HadoopHDFS源码解析
2015-10-11 21:26
507 查看
HDFS即Hadoop Distributed File System分布式文件系统,它的设计目标是把超大数据集存储到分布在网络中的多台普通商用计算机上,并且能够提供高可靠性和高吞吐量的服务。分布式文件系统要比普通磁盘文件系统复杂,因为它要引入网络编程,分布式文件系统要容忍节点故障也是一个很大的挑战。我们BI团队作为数据分析团队,对于数据的存储有着非常高的要求,不仅需要高可靠及高吞吐量,还必须满足通过不断水平扩展来满足日益增长的业务数据,当前HDFS很好的满足了我们对于大规模数据存储的要求。
设计前提和目标:
(1)支持超大文件。一个Hadoop文件系统可以存储T、P级别的数据。
(2)检测和快速应对硬件故障。一般的HDFS系统是由数百台甚至上千台服务器组成,因此,故障检测和自动恢复是HDFS的一个设计目标。
(3)流式数据访问。HDFS处理的数据规模都比较大,一般都是批处理,所以它注重的是数据的吞吐量,而不是数据的访问速度。
(4)简化的一致性模型。大部分的HDFS程序操作文件时需要一次写入,多次读取。在HDFS中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了。这样简单的一致性模型,有助于提高吞吐量的数据访问模型。
而HDFS不适用于如下场景:
(1)低延迟数据访问。因为HDFS关注的是数据的吞吐量,而不是数据的访问速度,所以HDFS不适用于要求低延迟的数据访问应用。
(2)大量的小文件。HDFS是通过将数据分布在数据节点,并将文件的元数据保存在名字节点上来支持超大文件存储的。名字节点的内存大小决定了HDFS系统可保存的文件数量,大量的小文件会影响到名字节点的性能。
(3)多用户写入修改文件。HDFS中的文件只能有一个写入者,而且写操作总是在文件末。它不支持多个写入者,也不支持在数据写入后,在文件的任意位置进行修改。
HDFS是一个具有高度容错性的分布式文件系统,适合部署在廉价的机器上。HDFS能提供搞吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS的架构如图1所示,总体上采用了master/slave架构,主要由以下几个组件组成:Client,NameNode,SecondaryNameNode和DataNode。
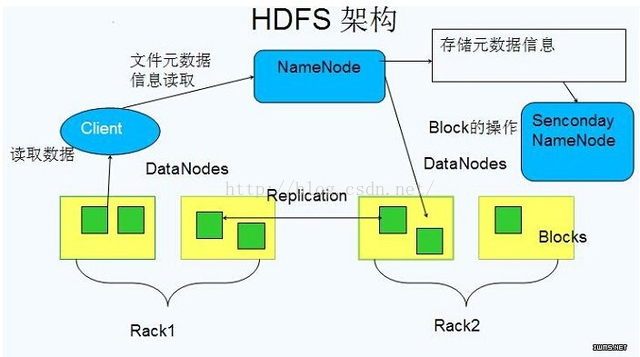
图1 HDFS的架构
(1)Client
Client通过与NameNode和DataNode交互从而访问HDFS中的文件,Client提供了一个DistributedFileSystem接口供用户使用。
(2)NameNode
整个Hadoop集群中只有一个NameNode,它是整个系统的"总管",负责管理HDFS的目录树和相关文件元数据信息,这些信息是以"fsimage"(HDFS元数据镜像文件)和"editlog"(HDFS文件修改日志)两个文件形式存放在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的监控状态,一旦发现某个DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
(3)SecondaryNameNode
SecondaryNameNode最重要的任务并不是为了NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode。这里需要注意的是,为了减少NameNode的压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由SecondaryNameNode完成。
(4)DataNode
一般而言,每个Slave节点上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB,当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode。同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认3)不同的DataNode上,这种文件数据切割后分布式存储的过程是对用户透明的。
下面先从HDFS中的NameNode和DataNode的目录结构来整体认识HDFS中的数据结构,然后再从HDFS的写文件过程和HDFS读文件过程为线索,详细介绍HDFS存取数据的细节,并对HDFS的主要核心代码进行解析。
(1)元数据节点的目录结构
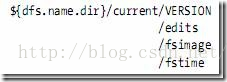
图2 目录结构
VERSION文件是java properties文件,保存了HDFS的版本号。
layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的。
cTime此处为0
storageType表示此文件夹中保存的是元数据节点的数据结构。
文件系统命名空间映像文件及修改日志
当文件系统客户端(client)进行写操作时,首先把它记录在修改日志中(edit log)
元数据节点在内存中保存了文件系统的元数据信息。在记录了修改日志后,元数据节点则修改内存中的数据结构。
每次的写操作成功之前,修改日志都会同步(sync)到文件系统。
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
同数据的机制相似,当元数据节点失败时,则最新checkpoint的元数据信息从fsimage加载到内存中,然后逐一重新执行修改日志中的操作。
从元数据节点就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的。
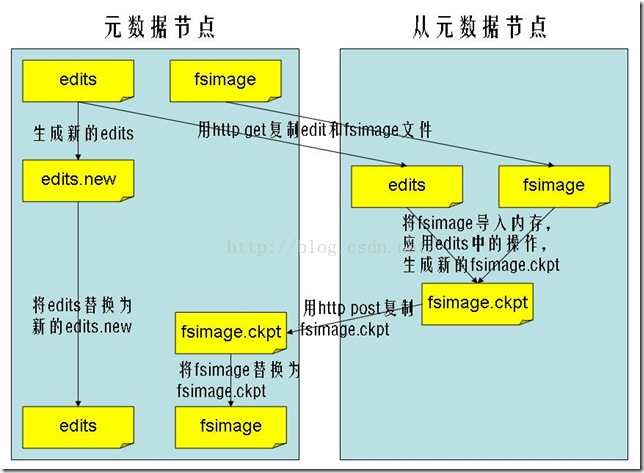
图3 文件系统图
(2)从元数据节点的目录结构
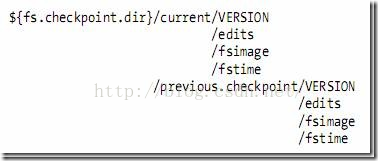
图4 目录结构
(3)数据节点的目录结构
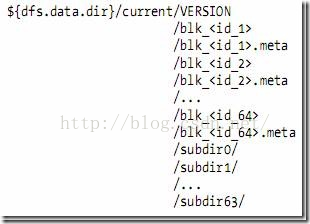
图5 目录结构
数据节点的VERSION文件格式如下:
HDFS有一个DistributedFileSystem实例,客户端通过调用这个实例的create()方法就可以创建文件。DistributedFileSystem会发送给NameNode一个RPC调用,在文件系统的命名空间创建一个新文件,在创建文件前NameNode会做一些检查,如文件是否存在,客户端是否有创建权限等,若检查通过, NameNode会为创建文件写一条记录到本地磁盘的EditLog,若不通过会向客户端抛出IOException。创建成功之后DistributedFileSystem会返回一个FSDataOutputStream对象,客户端由此开始写入数据。HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同, 从宏观上来看,在HDFS文件系统上创建并写一个文件,流程如下图:
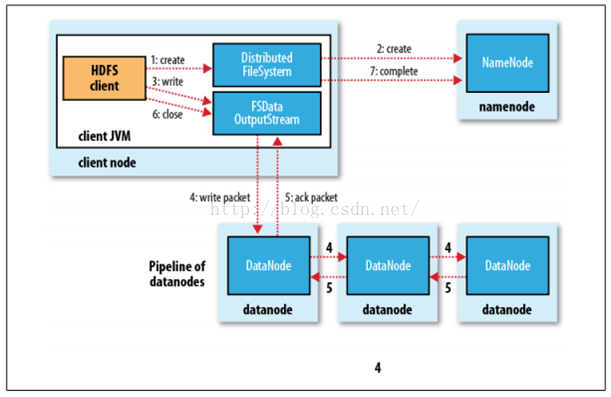
图6 HDFS写文件流程图
具体过程描述如下:
(1)Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象
(2)通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block
(3)通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包
(4)以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet
(5)这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client
(6)完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
(7)调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
下面代码使用Hadoop的API来实现向HDFS的文件写入数据,同样也包括创建一个文件和写数据两个主要过程,代码如下所示:
3.2.1 客户端调用DistributedFileSystem创建一个文件
上传一个文件到HDFS,一般会调用DistributedFileSystem.create,其实现如下:
其最终生成一个FSDataOutputStream用于向新生成的文件中写入数据。其成员变量dfs的类型为DFSClient,DFSClient的create函数如下:
DFSOutputStream内部原理
打开一个DFSOutputStream流,Client会写数据到流内部的一个缓冲区中,然后数据被分解成多个Packet,每个Packet大小为64k字节,每个Packet又由一组chunk和这组chunk对应的checksum数据组成,默认chunk大小为512字节,每个checksum是对512字节数据计算的校验和数据。
当Client写入的字节流数据达到一个Packet的长度,这个Packet会被构建出来,然后会被放到队列dataQueue中,接着DataStreamer线程会不断地从dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将该Packet从dataQueue队列中移到ackQueue队列中。ResponseProcessor线程接收从Datanode发送过来的ack,如果是一个成功的ack,表示复制Pipeline中的所有Datanode都已经接收到这个Packet,ResponseProcessor线程将packet从队列ackQueue中删除。在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。
下面是DFSOutputStream的结构及其原理,如图所示:
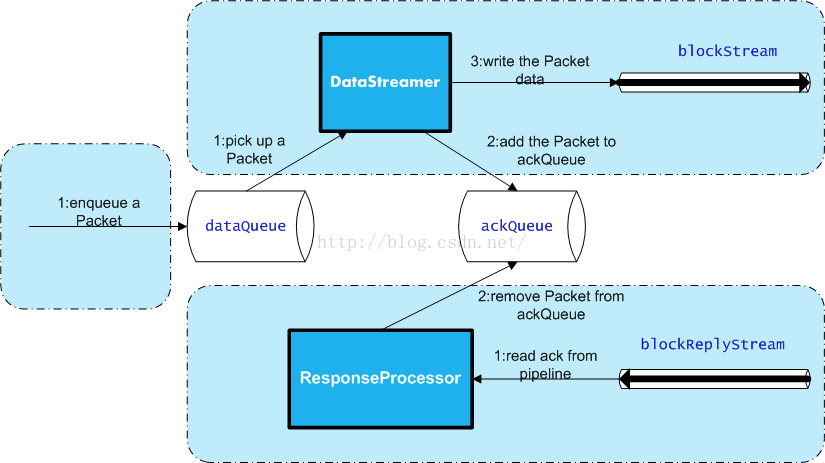
图7 DFSOutputStream原理图
我们从下面3个方面来描述内部流程:
创建Packet:Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
