Spark On Yarn(HDFS HA)详细配置过程
2015-10-12 18:46
866 查看
一、服务器分布及相关说明
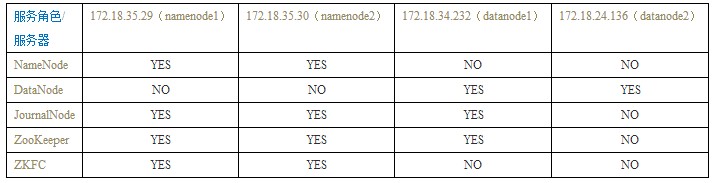
1、服务器角色
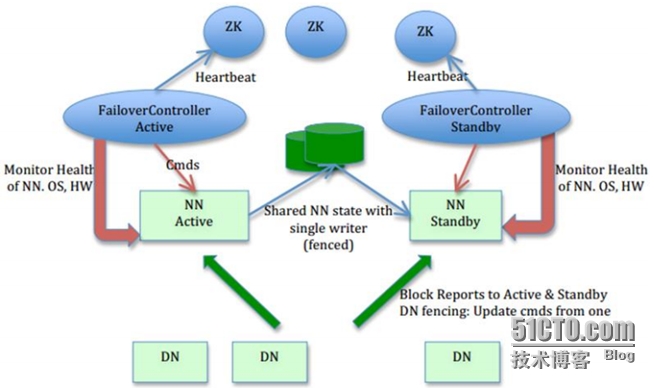
2、Hadoop(HDFS HA)总体架构
二、基础环境部署
1、JDK安装
http://download.oracle.com/otn-pub/java/jdk/7u45-b18/jdk-7u45-linux-x64.tar.gz
2、Scala安装
3、SSH免密码登录
可参考文章:
http://blog.csdn.net/codepeak/article/details/14447627
......
4、主机名设置
三、ZooKeeper集群部署
1、ZooKeeper安装
2、ZooKeeper配置与启动
在172.18.35.29上执行:
在172.18.35.30 上执行:
在172.18.34.232 上执行:
## 启动ZooKeeper集群
# cd /usr/local/zookeeper && bin/zkServer.sh
start

# ./bin/zkCli.sh -server localhost:2181
测试zookeeper集群是否建立成功,如无报错表示集群创建成功
# bin/zkServer.sh status

四、Hadoop(HDFS HA)集群部署
1、hadoop环境安装
Hadoop的源码编译部分可以参考:
http://sofar.blog.51cto.com/353572/1352713
2、core.site.xml配置
# vim/usr/local/hadoop/etc/hadoop/core-site.xml
3、hdfs-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/hdfs-site.xml
4、mapred-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/mapred-site.xml
5、yarn-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/yarn-site.xml
【注意:上面的第68`96行部分,需要根据服务器的硬件配置进行修改】
6、配置hadoop-env.sh、mapred-env.sh、yarn-env.sh【在开头添加】
文件路径:
添加内容:
7、数据节点配置
8、集群启动
(1)、在namenode1上执行,创建命名空间
# hdfs zkfc -formatZK
(2)、在对应的节点上启动日志程序journalnode
# cd /usr/local/hadoop && ./sbin/hadoop-daemon.sh start journalnode

(3)、格式化主NameNode节点(namenode1)
# hdfs namenode -format
(4)、启动主NameNode节点
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
(5)、格式备NameNode节点(namenode2)
# hdfs namenode -bootstrapStandby
(6)、启动备NameNode节点(namenode2)
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
----------------------------------------------------------------------------------------------------------------------------------------------
(7)、在两个NameNode节点(namenode1、namenode2)上执行
# cd /usr/local/hadoop && sbin/hadoop-daemon.shstart zkfc
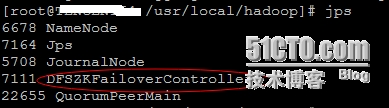
----------------------------------------------------------------------------------------------------------------------------------------------
(8)、启动所有的DataNode节点(datanode1、datanode2)
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start datanode
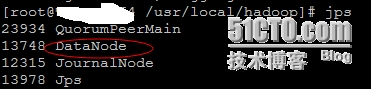
----------------------------------------------------------------------------------------------------------------------------------------------
(9)、启动Yarn(namenode1)
# cd /usr/local/hadoop && sbin/start-yarn.sh

主NameNode节点上的信息:
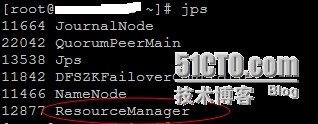
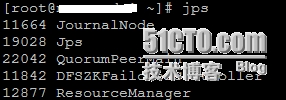
DataNode节点上的信息:
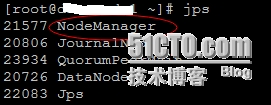
----------------------------------------------------------------------------------------------------------------------------------------------
(10)、测试Yarn是否可用
