《Scuba: Diving into Data at Facebook》阅读笔记
2015-10-18 23:56
351 查看
《Scuba: Diving into Data at Facebook》阅读笔记
论文着重点
系统的数据模型响应时间
背景
scuba主要是存储用作数据分析、出报表的日志的,基于这一点,使得scuba拥有以下特性:1. 响应时间必须快,不然相关人员发起一个查询,要半天才能给出结果,非常影响效率
2. 可以允许丢失数据。由于数据量大,丢失少量数据并不影响结果。
3. 体验好。包括提供的API,GUI界面等。
数据模型
表结构根据日志自动生成,因此并没有创建表的语句。不同的分表表结构可能不一致,有些字段这个分表有,那个分表没有。这个没关系,如果遇到没有的字段,通通当做null值处理。
表的schema可以根据用户的需求自动调整。
It is common for there to be 2 or 3 different row schemas within a table or for a column to change its type overtime. Together, these two differences let Scuba adapt tables to the needs of its users without any complex schema evolution commands or workflows. Such adaptation is one of Scuba’s strengths.
架构
查询使用的是aggregation tree结构。节点大概可以分两种角色(更细可以分为四种):aggregator和leaf node。leaf node是执行实际的查询,则aggregator是将查询归并。而aggregator则可以分为root aggregator、intermediate aggregator和leaf aggregator。值得注意的是,每一个aggregator必然是leaf aggregator,但是也可以当root aggregator和intermediate aggregator。这样,就解决了intermediate aggregator和root aggregator但单点得问题了。实际部署的时候,一台物理机器上部署8个leaf node和一个leaf aggregator。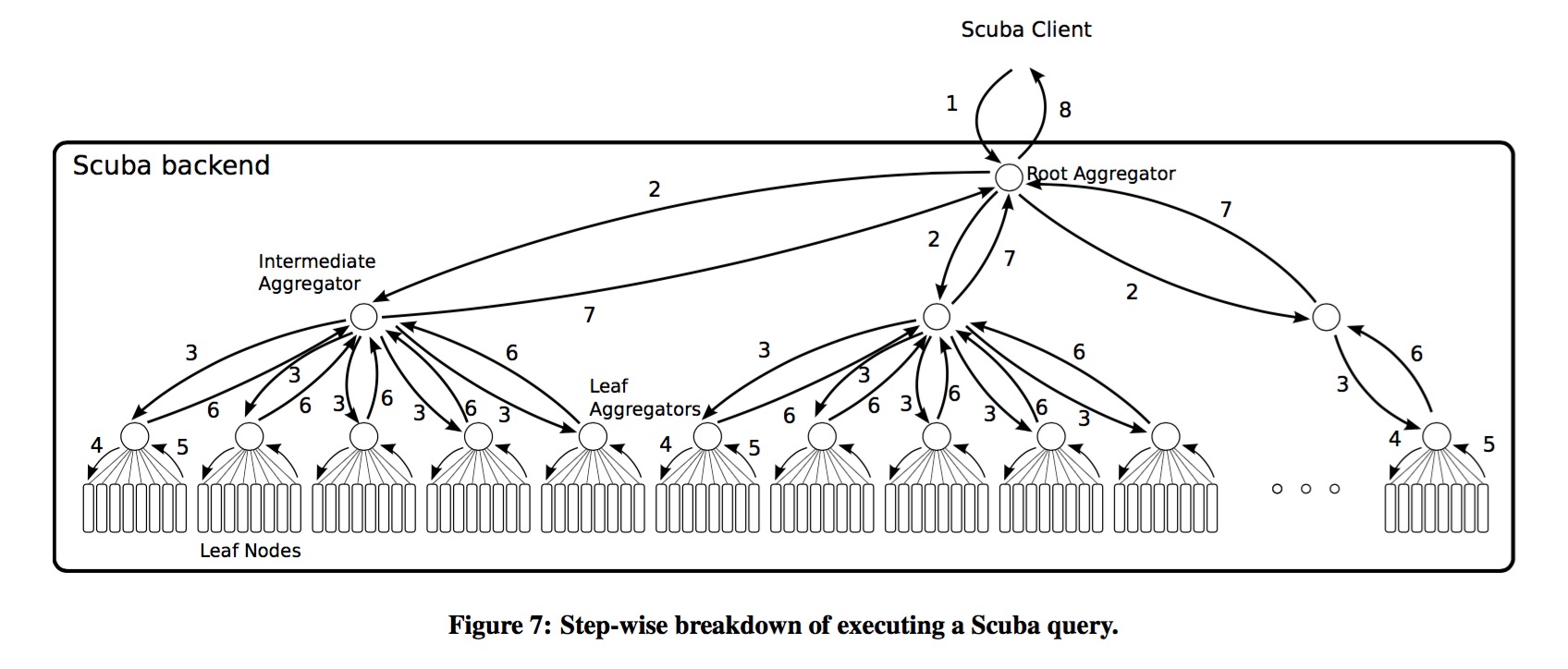