发送Packet:DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据。
接收ack:发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功。如果成功,则ResponseProcessor线程会将ackQueue队列中对应的Packet删除。
NameNode的create函数调用namesystem.startFile函数,其又调用startFileInternal函数,实现如下:
下面轮到客户端向新创建的文件中写入数据了,一般会使用FSDataOutputStream的write函数,最终会调用DFSOutputStream的writeChunk函数:
按照HDFS的设计,对block的数据写入使用的是pipeline的方式,也即将数据分成一个个的package,如果需要复制三分,分别写入DataNode 1, 2, 3,则会进行如下的过程:首先将package 1写入DataNode 1;然后由DataNode 1负责将package 1写入DataNode 2,同时客户端可以将pacage 2写入DataNode 1;然后DataNode 2负责将package 1写入DataNode 3, 同时客户端可以讲package 3写入DataNode
1,DataNode 1将package 2写入DataNode 2;就这样将一个个package排着队的传递下去,直到所有的数据全部写入并复制完毕
其中重要的一个函数是nextBlockOutputStream,实现如下:
NameNode的addBlock函数实现如下:
FSNamesystem的getAdditionalBlock实现如下:
3.2.5 客户端创建目标DataNode的DataOutputStream输出流
在分配了DataNode和block以后,createBlockOutputStream开始写入数据。
客户端在DataStreamer的run函数中创建了写入流后,调用blockStream.write将数据写入DataNode
数据最终会发送到DataNode节点上,在一个DataNode上,数据在各个组件之间流动,流程如下图所示:
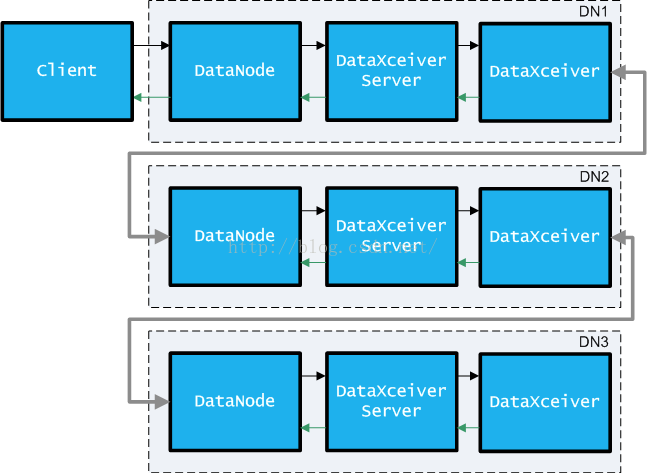
图8 DataNode数据流程图
DataNode服务中创建一个后台线程DataXceiverServer,它是一个SocketServer,用来接收来自Client(或者DataNode Pipeline中的非最后一个DataNode节点)的写数据请求,然后在DataXceiverServer中将连接过来的Socket直接派发给一个独立的后台线程DataXceiver进行处理。所以,Client写数据时连接一个DataNode
Pipeline的结构,实际流程如图所示:
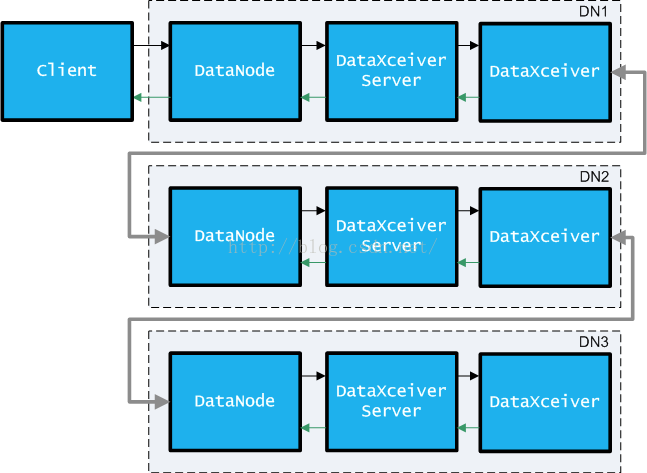
图9 DataNode-Pipeline数据流程图
DataNode的DataXceiver中,收到指令DataTransferProtocol.OP_WRITE_BLOCK则调用writeBlock函数:
BlockReceiver的receivePacket函数如下:
HDFS写文件过程具体序列图如下:
图10 HDFS写文件序列图一
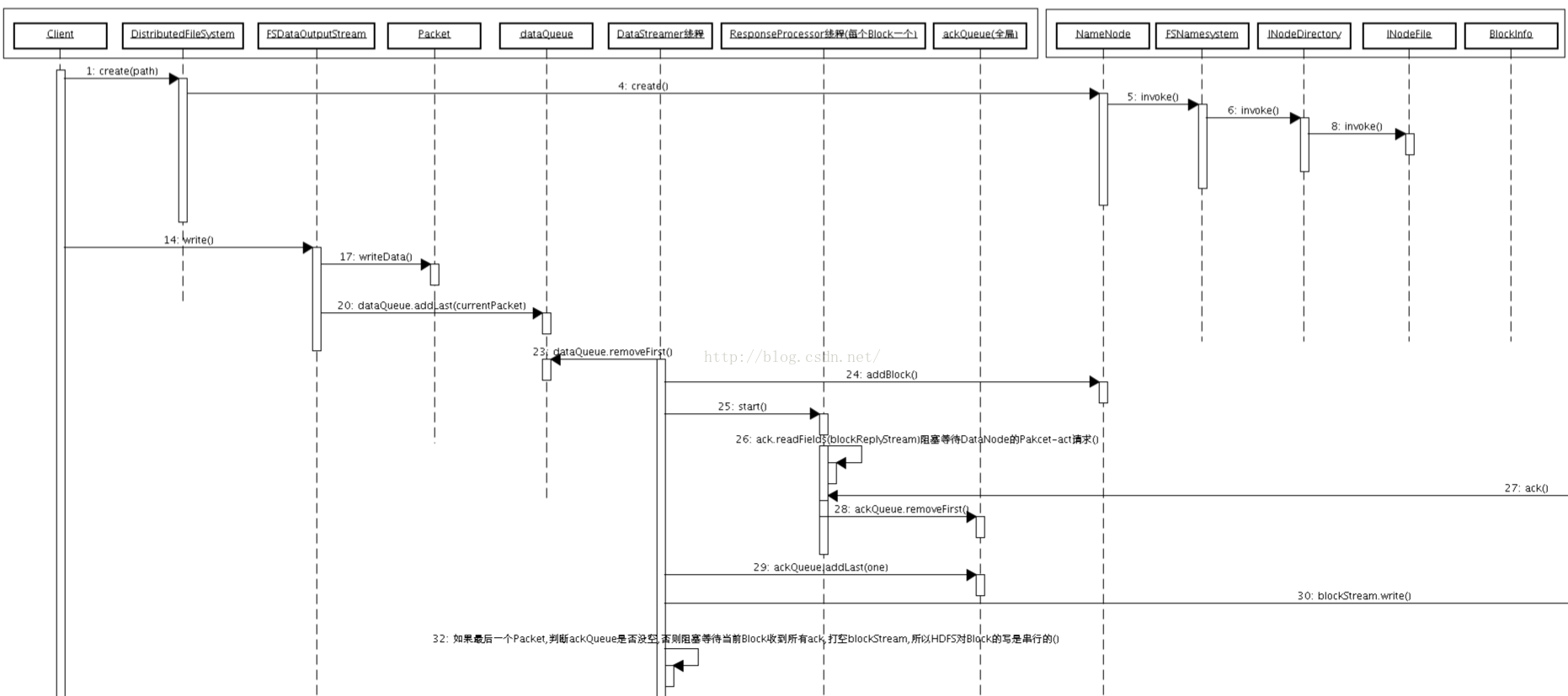
图11 HDFS写文件序列图二
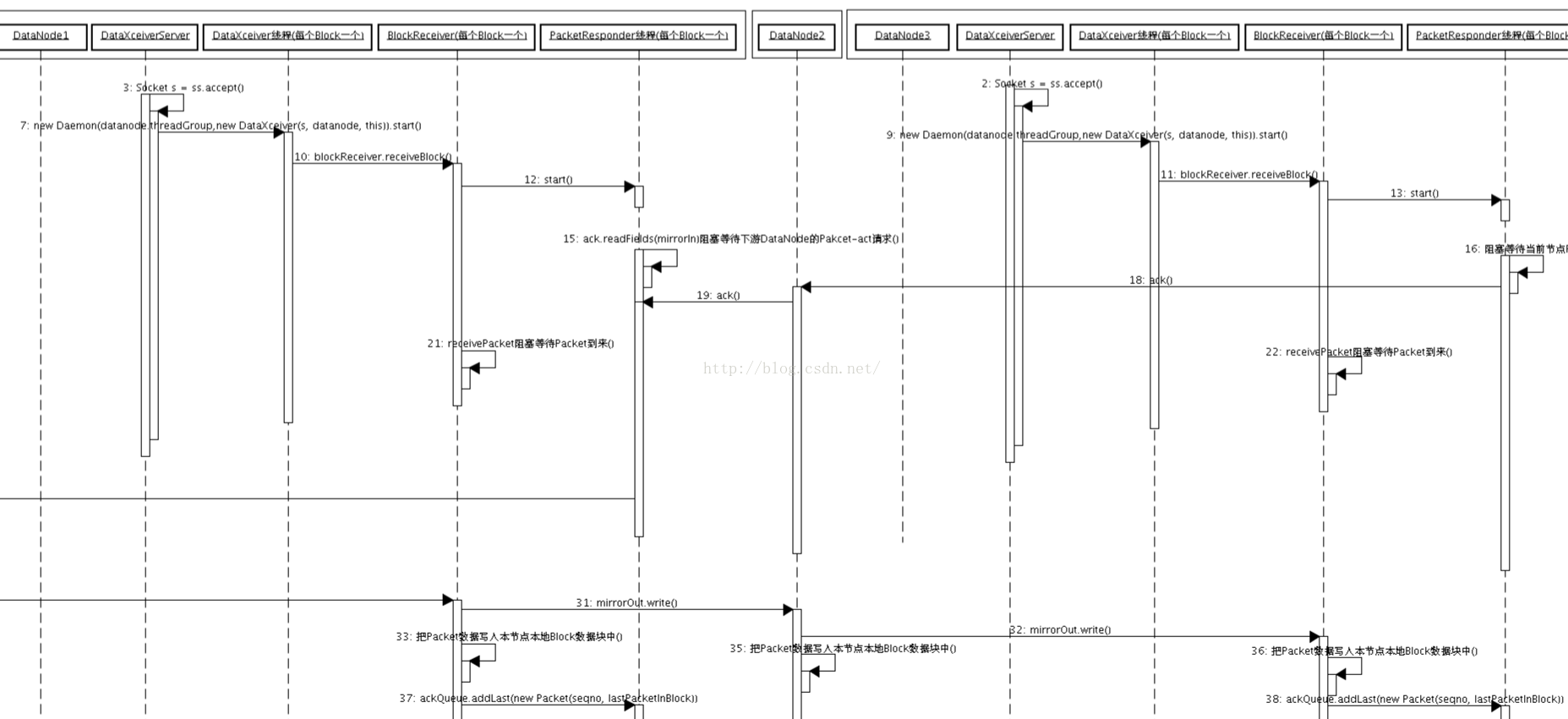
HDFS有一个FileSystem实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件。HDFS通过RPC调用NameNode获取文件块的位置信息,对于文件的每一个块,NameNode会返回含有该块副本的DataNode的节点地址,另外,客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的那个DataNode获取数据块的副本,最理想的情况是数据块就存储在客户端所在的节点上。HDFS会返回一个FSDataInputStream对象,FSDataInputStream类转而封装成DFSDataInputStream对象,这个对象管理着与DataNode和NameNode的I/O,流程如下图:
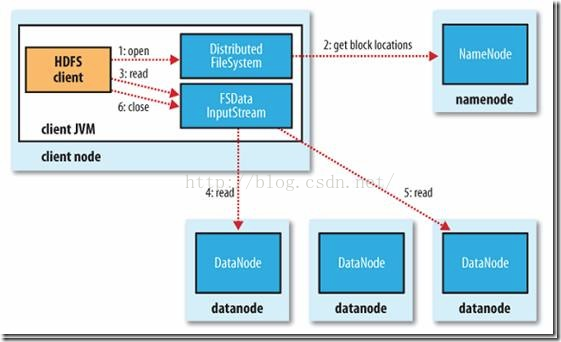
图12 HDFS读文件数据流程图
具体过程描述如下:客户端发起读请求;客户端从NameNode得到文件的块及位置信息列表;客户端直接和DataNode交互读取数据;读取完成关闭连接。
HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为:
Block b:此block的信息。
long offset:此block在文件中的偏移。
DatanodeInfo[] locs:此block位于哪些DataNode上
上面namenode.getBlockLocations是一个RPC调用,最终调用NameNode类的getBlockLocations函数。
NameNode.getBlockLocations实现如下:
namesystem是NameNode一个成员变量,其类型为FSNamesystem,保存的是NameNode的name space树,其中一个重要的成员变量为FSDirectory dir。
FSDirectory和Lucene中的FSDirectory没有任何关系,其主要包括FSImage fsImage,用于读写硬盘上的fsimage文件,FSImage类有成员变量FSEditLog editLog,用于读写硬盘上的edit文件,这两个文件的关系在上一篇文章中已经解释过。FSDirectory还有一个重要的成员变量INodeDirectoryWithQuota rootDir,INodeDirectoryWithQuota的父类为INodeDirectory,实现如下:
由此可见INodeDirectory本身是一个INode,其中包含一个链表的INode,此链表中,如果仍为文件夹,则是类型INodeDirectory,如果是文件,则是类型INodeFile,INodeFile中有成员变量BlockInfo blocks[],是此文件包含的block的信息。显然这是一棵树形的结构。FSNamesystem.getBlockLocations函数如下:
dir.getFileINode(src)通过路径名从文件系统树中找到INodeFile,其中保存的是要打开的文件的INode的信息。
getBlockLocationsInternal的实现如下:
通过RPC调用,从NameNode得到LocatedBlocks对象,作为成员变量构造DFSInputStream对象,最后包装为FSDataInputStream返回给用户。
3.3.3 客户端通过DFSInputStream读数据
文件读取的时候,客户端利用文件打开的时候得到的FSDataInputStream.read(long position, byte[] buffer, int offset, int length)函数进行文件读操作。FSDataInputStream会调用其封装的DFSInputStream的read(long position, byte[] buffer, int offset, int length)函数,实现如下:
其中getBlockRange函数如下:
其中fetchBlockByteRange实现如下:
BlockReader.newBlockReader函数实现如下:
BlockReader的readAll函数就是用上面生成的DataInputStream读取数据。
在DataNode启动的时候,会调用函数startDataNode,其中与数据读取有关的逻辑如下:
DataXceiver.run()函数如下:
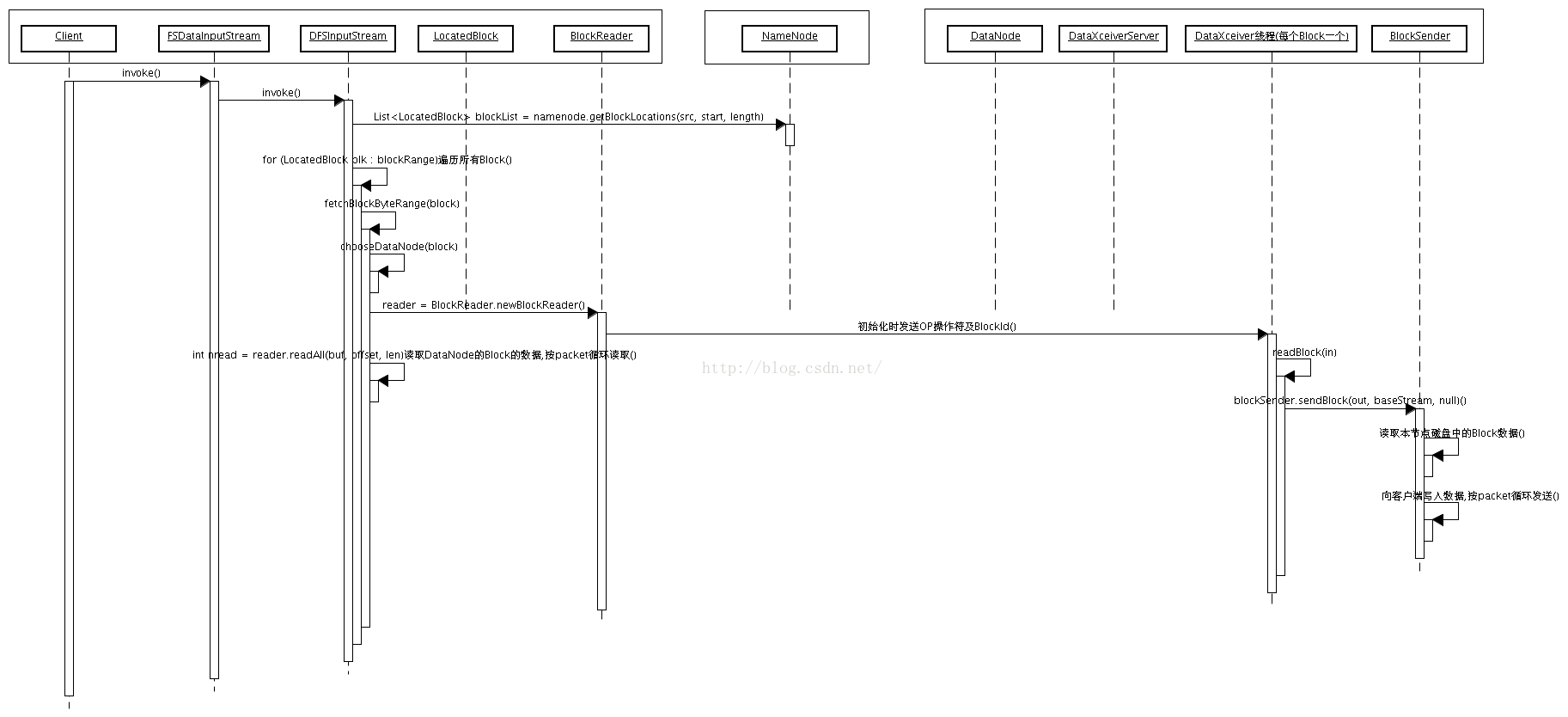
HDFS读文件过程具体序列图如下:
1. HDFS设计目标及适用场景
设计前提和目标:(1)支持超大文件。一个Hadoop文件系统可以存储T、P级别的数据。
(2)检测和快速应对硬件故障。一般的HDFS系统是由数百台甚至上千台服务器组成,因此,故障检测和自动恢复是HDFS的一个设计目标。
(3)流式数据访问。HDFS处理的数据规模都比较大,一般都是批处理,所以它注重的是数据的吞吐量,而不是数据的访问速度。
(4)简化的一致性模型。大部分的HDFS程序操作文件时需要一次写入,多次读取。在HDFS中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了。这样简单的一致性模型,有助于提高吞吐量的数据访问模型。
而HDFS不适用于如下场景:
(1)低延迟数据访问。因为HDFS关注的是数据的吞吐量,而不是数据的访问速度,所以HDFS不适用于要求低延迟的数据访问应用。
(2)大量的小文件。HDFS是通过将数据分布在数据节点,并将文件的元数据保存在名字节点上来支持超大文件存储的。名字节点的内存大小决定了HDFS系统可保存的文件数量,大量的小文件会影响到名字节点的性能。
(3)多用户写入修改文件。HDFS中的文件只能有一个写入者,而且写操作总是在文件末。它不支持多个写入者,也不支持在数据写入后,在文件的任意位置进行修改。
2. HDFS体系结构
HDFS是一个具有高度容错性的分布式文件系统,适合部署在廉价的机器上。HDFS能提供搞吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS的架构如图1所示,总体上采用了master/slave架构,主要由以下几个组件组成:Client,NameNode,SecondaryNameNode和DataNode。图1 HDFS的架构
(1)Client
Client通过与NameNode和DataNode交互从而访问HDFS中的文件,Client提供了一个DistributedFileSystem接口供用户使用。
(2)NameNode
整个Hadoop集群中只有一个NameNode,它是整个系统的"总管",负责管理HDFS的目录树和相关文件元数据信息,这些信息是以"fsimage"(HDFS元数据镜像文件)和"editlog"(HDFS文件修改日志)两个文件形式存放在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的监控状态,一旦发现某个DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