# hdfs dfs -put/usr/local/hadoop/etc/hadoop/yarn-site.xml /tmp
# hadoop jar/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarwordcount /tmp/yarn-site.xml /mytest
-----------------------------------------------------------------------------------------------------------------------------------------------
(11)、HDFS的HA功能测试
切换前的状态:
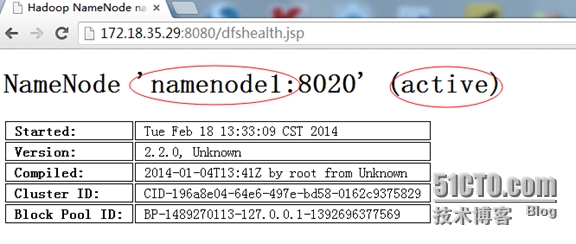
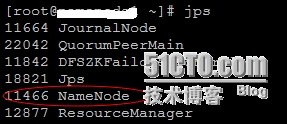
# kill -9 11466
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
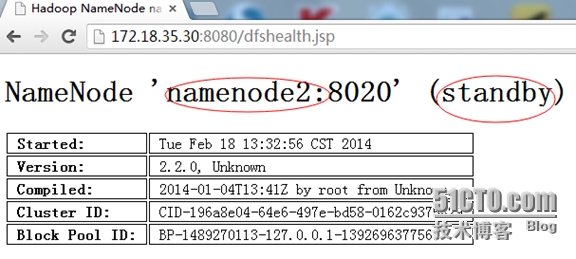
切换后的状态:
-----------------------------------------------------------------------------------------------------------------------------------------------
(12)、后续维护
HDFS的关闭与启动:
# cd /usr/local/hadoop && sbin/stop-dfs.sh
# cd /usr/local/hadoop && sbin/start-dfs.sh
YARN的关闭与启动:
# cd /usr/local/hadoop && sbin/stop-yarn.sh
# cd /usr/local/hadoop && sbin/start-yarn.sh
【注意】
需要在NameNode节点上执行。
五、Spark集群部署
1、Spark安装与配置
Spark的源码编译请参考:
http://sofar.blog.51cto.com/353572/1358457
# tar xvzf spark-0.9.0-incubating.tgz -C/usr/local
# cd /usr/local
# ln -s spark-0.9.0-incubating spark
# vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
# cd /usr/local/spark/conf
# mkdir -p /data/spark/tmp
----------------------------------------------------------------------------------------------------------------------------------------------
# vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
SPARK_LOCAL_DIR="/data/spark/tmp"
SPARK_JAVA_OPTS="-Dspark.storage.blockManagerHeartBeatMs=60000-Dspark.local.dir=$SPARK_LOCAL_DIR -XX:+PrintGCDetails
-XX:+PrintGCTi
meStamps -Xloggc:$SPARK_HOME/logs/gc.log -XX:+UseConcMarkSweepGC-XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFracti
on=60"
----------------------------------------------------------------------------------------------------------------------------------------------
# vim slaves
datanode1
datanode2
# cd /usr/local/spark && sbin/start-all.sh
=========================================================================================
2、相关测试
(1)、本地模式
# bin/run-exampleorg.apache.spark.examples.SparkPi local
----------------------------------------------------------------------------------------------------------------------------------------------
(2)、普通集群模式
# bin/run-exampleorg.apache.spark.examples.SparkPi spark://namenode1:7077
# bin/run-exampleorg.apache.spark.examples.SparkLR spark://namenode1:7077
# bin/run-exampleorg.apache.spark.examples.SparkKMeans spark://namenode1:7077file:/usr/local/spark/data/kmeans_data.txt 2
1
----------------------------------------------------------------------------------------------------------------------------------------------