response time
主要是对aggregator节点的fan out做了实验,得出最优的fan out为5. 另外有一个重要的结论:在其它条件不变的情况下,不管集群怎么扩容,查询时间总是固定的(见下图)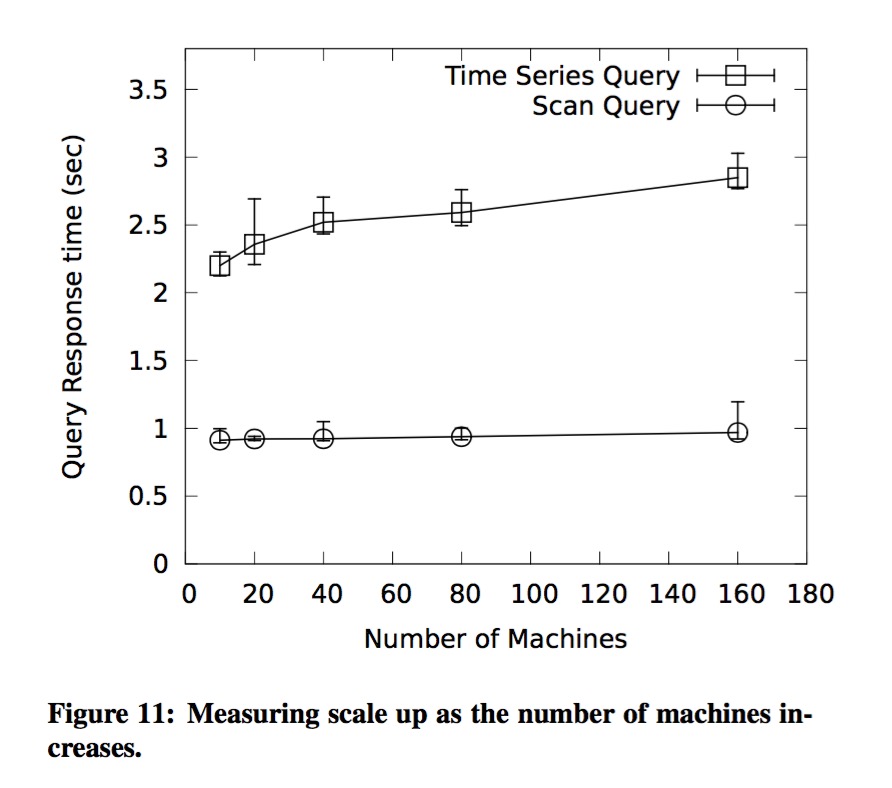
一些有意思的功能
过期时间由于scuba里面存得只是一些用来做分析的日志数据,只需要保存一段时间。因此scuba给每一个数据行都增加了一个过期时间,过期自动删除数据。
采样
为了追求更加快得查询时间,可以只选取一小部分的数据进行查询。
压缩
scuba实现了对数据的压缩,但是还待优化。

相关文章推荐
- Android之获取手机上的图片和视频缩略图thumbnails
- 数据库链接字符串查询网站
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- Facebook's New Real-time Messaging System: HBase to Store 135+ Billion Messages a Month
- DB2实例管理
- DB2实例管理
- 保障MySQL数据安全的14个最佳方法
- mysql问答汇集
- Facebook获得TechCrunch Crunchies 2009最佳奖
- AS3自写类整理笔记 ClassLoader类第1/2页
- AS3自写类整理笔记 Dot类第1/2页
- 创建一个空的IBM DB2 ECO数据库的方法
- Access 2000 数据库 80 万记录通用快速分页类
- 开通一个数据库失败的原因的和解决办法
- 一个简单的asp数据库操作类
- DB2新手使用的一些小笔记:新建实例、数据库路径不存在、客户端连接 .
- CentOS下DB2数据库安装过程详解
- EasyASP v1.5发布(包含数据库操作类,原clsDbCtrl.asp)第1/2页
- sql2008 还原数据库解决方案