(3)SecondaryNameNode
SecondaryNameNode最重要的任务并不是为了NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode。这里需要注意的是,为了减少NameNode的压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由SecondaryNameNode完成。
(4)DataNode
一般而言,每个Slave节点上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB,当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode。同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认3)不同的DataNode上,这种文件数据切割后分布式存储的过程是对用户透明的。
3. HDFS原理及源码解析
下面先从HDFS中的NameNode和DataNode的目录结构来整体认识HDFS中的数据结构,然后再从HDFS的写文件过程和HDFS读文件过程为线索,详细介绍HDFS存取数据的细节,并对HDFS的主要核心代码进行解析。
3.1 NameNode和DataNode目录结构分析
(1)元数据节点的目录结构图2 目录结构
VERSION文件是java properties文件,保存了HDFS的版本号。
layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的。
cTime此处为0
storageType表示此文件夹中保存的是元数据节点的数据结构。
| namespaceID=1232737062 cTime=0 storageType=NAME_NODE layoutVersion=-18 |
当文件系统客户端(client)进行写操作时,首先把它记录在修改日志中(edit log)
元数据节点在内存中保存了文件系统的元数据信息。在记录了修改日志后,元数据节点则修改内存中的数据结构。
每次的写操作成功之前,修改日志都会同步(sync)到文件系统。
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
同数据的机制相似,当元数据节点失败时,则最新checkpoint的元数据信息从fsimage加载到内存中,然后逐一重新执行修改日志中的操作。
从元数据节点就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的。
图3 文件系统图
(2)从元数据节点的目录结构
图4 目录结构
(3)数据节点的目录结构
图5 目录结构
数据节点的VERSION文件格式如下:
| namespaceID=1232737062 storageID=DS-1640411682-127.0.1.1-50010-1254997319480 cTime=0 storageType=DATA_NODE layoutVersion=-18 blk_<id>保存的是HDFS的数据块,其中保存了具体的二进制数据。 |
3.2 HDFS写文件过程源码分析
HDFS有一个DistributedFileSystem实例,客户端通过调用这个实例的create()方法就可以创建文件。DistributedFileSystem会发送给NameNode一个RPC调用,在文件系统的命名空间创建一个新文件,在创建文件前NameNode会做一些检查,如文件是否存在,客户端是否有创建权限等,若检查通过, NameNode会为创建文件写一条记录到本地磁盘的EditLog,若不通过会向客户端抛出IOException。创建成功之后DistributedFileSystem会返回一个FSDataOutputStream对象,客户端由此开始写入数据。HDFS是一个分布式文件系统,在HDFS上写文件的过程与我们平时使用的单机文件系统非常不同, 从宏观上来看,在HDFS文件系统上创建并写一个文件,流程如下图:图6 HDFS写文件流程图
具体过程描述如下:
(1)Client调用DistributedFileSystem对象的create方法,创建一个文件输出流(FSDataOutputStream)对象
(2)通过DistributedFileSystem对象与Hadoop集群的NameNode进行一次RPC远程调用,在HDFS的Namespace中创建一个文件条目(Entry),该条目没有任何的Block
(3)通过FSDataOutputStream对象,向DataNode写入数据,数据首先被写入FSDataOutputStream对象内部的Buffer中,然后数据被分割成一个个Packet数据包
(4)以Packet最小单位,基于Socket连接发送到按特定算法选择的HDFS集群中一组DataNode(正常是3个,可能大于等于1)中的一个节点上,在这组DataNode组成的Pipeline上依次传输Packet
(5)这组DataNode组成的Pipeline反方向上,发送ack,最终由Pipeline中第一个DataNode节点将Pipeline ack发送给Client
(6)完成向文件写入数据,Client在文件输出流(FSDataOutputStream)对象上调用close方法,关闭流
(7)调用DistributedFileSystem对象的complete方法,通知NameNode文件写入成功
下面代码使用Hadoop的API来实现向HDFS的文件写入数据,同样也包括创建一个文件和写数据两个主要过程,代码如下所示:
private static String[] contents = new String[] {"aaa","bbb","ccc","ddd","eee"};
public static void main(String[] args) {
String file = "hdfs://localhost:9000/data/test/test.log";
Path path = new Path(file);
Configuration conf = new Configuration();
FileSystem fs = null;
FSDataOutputStream output = null;
try {
fs = path.getFileSystem(conf);
output = fs.create(path); // 创建HDFS文件
for(String line : contents) { // 写入数据
output.write(line.getBytes("UTF-8"));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
output.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}3.2.1 客户端调用DistributedFileSystem创建一个文件
上传一个文件到HDFS,一般会调用DistributedFileSystem.create,其实现如下:
public FSDataOutputStream create(Path f, FsPermission permission,
boolean overwrite,
int bufferSize, short replication, long blockSize,
Progressable progress) throws IOException {
return new FSDataOutputStream
(dfs.create(getPathName(f), permission,
overwrite, replication, blockSize, progress, bufferSize),
statistics);
}其最终生成一个FSDataOutputStream用于向新生成的文件中写入数据。其成员变量dfs的类型为DFSClient,DFSClient的create函数如下:
public OutputStream create(String src,
FsPermission permission,
boolean overwrite,
short replication,
long blockSize,
Progressable progress,
int buffersize
) throws IOException {
checkOpen();
if (permission == null) {
permission = FsPermission.getDefault();
}
FsPermission masked = permission.applyUMask(FsPermission.getUMask(conf));
OutputStream result = new DFSOutputStream(src, masked,
overwrite, replication, blockSize, progress, buffersize,
conf.getInt("io.bytes.per.checksum", 512));
leasechecker.put(src, result);
return result;
}<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);"> 其中构造了一个DFSOutputStream,在其构造函数中,同过RPC调用NameNode的create来创建一个文件。当然,构造函数中还做了一件重要的事情,就是streamer.start(),也即启动了一个pipeline,用于写数据,在写入数据的过程中,我们会仔细分析。</span>
<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);"></span><pre name="code" class="java">DFSOutputStream(String src, FsPermission masked, boolean overwrite,
short replication, long blockSize, Progressable progress,