(3)、结合HDFS的集群模式
# hadoop fs -put README.md .
# MASTER=spark://namenode1:7077bin/spark-shell
scala> val file =sc.textFile("hdfs://namenode1:9000/user/root/README.md")
scala> val count = file.flatMap(line=> line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
scala> count.collect()
scala> :quit
----------------------------------------------------------------------------------------------------------------------------------------------
(4)、基于YARN模式
#SPARK_JAR=assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop2.2.0.jar\
bin/spark-classorg.apache.spark.deploy.yarn.Client \
--jarexamples/target/scala-2.10/spark-examples_2.10-assembly-0.9.0-incubating.jar \
--classorg.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 4g \
--worker-memory 2g \
--worker-cores 1
----------------------------------------------------------------------------------------------------------------------------------------------
(5)、最终的目录结构及相关配置
目录结构:
配置文件“/etc/profile”中的环境变量设置:
原文:Spark On Yarn(HDFS HA)详细配置过程
返回数据库首页
1、服务器角色
2、Hadoop(HDFS HA)总体架构
二、基础环境部署
1、JDK安装
http://download.oracle.com/otn-pub/java/jdk/7u45-b18/jdk-7u45-linux-x64.tar.gz
# tar xvzf jdk-7u45-linux-x64.tar.gz -C/usr/local # cd /usr/local # ln -s jdk1.7.0_45 jdk # vim /etc/profile export JAVA_HOME=/usr/local/jdk export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$JAVA_HOME/bin # source /etc/profile
2、Scala安装
http://www.scala-lang.org/files/archive/scala-2.10.3.tgz # tar xvzf scala-2.10.3.tgz -C/usr/local # cd /usr/local # ln -s scala-2.10.3 scala # vim /etc/profile export SCALA_HOME=/usr/local/scala export PATH=$PATH:$SCALA_HOME/bin # source /etc/profile
3、SSH免密码登录
可参考文章:
http://blog.csdn.net/codepeak/article/details/14447627
......
4、主机名设置
# vim /etc/hosts 172.18.35.29 namenode1 172.18.35.30 namenode2 172.18.34.232 datanode1 172.18.24.136 datanode2
三、ZooKeeper集群部署
1、ZooKeeper安装
http://apache.dataguru.cn/zookeeper/stable/zookeeper-3.4.5.tar.gz # tar xvzf zookeeper-3.4.5.tar.gz -C/usr/local # cd /usr/local # ln -s zookeeper-3.4.5 zookeeper # vim /etc/profile export ZOO_HOME=/usr/local/zookeeper export ZOO_LOG_DIR=/data/hadoop/zookeeper/logs export PATH=$PATH:$ZOO_HOME/bin # source /etc/profile
2、ZooKeeper配置与启动
# mkdir -p/data/hadoop/zookeeper/{data,logs}
# vim /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/hadoop/zookeeper/data
clientPort=2181
server.1=172.18.35.29:2888:3888
server.2=172.18.35.30:2888:3888
server.3=172.18.34.232:2888:3888在172.18.35.29上执行:
echo 1 > /data/hadoop/zookeeper/data/myid
在172.18.35.30 上执行:
echo 2 > /data/hadoop/zookeeper/data/myid
在172.18.34.232 上执行:
echo 3 > /data/hadoop/zookeeper/data/myid
## 启动ZooKeeper集群
# cd /usr/local/zookeeper && bin/zkServer.sh
start
# ./bin/zkCli.sh -server localhost:2181
测试zookeeper集群是否建立成功,如无报错表示集群创建成功
# bin/zkServer.sh status
四、Hadoop(HDFS HA)集群部署
1、hadoop环境安装
Hadoop的源码编译部分可以参考:
http://sofar.blog.51cto.com/353572/1352713
# tar xvzf hadoop-2.2.0.tgz -C/usr/local
# cd /usr/local
# ln -s hadoop-2.2.0 hadoop
# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# mkdir -p /data/hadoop/{pids,storage}
# mkdir -p/data/hadoop/storage/{hdfs,tmp,journal}
# mkdir -p/data/hadoop/storage/tmp/nodemanager/{local,remote,logs}
# mkdir -p/data/hadoop/storage/hdfs/{name,data}2、core.site.xml配置
# vim/usr/local/hadoop/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://appcluster</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/data/hadoop/storage/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>172.18.35.29:2181,172.18.35.30:2181,172.18.34.232:2181</value> </property> <property> <name>ha.zookeeper.session-timeout.ms</name> <value>2000</value> </property> <property> <name>fs.trash.interval</name> <value>4320</value> </property> <property> <name>hadoop.http.staticuser.use</name> <value>root</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> <property> <name>hadoop.native.lib</name> <value>true</value> </property> </configuration>
