
保险起见可以测试一下
# yum -y install keepalived
然后配置两台主机的配置文件:
下图是keepalived.conf的配置:(提示:一个空格都不能少)
启动服务
[root@www keepalived]# systemctl start keepalived.service; ssh web1 'systemctl start keepalived.service'
抓包查看:注意不要在本机抓包
[root@www keepalived]# tcpdump -i eth0:0 -nn host 192.168.2.18
[root@web1 keepalived]# tcpdump -i eth0:0 -nn host 192.168.2.16
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
现在VIP不在web1上,则web1的规则不生效
此时可以看到新邮件已经出现
请求页面出现如下结果
也可以尝试touch down,IP会流转
此时若down掉web2或web3会只剩下一个可访问;若再次上线,稍后会重新被加载,这就是健康监测机制
若web2和web3同时下线,我们就需要一个sorry_server,在两个Dr上编辑keepalived.conf
此时down掉web2和web3则显示sorry_server页面
[root@web2 ~]# service stop httpd
[root@web3 ~]# service httpd stop
<<<<<<<<<<<<<<<<<<<<<<部分解释>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
TCP_CHECK 用于virtual_server中
connect_ip <IP ADDRESS> 指明连接检查的IP,不指明则默认使用RSIP
connect_port <PORT> 指明连接的端口,不指明则默认使用80
bindto <IP ADDRESS> 在本机的哪个接口发出监测
bind_port <PORT> 发出监测的端口
connect_timeout <INTEGER> 连接超时的时长
<<<<<<<<<<<<<<<<<<<<<<<<< >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
分别修改两台Dr的keepalived.conf如图:
因此时没有RS在线,所以显示sorry_server,现在任意上线一台RS
[root@web2 ~]# service httpd start
配置keepalived高可用,首先最好将当前keepalived配置文件备份一个备用
首先将所有程序恢复初始,即四台主机,www,web1,web2,web3,www和web1为centos7,web2和web3为centos6,相互之间采用秘钥文件认证
首先为web2和web3安装httpd服务并提供主页,为www和web1提供nginx服务
接着配置www上的nginx为反向代理[root@www ~]# vim /etc/nginx/nginx.conf
[root@www ~]# nginx -t 检查一下语法
[root@www ~]# systemctl disable httpd.service 免得二者争用端口
[root@www ~]# systemctl start nginx.service
[root@www ~]# netstat -tnlp
最后尝试访问以下nginx看看反代结果
[root@www nginx]# scp nginx.conf web1:/etc/nginx
[root@web1 ~]# systemctl start nginx.service
[root@web1 ~]# systemctl disable httpd
[root@web1 ~]# netstat -tnlp
再次尝试访问web1看看结果
然后在www和web1上分别安装并配置keeplived
VIP在哪个主机,哪个主机就是负载均衡器,那么,若nginx出现问题,VIP如果依然指向本机,服务依然无法正常访问,那么就需要一种机制,一旦nginx服务不能正常访问,就让keepalived优先级降低,这种方式可以通过让keepalived监控nginx是否能够正常访问来作为判断标准,由此,下面来尝试通过脚本实现
提示:如下图
kiall -0 PROCESS 就是查看进程是否正常在线,那么就可以作为判断本机上nginx服务是否在线的基本标准
[root@www ~]# vim /etc/keepalived/keepalived.conf
[root@www keepalived]# scp keepalived.conf web1:/etc/keepalived/
[root@web1 ~]# cd /etc/keepalived/
[root@web1 keepalived]# vim keepalived.conf
notify.sh文件同上
[root@www keepalived]# systemctl start keepalived.service; ssh web1 'systemctl start keepalived.service'
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
查看日志:# systemctl status keepalived.service可以看到已经可以检测nginx信息
web访问192.168.3.13已经可以访问,并基于rr调调度
[root@www keepalived]# systemctl stop nginx.service
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
再次通过WEB访问可查看结果正常
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
可再次通过WEB访问查看
但是这样就必须保证nginx服务始终处于运行状态,因一旦nginx停止,keepalived的权限就会降低,这时当备节点故障,主节点无法重新运行,那么,修改notify.sh(两个节点)如下图
此时若强制停止主节点nginx
[root@www keepalived]# systemctl stop nginx.service; systemctl start httpd.service
稍等一会,备用节点就会启动了
此时,停掉主节点的httpd服务依然没用,之后再停掉备用节点的nginx,就会重新选举
此时nginx仍然是单主模式,那么下面来定义双主模式
[root@www keepalived]# vim keepalived.conf
添加一个vrrp_instance如下图
web1节点也要添加,但要作为MASTER
此时nginx是否在线已不能作为评判标准,所以修改两个nogify.sh如图
若不成功请尝试多重启一次服务,此时双主模型已经实现,两个VIP都可以实现访问
此时若www宕机
此时再次访问两个VIP依然没问题,只不过通过同一主机调度,手动启动www上的nginx
[root@www keepalived]# ifconfig
[root@web1 keepalived]# ifconfig
配置keepalived为实现haproxy高可用的双主模型配置文件示例:
说明:其基本实现思想为创建两个虚拟路由器,并以两个节点互为主从。
! Configuration File for keepalived
global_defs {
notification_email {
linuxedu@foxmail.com
mageedu@126.com
}
notification_email_from kanotify@magedu.com
smtp_connect_timeout 3
smtp_server 127.0.0.1
router_id LVS_DEVEL
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 1
weight 2
}
vrrp_script chk_mantaince_down {
script "[[ -f /etc/keepalived/down ]] && exit 1 || exit 0"
interval 1
weight 2
}
vrrp_instance VI_1 {
interface eth0
state MASTER # BACKUP for slave routers
priority 101 # 100 for BACKUP
virtual_router_id 51
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.1/16 dev eth0 label eth0:0
}
track_script {
chk_haproxy
chk_mantaince_down
}
notify_master "/etc/keepalived/notify.sh master"
notify_backup "/etc/keepalived/notify.sh backup"
notify_fault "/etc/keepalived/notify.sh fault"
}
vrrp_instance VI_2 {
interface eth0
state BACKUP # BACKUP for slave routers
priority 100 # 100 for BACKUP
virtual_router_id 52
garp_master_delay 1
authentication {
auth_type PASS
auth_pass password
}
track_interface {
eth0
}
virtual_ipaddress {
172.16.100.2/16 dev eth0 label eth0:1
}
track_script {
chk_haproxy
chk_mantaince_down
}
}
说明:
1、对于VI_1和VI_2来说,两个节点要互为主从关系;
HA Services:
nginx
keepalived中文文档:
http://yunpan.cn/cFHTsspFZVfCp 访问密码 bfa2

相关文章推荐
- autofs配置小结
- OpenCV-图像的基本操作
- 使用sudo时user is not in sudoers file的解决
- PostgreSQL psql: could not connect to server: Connection refused
- 多行条件判断
- 5-28 猴子选大王
- Android中保存和恢复Fragment状态的最好方法-1
- 黑马程序员-C语言的输入函数
- 解决Windows和Ubuntu时间不一致的问题
- 在手机内存储器中读取字符文件
- Struts1的bean:write标签无法输出int、float等数据类型的解决情况
- 汇编学习笔记---(1)基础知识
- RAC手动中断订阅
- 每天一个Linux命令(2): ls
- 转载 intellij IDEA 使用体验 (本人感觉它的使用是一种趋势)
- Android_08_使用服务注册广播
- 5-36 复数四则运算
- <base>标签在html5中使用时……
- mitmproxy加密数据分析
- Can't load IA 32-bit .dll on a AMD 64-bit platform