int buffersize, int bytesPerChecksum) throws IOException {
this(src, blockSize, progress, bytesPerChecksum);
computePacketChunkSize(writePacketSize, bytesPerChecksum);
try {
// 通过RPC调用NameNode接口创建一个文件
namenode.create(
src, masked, clientName, overwrite, replication, blockSize);
} catch(RemoteException re) {
throw re.unwrapRemoteException(AccessControlException.class,
QuotaExceededException.class);
}
streamer.start();
}<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);">面我们来分析下DFSOutputStream的内部实现原理。</span>
DFSOutputStream内部原理
打开一个DFSOutputStream流,Client会写数据到流内部的一个缓冲区中,然后数据被分解成多个Packet,每个Packet大小为64k字节,每个Packet又由一组chunk和这组chunk对应的checksum数据组成,默认chunk大小为512字节,每个checksum是对512字节数据计算的校验和数据。
当Client写入的字节流数据达到一个Packet的长度,这个Packet会被构建出来,然后会被放到队列dataQueue中,接着DataStreamer线程会不断地从dataQueue队列中取出Packet,发送到复制Pipeline中的第一个DataNode上,并将该Packet从dataQueue队列中移到ackQueue队列中。ResponseProcessor线程接收从Datanode发送过来的ack,如果是一个成功的ack,表示复制Pipeline中的所有Datanode都已经接收到这个Packet,ResponseProcessor线程将packet从队列ackQueue中删除。在发送过程中,如果发生错误,所有未完成的Packet都会从ackQueue队列中移除掉,然后重新创建一个新的Pipeline,排除掉出错的那些DataNode节点,接着DataStreamer线程继续从dataQueue队列中发送Packet。
下面是DFSOutputStream的结构及其原理,如图所示:
图7 DFSOutputStream原理图
我们从下面3个方面来描述内部流程:
创建Packet:Client写数据时,会将字节流数据缓存到内部的缓冲区中,当长度满足一个Chunk大小(512B)时,便会创建一个Packet对象,然后向该Packet对象中写Chunk Checksum校验和数据,以及实际数据块Chunk Data,校验和数据是基于实际数据块计算得到的。每次满足一个Chunk大小时,都会向Packet中写上述数据内容,直到达到一个Packet对象大小(64K),就会将该Packet对象放入到dataQueue队列中,等待DataStreamer线程取出并发送到DataNode节点。
发送Packet:DataStreamer线程从dataQueue队列中取出Packet对象,放到ackQueue队列中,然后向DataNode节点发送这个Packet对象所对应的数据。
接收ack:发送一个Packet数据包以后,会有一个用来接收ack的ResponseProcessor线程,如果收到成功的ack,则表示一个Packet发送成功。如果成功,则ResponseProcessor线程会将ackQueue队列中对应的Packet删除。
3.2.2 NameNode创建一个空INodeFile
NameNode的create函数调用namesystem.startFile函数,其又调用startFileInternal函数,实现如下:private synchronized void startFileInternal(String src,
PermissionStatus permissions,
String holder,
String clientMachine,
boolean overwrite,
boolean append,
short replication,
long blockSize
) throws IOException {
//创建一个新的文件,状态为under construction,没有任何data block与之对应
long genstamp = nextGenerationStamp();
INodeFileUnderConstruction newNode = dir.addFile(src, permissions,
replication, blockSize, holder, clientMachine, clientNode, genstamp);
}<span style="font-family: Arial, sans-serif; font-size: 20px; background-color: rgb(255, 255, 255);">3.2.3 客户端通过DFSOutputStream向dataQueue写Packet数据</span>
下面轮到客户端向新创建的文件中写入数据了,一般会使用FSDataOutputStream的write函数,最终会调用DFSOutputStream的writeChunk函数:
按照HDFS的设计,对block的数据写入使用的是pipeline的方式,也即将数据分成一个个的package,如果需要复制三分,分别写入DataNode 1, 2, 3,则会进行如下的过程:首先将package 1写入DataNode 1;然后由DataNode 1负责将package 1写入DataNode 2,同时客户端可以将pacage 2写入DataNode 1;然后DataNode 2负责将package 1写入DataNode 3, 同时客户端可以讲package 3写入DataNode
1,DataNode 1将package 2写入DataNode 2;就这样将一个个package排着队的传递下去,直到所有的数据全部写入并复制完毕
protected synchronized void writeChunk(byte[] b, int offset, int len, byte[] checksum)
throws IOException {
if (currentPacket == null) {
//创建一个packet,并写入数据
currentPacket = new Packet(packetSize, chunksPerPacket,
bytesCurBlock);
currentPacket.writeChecksum(checksum, 0, cklen);
currentPacket.writeData(b, offset, len);
currentPacket.numChunks++;
bytesCurBlock += len;
//如果此packet已满,则放入队列中准备发送
if (currentPacket.numChunks == currentPacket.maxChunks ||
bytesCurBlock == blockSize) {
dataQueue.addLast(currentPacket);
//唤醒等待dataqueue的传输线程,也即DataStreamer
dataQueue.notifyAll();
currentPacket = null;
}
}
}<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);"> DataStreamer的run函数如下:</span>
<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);"></span><pre name="code" class="java">public void run() {
while (!closed && clientRunning) {
Packet one = null;
synchronized (dataQueue) {
//如果队列中没有packet,则等待
while ((!closed && !hasError && clientRunning && dataQueue.size() == 0)
|| doSleep) {
try {
dataQueue.wait(1000);
} catch (InterruptedException e) {
}
doSleep = false;
}
try {
//得到队列中的第一个packet
one = dataQueue.getFirst();
long offsetInBlock = one.offsetInBlock;
//请求NameNode分配block,并生成一个写入流指向此block
if (blockStream == null) {
nodes = nextBlockOutputStream(src);
response = new ResponseProcessor(nodes);
response.start();
}
ByteBuffer buf = one.getBuffer();
//将packet从dataQueue移至ackQueue,等待DataNode写成功ack请求
dataQueue.removeFirst();
dataQueue.notifyAll();
synchronized (ackQueue) {
ackQueue.addLast(one);
ackQueue.notifyAll();
}
//利用生成的写入流将数据写入DataNode中的block
blockStream.write(buf.array(), buf.position(), buf.remaining());
if (one.lastPacketInBlock) {
blockStream.writeInt(0); //表示此block写入完毕
}
blockStream.flush(); //刷新写到DataNode中