3、hdfs-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hadoop/storage/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/data/hadoop/storage/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.blocksize</name> <value>67108864</value> </property> <property> <name>dfs.datanode.du.reserved</name> <value>53687091200</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>appcluster</value> </property> <property> <name>dfs.ha.namenodes.appcluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.appcluster.nn1</name> <value>namenode1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.appcluster.nn2</name> <value>namenode2:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.appcluster.nn1</name> <value>namenode1:53310</value> </property> <property> <name>dfs.namenode.servicerpc-address.appcluster.nn2</name> <value>namenode2:53310</value> </property> <property> <name>dfs.namenode.http-address.appcluster.nn1</name> <value>namenode1:8080</value> </property> <property> <name>dfs.namenode.http-address.appcluster.nn2</name> <value>namenode2:8080</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:8080</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://namenode1:8485;namenode2:8485;datanode1:8485/appcluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.appcluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence(root:36000)</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa_nn1</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/data/hadoop/storage/hdfs/journal</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>ha.failover-controller.cli-check.rpc-timeout.ms</name> <value>60000</value> </property> <property> <name>ipc.client.connect.timeout</name> <value>60000</value> </property> <property> <name>dfs.image.transfer.bandwidthPerSec</name> <value>41943040</value> </property> <property> <name>dfs.namenode.accesstime.precision</name> <value>3600000</value> </property> <property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property> </configuration>
4、mapred-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>namenode1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>namenode1:19888</value> </property> </configuration>
5、yarn-site.xml配置
# vim/usr/local/hadoop/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenode1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenode1:8033</value>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>namenode1:8034</value>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>namenode1:80</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>namenode1:80</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/nodemanager/local</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>${hadoop.tmp.dir}/nodemanager/remote</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${hadoop.tmp.dir}/nodemanager/logs</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>50320</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>40960</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>8</value>
</property>
</configuration>【注意:上面的第68`96行部分,需要根据服务器的硬件配置进行修改】
6、配置hadoop-env.sh、mapred-env.sh、yarn-env.sh【在开头添加】
文件路径:
/usr/local/hadoop/etc/hadoop/hadoop-env.sh /usr/local/hadoop/etc/hadoop/mapred-env.sh /usr/local/hadoop/etc/hadoop/yarn-env.sh
添加内容:
export JAVA_HOME=/usr/local/jdk export CLASS_PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/lib export HADOOP_HOME=/usr/local/hadoop export HADOOP_PID_DIR=/data/hadoop/pids export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="$HADOOP_OPTS-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_PREFIX=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
7、数据节点配置
# vim /usr/local/hadoop/etc/hadoop/slaves datanode1 datanode2
8、集群启动
(1)、在namenode1上执行,创建命名空间
# hdfs zkfc -formatZK
(2)、在对应的节点上启动日志程序journalnode