} catch (Throwable e) {
}
if (one.lastPacketInBlock) {
synchronized (ackQueue) {
// 阻塞等待直到收到当前Block的所有Packet的ack请求
while (!hasError && ackQueue.size() != 0 && clientRunning) {
try {
ackQueue.wait(); // wait for acks to arrive from datanodes
} catch (InterruptedException e) {
}
}
}
}
}
}其中重要的一个函数是nextBlockOutputStream,实现如下:
private DatanodeInfo[] nextBlockOutputStream(String client) throws IOException {
LocatedBlock lb = null;
boolean retry = false;
DatanodeInfo[] nodes;
int count = conf.getInt("dfs.client.block.write.retries", 3);
boolean success;
do {
//请求NameNode为文件分配一个Block
lb = locateFollowingBlock(startTime);
block = lb.getBlock();
nodes = lb.getLocations();
//创建目标DataNode的写入流
success = createBlockOutputStream(nodes, clientName, false);
} while (retry && --count >= 0);
return nodes;
}<span style="font-family: Arial, sans-serif; background-color: rgb(255, 255, 255);"> locateFollowingBlock中通过RPC调用namenode.addBlock(src, clientName)函数</span>
3.2.4 客户端请求NameNode分配Block块及DataNode
NameNode的addBlock函数实现如下:public LocatedBlockaddBlock(String src,
String clientName) throws IOException {
LocatedBlock locatedBlock = namesystem.getAdditionalBlock(src, clientName);
return locatedBlock;
}FSNamesystem的getAdditionalBlock实现如下:
public LocatedBlockgetAdditionalBlock(String src,
String clientName
) throws IOException {
long fileLength, blockSize;
int replication;
DatanodeDescriptor clientNode = null;
Block newBlock = null;
//为新的block选择DataNode
DatanodeDescriptor targets[] = replicator.chooseTarget(replication,
clientNode,
null,
blockSize);
//得到文件路径中所有path的INode,其中最后一个是新添加的文件对应的INode,状态为under construction
INode[] pathINodes = dir.getExistingPathINodes(src);
int inodesLen = pathINodes.length;
INodeFileUnderConstruction pendingFile = (INodeFileUnderConstruction)
pathINodes[inodesLen - 1];
//为文件分配Block(一个HDFS文件可能有多个Block,每个Block可能有多个备份,BlockId相同)
newBlock = allocateBlock(src, pathINodes);
pendingFile.setTargets(targets);
return new LocatedBlock(newBlock, targets, fileLength);
}3.2.5 客户端创建目标DataNode的DataOutputStream输出流
在分配了DataNode和block以后,createBlockOutputStream开始写入数据。
private boolean createBlockOutputStream(DatanodeInfo[] nodes, String client,
boolean recoveryFlag) {
//创建一个Socket,连接DataNode,第一个为最优的写节点,比如是最近的节点
InetSocketAddress target = NetUtils.createSocketAddr(nodes[0].getName());
s = socketFactory.createSocket();
int timeoutValue = 3000 * nodes.length + socketTimeout;
s.connect(target, timeoutValue);
s.setSoTimeout(timeoutValue);
s.setSendBufferSize(DEFAULT_DATA_SOCKET_SIZE);
long writeTimeout = HdfsConstants.WRITE_TIMEOUT_EXTENSION * nodes.length +
datanodeWriteTimeout;
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(NetUtils.getOutputStream(s, writeTimeout),
DataNode.SMALL_BUFFER_SIZE));
blockReplyStream = new DataInputStream(NetUtils.getInputStream(s));
//写入指令
out.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
out.write( DataTransferProtocol.OP_WRITE_BLOCK );
out.writeLong( block.getBlockId() );
out.writeLong( block.getGenerationStamp() );
out.writeInt( nodes.length );
out.writeBoolean( recoveryFlag );
Text.writeString( out, client );
out.writeBoolean(false);
out.writeInt( nodes.length - 1 );
//注意,次循环从1开始,而非从0开始。将除了第一个DataNode以外的另外两个DataNode的信息发送给第一个DataNode, 第一个DataNode可以根据此信息将数据写给另两个DataNode
for (int i = 1; i < nodes.length; i++) {
nodes[i].write(out);
}
checksum.writeHeader( out );
out.flush();
firstBadLink = Text.readString(blockReplyStream);
if (firstBadLink.length() != 0) {
throw new IOException("Bad connect ack with firstBadLink " + firstBadLink);
}
// 设置为目标DataNode输出流
blockStream = out;
}客户端在DataStreamer的run函数中创建了写入流后,调用blockStream.write将数据写入DataNode
3.2.6 DataNode通过BlockReceiver接收客户端的Block数据
数据最终会发送到DataNode节点上,在一个DataNode上,数据在各个组件之间流动,流程如下图所示:图8 DataNode数据流程图
DataNode服务中创建一个后台线程DataXceiverServer,它是一个SocketServer,用来接收来自Client(或者DataNode Pipeline中的非最后一个DataNode节点)的写数据请求,然后在DataXceiverServer中将连接过来的Socket直接派发给一个独立的后台线程DataXceiver进行处理。所以,Client写数据时连接一个DataNode
Pipeline的结构,实际流程如图所示:
图9 DataNode-Pipeline数据流程图
DataNode的DataXceiver中,收到指令DataTransferProtocol.OP_WRITE_BLOCK则调用writeBlock函数:
private void writeBlock(DataInputStream in) throws IOException {
DatanodeInfo srcDataNode = null;
//读入头信息,比如BlockId
Block block = new Block(in.readLong(),
dataXceiverServer.estimateBlockSize, in.readLong());
int pipelineSize = in.readInt(); // num of datanodes in entire pipeline
boolean isRecovery = in.readBoolean(); // is this part of recovery?
String client = Text.readString(in); // working on behalf of this client
boolean hasSrcDataNode = in.readBoolean(); // is src node info present
if (hasSrcDataNode) {
srcDataNode = new DatanodeInfo();
srcDataNode.readFields(in);
}
int numTargets = in.readInt();
if (numTargets < 0) {
throw new IOException("Mislabelled incoming datastream.");
}
//读入剩下的DataNode列表,如果当前是第一个DataNode,则此列表中收到的是第二个,第三个DataNode的信息,如果当前是第二个DataNode,则受到的是第三个DataNode的信息
DatanodeInfo targets[] = new DatanodeInfo[numTargets];
for (int i = 0; i < targets.length; i++) {
DatanodeInfo tmp = new DatanodeInfo();
tmp.readFields(in);
targets[i] = tmp;
}
DataOutputStream mirrorOut = null; // stream to next target
DataInputStream mirrorIn = null; // reply from next target
DataOutputStream replyOut = null; // stream to prev target
Socket mirrorSock = null; // socket to next target
BlockReceiver blockReceiver = null; // responsible for data handling
String mirrorNode = null; // the name:port of next target
String firstBadLink = ""; // first datanode that failed in connection setup
try {
//生成一个BlockReceiver, 其有成员变量DataInputStream in为从客户端或者上一个DataNode读取数据,还有成员变量DataOutputStream mirrorOut,用于向下一个DataNode写入数据,还有成员变量OutputStream out用于将数据写入本地。
blockReceiver = new BlockReceiver(block, in,
s.getRemoteSocketAddress().toString(),
s.getLocalSocketAddress().toString(),
isRecovery, client, srcDataNode, datanode);
// get a connection back to the previous target
replyOut = new DataOutputStream(
NetUtils.getOutputStream(s, datanode.socketWriteTimeout));
//如果当前不是最后一个DataNode,则同下一个DataNode建立socket连接
if (targets.length > 0) {
InetSocketAddress mirrorTarget = null;
// Connect to backup machine
mirrorNode = targets[0].getName();
mirrorTarget = NetUtils.createSocketAddr(mirrorNode);
mirrorSock = datanode.newSocket();
int timeoutValue = numTargets * datanode.socketTimeout;
int writeTimeout = datanode.socketWriteTimeout +
(HdfsConstants.WRITE_TIMEOUT_EXTENSION * numTargets);
mirrorSock.connect(mirrorTarget, timeoutValue);
mirrorSock.setSoTimeout(timeoutValue);
mirrorSock.setSendBufferSize(DEFAULT_DATA_SOCKET_SIZE);
//创建向下一个DataNode写入数据的流
mirrorOut = new DataOutputStream(
new BufferedOutputStream(
NetUtils.getOutputStream(mirrorSock, writeTimeout),
SMALL_BUFFER_SIZE));
mirrorIn = new DataInputStream(NetUtils.getInputStream(mirrorSock));
mirrorOut.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
mirrorOut.write( DataTransferProtocol.OP_WRITE_BLOCK );
mirrorOut.writeLong( block.getBlockId() );
mirrorOut.writeLong( block.getGenerationStamp() );
mirrorOut.writeInt( pipelineSize );
mirrorOut.writeBoolean( isRecovery );
Text.writeString( mirrorOut, client );
mirrorOut.writeBoolean(hasSrcDataNode);
if (hasSrcDataNode) { // pass src node information
srcDataNode.write(mirrorOut);
}
mirrorOut.writeInt( targets.length - 1 );
//此出也是从1开始,将除了下一个DataNode的其他DataNode信息发送给下一个DataNode
for ( int i = 1; i < targets.length; i++ ) {
targets[i].write( mirrorOut );
}
blockReceiver.writeChecksumHeader(mirrorOut);
mirrorOut.flush();
}
//使用BlockReceiver接受block
String mirrorAddr = (mirrorSock == null) ? null : mirrorNode;
blockReceiver.receiveBlock(mirrorOut, mirrorIn, replyOut,
mirrorAddr, null, targets.length);
} finally {
// close all opened streams
IOUtils.closeStream(mirrorOut);
IOUtils.closeStream(mirrorIn);
IOUtils.closeStream(replyOut);
IOUtils.closeSocket(mirrorSock);
IOUtils.closeStream(blockReceiver);
}
} BlockReceiver的receiveBlock函数中,一段重要的逻辑如下:void receiveBlock(
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
String mirrAddr, BlockTransferThrottler throttlerArg,
int numTargets) throws IOException {
//不断的接受packet,直到结束
while (receivePacket() > 0) {}
if (mirrorOut != null) {
try {
mirrorOut.writeInt(0); // mark the end of the block
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
}BlockReceiver的receivePacket函数如下:
private int receivePacket() throws IOException {
//从客户端或者上一个节点接收一个packet
int payloadLen = readNextPacket();
buf.mark();
//read the header
buf.getInt(); // packet length
offsetInBlock = buf.getLong(); // get offset of packet in block
long seqno = buf.getLong(); // get seqno
boolean lastPacketInBlock = (buf.get() != 0);
int endOfHeader = buf.position();
buf.reset();
setBlockPosition(offsetInBlock);
//将package写入下一个DataNode
if (mirrorOut != null) {
try {
mirrorOut.write(buf.array(), buf.position(), buf.remaining());
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
buf.position(endOfHeader);
int len = buf.getInt();
offsetInBlock += len;
int checksumLen = ((len + bytesPerChecksum - 1)/bytesPerChecksum)*
checksumSize;
int checksumOff = buf.position();
int dataOff = checksumOff + checksumLen;
byte pktBuf[] = buf.array();
buf.position(buf.limit()); // move to the end of the data.