# cd /usr/local/hadoop && ./sbin/hadoop-daemon.sh start journalnode
(3)、格式化主NameNode节点(namenode1)
# hdfs namenode -format
(4)、启动主NameNode节点
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
(5)、格式备NameNode节点(namenode2)
# hdfs namenode -bootstrapStandby
(6)、启动备NameNode节点(namenode2)
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
----------------------------------------------------------------------------------------------------------------------------------------------
(7)、在两个NameNode节点(namenode1、namenode2)上执行
# cd /usr/local/hadoop && sbin/hadoop-daemon.shstart zkfc
----------------------------------------------------------------------------------------------------------------------------------------------
(8)、启动所有的DataNode节点(datanode1、datanode2)
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start datanode
----------------------------------------------------------------------------------------------------------------------------------------------
(9)、启动Yarn(namenode1)
# cd /usr/local/hadoop && sbin/start-yarn.sh
主NameNode节点上的信息:
DataNode节点上的信息:
----------------------------------------------------------------------------------------------------------------------------------------------
(10)、测试Yarn是否可用
# hdfs dfs -put/usr/local/hadoop/etc/hadoop/yarn-site.xml /tmp
# hadoop jar/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarwordcount /tmp/yarn-site.xml /mytest
-----------------------------------------------------------------------------------------------------------------------------------------------
(11)、HDFS的HA功能测试
切换前的状态:
# kill -9 11466
# cd /usr/local/hadoop && sbin/hadoop-daemon.sh start namenode
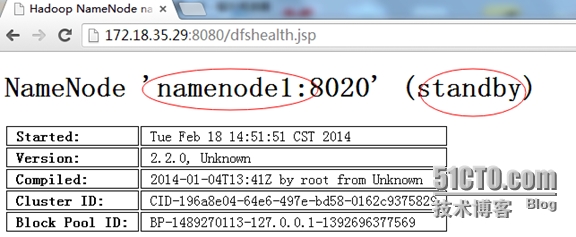
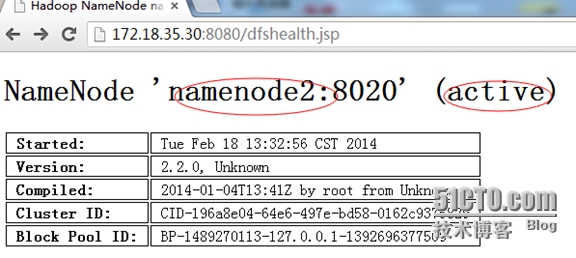
切换后的状态:
-----------------------------------------------------------------------------------------------------------------------------------------------
(12)、后续维护
HDFS的关闭与启动:
# cd /usr/local/hadoop && sbin/stop-dfs.sh
# cd /usr/local/hadoop && sbin/start-dfs.sh
YARN的关闭与启动:
# cd /usr/local/hadoop && sbin/stop-yarn.sh
# cd /usr/local/hadoop && sbin/start-yarn.sh
【注意】
需要在NameNode节点上执行。
五、Spark集群部署
1、Spark安装与配置
Spark的源码编译请参考:
http://sofar.blog.51cto.com/353572/1358457
# tar xvzf spark-0.9.0-incubating.tgz -C/usr/local
# cd /usr/local
# ln -s spark-0.9.0-incubating spark
# vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
# cd /usr/local/spark/conf
# mkdir -p /data/spark/tmp
----------------------------------------------------------------------------------------------------------------------------------------------
# vim spark-env.sh
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
SPARK_LOCAL_DIR="/data/spark/tmp"
SPARK_JAVA_OPTS="-Dspark.storage.blockManagerHeartBeatMs=60000-Dspark.local.dir=$SPARK_LOCAL_DIR -XX:+PrintGCDetails
-XX:+PrintGCTi
meStamps -Xloggc:$SPARK_HOME/logs/gc.log -XX:+UseConcMarkSweepGC-XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFracti
on=60"
----------------------------------------------------------------------------------------------------------------------------------------------
# vim slaves
datanode1
datanode2
# cd /usr/local/spark && sbin/start-all.sh
=========================================================================================
2、相关测试
(1)、本地模式
# bin/run-exampleorg.apache.spark.examples.SparkPi local
----------------------------------------------------------------------------------------------------------------------------------------------
(2)、普通集群模式
# bin/run-exampleorg.apache.spark.examples.SparkPi spark://namenode1:7077
# bin/run-exampleorg.apache.spark.examples.SparkLR spark://namenode1:7077
# bin/run-exampleorg.apache.spark.examples.SparkKMeans spark://namenode1:7077file:/usr/local/spark/data/kmeans_data.txt 2
1
----------------------------------------------------------------------------------------------------------------------------------------------