//将数据写入本节点的Block块文件中
out.write(pktBuf, dataOff, len);
/// flush entire packet before sending ack
flush();
// put in queue for pending acks
if (responder != null) {
((PacketResponder)responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
}
return payloadLen;
}HDFS写文件过程具体序列图如下:
图10 HDFS写文件序列图一
图11 HDFS写文件序列图二
3.3 HDFS读文件过程源码分析
HDFS有一个FileSystem实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件。HDFS通过RPC调用NameNode获取文件块的位置信息,对于文件的每一个块,NameNode会返回含有该块副本的DataNode的节点地址,另外,客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的那个DataNode获取数据块的副本,最理想的情况是数据块就存储在客户端所在的节点上。HDFS会返回一个FSDataInputStream对象,FSDataInputStream类转而封装成DFSDataInputStream对象,这个对象管理着与DataNode和NameNode的I/O,流程如下图: 图12 HDFS读文件数据流程图
具体过程描述如下:客户端发起读请求;客户端从NameNode得到文件的块及位置信息列表;客户端直接和DataNode交互读取数据;读取完成关闭连接。
3.3.1 客户端调用DistributedFileSystem打开文件
HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为:public FSDataInputStream open(Path f, int bufferSize) throws IOException {
return new DFSClient.DFSDataInputStream(
dfs.open(getPathName(f), bufferSize, verifyChecksum, statistics));
} 其中dfs为DistributedFileSystem的成员变量DFSClient,其open函数被调用,其中创建一个DFSInputStream(src, buffersize, verifyChecksum)并返回。在DFSInputStream的构造函数中,openInfo函数被调用,其主要从namenode中得到要打开的文件所对应的blocks的信息,实现如下:synchronized void openInfo() throws IOException {
LocatedBlocks newInfo = callGetBlockLocations(namenode, src, 0, prefetchSize);
this.locatedBlocks = newInfo;
this.currentNode = null;
}
private static LocatedBlocks callGetBlockLocations(ClientProtocol namenode,
String src, long start, long length) throws IOException {
return namenode.getBlockLocations(src, start, length);
} LocatedBlocks主要包含一个链表的List<LocatedBlock> blocks,其中每个LocatedBlock包含如下信息:Block b:此block的信息。
long offset:此block在文件中的偏移。
DatanodeInfo[] locs:此block位于哪些DataNode上
上面namenode.getBlockLocations是一个RPC调用,最终调用NameNode类的getBlockLocations函数。
3.3.2 从NameNode获取文件的Block列表信息
NameNode.getBlockLocations实现如下:public LocatedBlocks getBlockLocations(String src,long offset,long length) throws IOException {
return namesystem.getBlockLocations(getClientMachine(),src, offset, length);
}namesystem是NameNode一个成员变量,其类型为FSNamesystem,保存的是NameNode的name space树,其中一个重要的成员变量为FSDirectory dir。
FSDirectory和Lucene中的FSDirectory没有任何关系,其主要包括FSImage fsImage,用于读写硬盘上的fsimage文件,FSImage类有成员变量FSEditLog editLog,用于读写硬盘上的edit文件,这两个文件的关系在上一篇文章中已经解释过。FSDirectory还有一个重要的成员变量INodeDirectoryWithQuota rootDir,INodeDirectoryWithQuota的父类为INodeDirectory,实现如下:
public class INodeDirectory extends INode {
private List<INode> children;
}由此可见INodeDirectory本身是一个INode,其中包含一个链表的INode,此链表中,如果仍为文件夹,则是类型INodeDirectory,如果是文件,则是类型INodeFile,INodeFile中有成员变量BlockInfo blocks[],是此文件包含的block的信息。显然这是一棵树形的结构。FSNamesystem.getBlockLocations函数如下:
public LocatedBlocks getBlockLocations(String src, long offset, long length,
boolean doAccessTime) throws IOException {
final LocatedBlocks ret = getBlockLocationsInternal(src, dir.getFileINode(src),
offset, length, Integer.MAX_VALUE, doAccessTime);
return ret;
}dir.getFileINode(src)通过路径名从文件系统树中找到INodeFile,其中保存的是要打开的文件的INode的信息。
getBlockLocationsInternal的实现如下:
private synchronized LocatedBlocks getBlockLocationsInternal(String src,
INodeFile inode,
long offset,
long length,
int nrBlocksToReturn,
boolean doAccessTime)
throws IOException {
//得到此文件的block信息
Block[] blocks = inode.getBlocks();
List<LocatedBlock> results = new ArrayList<LocatedBlock>(blocks.length);
//计算从offset开始,长度为length所涉及的blocks
int curBlk = 0;
long curPos = 0, blkSize = 0;
int nrBlocks = (blocks[0].getNumBytes() == 0) ? 0 : blocks.length;
for (curBlk = 0; curBlk < nrBlocks; curBlk++) {
blkSize = blocks[curBlk].getNumBytes();
if (curPos + blkSize > offset) {
//当offset在curPos和curPos + blkSize之间的时候,curBlk指向offset所在的block
break;
}
curPos += blkSize;
}
long endOff = offset + length;
//循环,依次遍历从curBlk开始的每个block,直到当前位置curPos越过endOff
do {
int numNodes = blocksMap.numNodes(blocks[curBlk]);
int numCorruptNodes = countNodes(blocks[curBlk]).corruptReplicas();
int numCorruptReplicas = corruptReplicas.numCorruptReplicas(blocks[curBlk]);
boolean blockCorrupt = (numCorruptNodes == numNodes);
int numMachineSet = blockCorrupt ? numNodes :
(numNodes - numCorruptNodes);
//依次找到此block所对应的datanode,将其中没有损坏的放入machineSet中
DatanodeDescriptor[] machineSet = new DatanodeDescriptor[numMachineSet];
if (numMachineSet > 0) {
numNodes = 0;
for(Iterator<DatanodeDescriptor> it =
blocksMap.nodeIterator(blocks[curBlk]); it.hasNext();) {
DatanodeDescriptor dn = it.next();
boolean replicaCorrupt = corruptReplicas.isReplicaCorrupt(blocks[curBlk], dn);
if (blockCorrupt || (!blockCorrupt && !replicaCorrupt))
machineSet[numNodes++] = dn;
}
}
//使用此machineSet和当前的block构造一个LocatedBlock
results.add(new LocatedBlock(blocks[curBlk], machineSet, curPos,
blockCorrupt));
curPos += blocks[curBlk].getNumBytes();
curBlk++;
} while (curPos < endOff
&& curBlk < blocks.length
&& results.size() < nrBlocksToReturn);
//使用此LocatedBlock链表构造一个LocatedBlocks对象返回
return inode.createLocatedBlocks(results);
}通过RPC调用,从NameNode得到LocatedBlocks对象,作为成员变量构造DFSInputStream对象,最后包装为FSDataInputStream返回给用户。
3.3.3 客户端通过DFSInputStream读数据
文件读取的时候,客户端利用文件打开的时候得到的FSDataInputStream.read(long position, byte[] buffer, int offset, int length)函数进行文件读操作。FSDataInputStream会调用其封装的DFSInputStream的read(long position, byte[] buffer, int offset, int length)函数,实现如下:
public int read(long position, byte[] buffer, int offset, int length)
throws IOException {
long filelen = getFileLength();
int realLen = length;
if ((position + length) > filelen) {
realLen = (int)(filelen - position);
}
// 首先得到包含从offset到offset + length内容的block列表
// 比如对于64M一个block的文件系统来说,欲读取从100M开始,长度为128M的数据,则block列表包括第2,3,4块block
List<LocatedBlock> blockRange = getBlockRange(position, realLen);
int remaining = realLen;
// 对每一个block,从中读取内容
// 对于上面的例子,对于第2块block,读取从36M开始,读取长度28M,对于第3块,读取整一块64M,对于第4块,读取从0开始,长度为36M,共128M数据
for (LocatedBlock blk : blockRange) {
long targetStart = position - blk.getStartOffset();
long bytesToRead = Math.min(remaining, blk.getBlockSize() - targetStart);
// 按照所需范围获取每个Block的数据
fetchBlockByteRange(blk, targetStart,
targetStart + bytesToRead - 1, buffer, offset);
remaining -= bytesToRead;
position += bytesToRead;
offset += bytesToRead;
}
assert remaining == 0 : "Wrong number of bytes read.";
if (stats != null) {
stats.incrementBytesRead(realLen);
}
return realLen;
}其中getBlockRange函数如下:
private synchronized List<LocatedBlock> getBlockRange(long offset,long length) throws IOException {
List<LocatedBlock> blockRange = new ArrayList<LocatedBlock>();
//首先从缓存的locatedBlocks中查找offset所在的block在缓存链表中的位置
int blockIdx = locatedBlocks.findBlock(offset);
if (blockIdx < 0) { // block is not cached
blockIdx = LocatedBlocks.getInsertIndex(blockIdx);
}
long remaining = length;
long curOff = offset;
while(remaining > 0) {
LocatedBlock blk = null;
//按照blockIdx的位置找到block
if(blockIdx < locatedBlocks.locatedBlockCount())
blk = locatedBlocks.get(blockIdx);
//如果block为空,则缓存中没有此block,则直接从NameNode中查找这些block,并加入缓存
if (blk == null || curOff < blk.getStartOffset()) {
LocatedBlocks newBlocks;
newBlocks = callGetBlockLocations(namenode, src, curOff, remaining);
locatedBlocks.insertRange(blockIdx, newBlocks.getLocatedBlocks());
continue;
}
//如果block找到,则放入结果集
blockRange.add(blk);
long bytesRead = blk.getStartOffset() + blk.getBlockSize() - curOff;
remaining -= bytesRead;
curOff += bytesRead;
//取下一个block
blockIdx++;
}
return blockRange;
}其中fetchBlockByteRange实现如下:
private void fetchBlockByteRange(LocatedBlock block, long start,long end, byte[] buf, int offset) throws IOException {
Socket dn = null;
int numAttempts = block.getLocations().length;
//此while循环为读取失败后的重试次数
while (dn == null && numAttempts > 0 ) {
//选择一个DataNode来读取数据,最优的DataNode,比如离Client最近的
DNAddrPair retval = chooseDataNode(block);
DatanodeInfo chosenNode = retval.info;
InetSocketAddress targetAddr = retval.addr;
BlockReader reader = null;
try {
//创建Socket连接到DataNode
dn = socketFactory.createSocket();
dn.connect(targetAddr, socketTimeout);
dn.setSoTimeout(socketTimeout);
int len = (int) (end - start + 1);
//利用建立的Socket链接,生成一个reader负责从DataNode读取数据
reader = BlockReader.newBlockReader(dn, src,
block.getBlock().getBlockId(),
block.getBlock().getGenerationStamp(),
start, len, buffersize,
verifyChecksum, clientName);
// 读取DataNode的Block的数据,按Packet循环读取
int nread = reader.readAll(buf, offset, len);
return;
} finally {
IOUtils.closeStream(reader);
IOUtils.closeSocket(dn);
dn = null;
}
//如果读取失败,则将此DataNode标记为失败节点
addToDeadNodes(chosenNode);
}
}BlockReader.newBlockReader函数实现如下:
public static BlockReader newBlockReader( Socket sock, String file,
long blockId,
long genStamp,
long startOffset, long len,
int bufferSize, boolean verifyChecksum,
String clientName)
throws IOException {
//使用Socket建立写入流,向DataNode发送读指令
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(NetUtils.getOutputStream(sock,HdfsConstants.WRITE_TIMEOUT)));
out.writeShort( DataTransferProtocol.DATA_TRANSFER_VERSION );
out.write( DataTransferProtocol.OP_READ_BLOCK );
out.writeLong( blockId );
out.writeLong( genStamp );
out.writeLong( startOffset );
out.writeLong( len );
Text.writeString(out, clientName);
out.flush();
//使用Socket建立读入流,用于从DataNode读取数据
DataInputStream in = new DataInputStream(
new BufferedInputStream(NetUtils.getInputStream(sock),
bufferSize));
DataChecksum checksum = DataChecksum.newDataChecksum(in);
long firstChunkOffset = in.readLong();
//生成一个reader,主要包含读入流,用于读取数据
return new BlockReader( file, blockId, in, checksum, verifyChecksum,
startOffset, firstChunkOffset, sock );
}BlockReader的readAll函数就是用上面生成的DataInputStream读取数据。
3.3.4 DataNode通过BlockSender发送Block数据
在DataNode启动的时候,会调用函数startDataNode,其中与数据读取有关的逻辑如下:void startDataNode(Configuration conf,AbstractList<File> dataDirs) throws IOException {
// 建立一个ServerSocket,并生成一个DataXceiverServer来监控客户端的链接
ServerSocket ss = (socketWriteTimeout > 0) ?
ServerSocketChannel.open().socket() : new ServerSocket();
Server.bind(ss, socAddr, 0);
ss.setReceiveBufferSize(DEFAULT_DATA_SOCKET_SIZE);
// adjust machine name with the actual port
tmpPort = ss.getLocalPort();
selfAddr = new InetSocketAddress(ss.getInetAddress().getHostAddress(),
tmpPort);
this.dnRegistration.setName(machineName + ":" + tmpPort);
this.threadGroup = new ThreadGroup("dataXceiverServer");
this.dataXceiverServer = new Daemon(threadGroup,
new DataXceiverServer(ss, conf, this));
this.threadGroup.setDaemon(true); // auto destroy when empty
} DataXceiverServer.run()函数如下: public void run() {
while (datanode.shouldRun) {
//接受客户端的链接
Socket s = ss.accept();
s.setTcpNoDelay(true);
//生成一个线程DataXceiver来对建立的连接提供服务
new Daemon(datanode.threadGroup,
new DataXceiver(s, datanode, this)).start();
}
try {
ss.close();
} catch (IOException ie) {
LOG.warn(datanode.dnRegistration + ":DataXceiveServer: "+ StringUtils.stringifyException(ie));
}
}DataXceiver.run()函数如下:
public void run() {
DataInputStream in=null;
try {
//建立一个输入流,读取客户端发送的指令
in = new DataInputStream(
new BufferedInputStream(NetUtils.getInputStream(s),
SMALL_BUFFER_SIZE));
short version = in.readShort();
boolean local = s.getInetAddress().equals(s.getLocalAddress());
byte op = in.readByte();
// Make sure the xciver count is not exceeded
int curXceiverCount = datanode.getXceiverCount();
long startTime = DataNode.now();
switch ( op ) {
//读取
case DataTransferProtocol.OP_READ_BLOCK:
//真正的读取数据
readBlock( in );
datanode.myMetrics.readBlockOp.inc(DataNode.now() - startTime);
if (local)
datanode.myMetrics.readsFromLocalClient.inc();
else
datanode.myMetrics.readsFromRemoteClient.inc();
break;
//写入
case DataTransferProtocol.OP_WRITE_BLOCK:
//真正的写入数据
writeBlock( in );
datanode.myMetrics.writeBlockOp.inc(DataNode.now() - startTime);
if (local)
datanode.myMetrics.writesFromLocalClient.inc();
else
datanode.myMetrics.writesFromRemoteClient.inc();
break;
}
} catch (Throwable t) {
LOG.error(datanode.dnRegistration + ":DataXceiver",t);
} finally {
IOUtils.closeStream(in);
IOUtils.closeSocket(s);
dataXceiverServer.childSockets.remove(s);
}
}
private void readBlock(DataInputStream in) throws IOException {
//读取指令
long blockId = in.readLong();
Block block = new Block( blockId, 0 , in.readLong());
long startOffset = in.readLong();
long length = in.readLong();
String clientName = Text.readString(in);
//创建一个写入流,用于向客户端写数据
OutputStream baseStream = NetUtils.getOutputStream(s,
datanode.socketWriteTimeout);
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(baseStream, SMALL_BUFFER_SIZE));
//生成BlockSender用于读取本地的block的数据,并发送给客户端
//BlockSender有一个成员变量InputStream blockIn用于读取本地block的数据
BlockSender blockSender = new BlockSender(block, startOffset, length,
true, true, false, datanode, clientTraceFmt);
out.writeShort(DataTransferProtocol.OP_STATUS_SUCCESS); // send op status
//向客户端写入Block数据,按Packet循环发送
long read = blockSender.sendBlock(out, baseStream, null);
} finally {
IOUtils.closeStream(out);
IOUtils.closeStream(blockSender);
}
}HDFS读文件过程具体序列图如下:

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- 详解HDFS Short Circuit Local Reads
- PropertyChangeListener简单理解
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序
- 二叉查找树