(3)、结合HDFS的集群模式
# hadoop fs -put README.md .
# MASTER=spark://namenode1:7077bin/spark-shell
scala> val file =sc.textFile("hdfs://namenode1:9000/user/root/README.md")
scala> val count = file.flatMap(line=> line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
scala> count.collect()
scala> :quit
----------------------------------------------------------------------------------------------------------------------------------------------
(4)、基于YARN模式
#SPARK_JAR=assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop2.2.0.jar\
bin/spark-classorg.apache.spark.deploy.yarn.Client \
--jarexamples/target/scala-2.10/spark-examples_2.10-assembly-0.9.0-incubating.jar \
--classorg.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers 3 \
--master-memory 4g \
--worker-memory 2g \
--worker-cores 1
----------------------------------------------------------------------------------------------------------------------------------------------
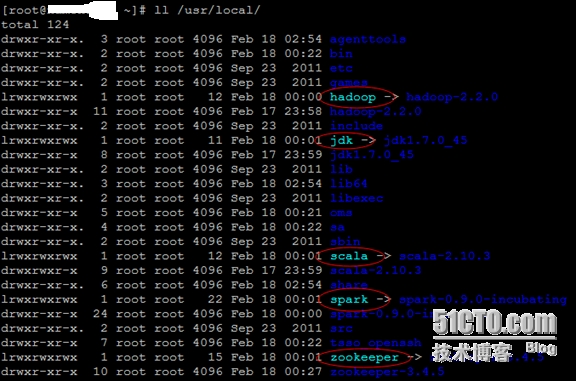
(5)、最终的目录结构及相关配置
目录结构:
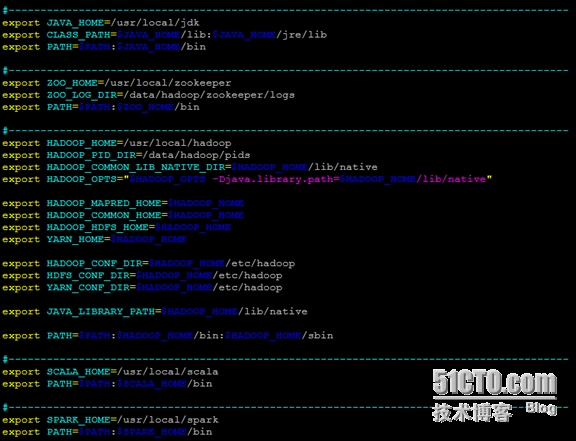
配置文件“/etc/profile”中的环境变量设置:
原文:Spark On Yarn(HDFS HA)详细配置过程
返回数据库首页

相关文章推荐
- Hadoop “Unable to load native-hadoop library for y
- flume 采集数据到hdfs
- Sqoop--关系型数据库跟hdfs数据传输工具
- HDFS简介
- Hadoop学习笔记-随手记
- 【转】HDFS 安全模式
- HDFS文件的合并
- HDFD 四个配置文件(core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml )的简单介绍
- flume+kafka+hdfs详解
- 【转】HDFS 的Trash回收站功能的配置、使用
- HDFS原理及其个元素功能
- 认识HDFS分布式文件系统
- 搭建hdfsHA时遇到的问题及其解决方案
- HDFS-Architecture剖析
- flume学习(五):flume将log4j日志数据写入到hdfs
- HDFS序列化
- 解决从本地文件系统上传到HDFS时的权限问题
- 解决从本地文件系统上传到HDFS时的权限问题
- HDFS基本命令
- hadoop2.7.0升级到2.7.1,版本升级