Hadoop II Windows下安装hadoop2.6.0-eclipse-plugin插件
2015-10-10 15:19
489 查看
相关环境:
虚拟机:VMWare(64位)
Linux版本:centOS6.5 64位
Windows版本:win10 64位
Hadoop版本:2.6.0
Eclipse版本:Juno Service Release 2(64位)
Windows中JDK版本:1.7.0_13(64位)
Linux中JDK版本:1.7.0_71(64位)
参考网页:
Windows下使用Hadoop2.6.0-eclipse-plugin插件
本文中,安装插件的主要流程借鉴了上述网页。本文额外还会列出一些自己安装环境时候遇到的问题及其解决方案。
本文安装插件时所用到的hadoop环境是我上一篇文章中所述的伪分布式环境,链接如下:Hadoop I 搭建Linux下Hadoop2.6.0伪分布式环境
安装JDK
在Windows中安装JDK的步骤在网上有很多,在这里就不详述了。
安装Eclipse
在网上下载eclipse-jee-juno-SR2.rar并安装,在这里不详述。在下文中,以$ECLIPSE_HOME代表Eclipse的安装路径。
安装Ant
1)下载
http://ant.apache.org/bindownload.cgi
下载其中的:apache-ant-1.9.4-bin.zip
2)解压
将下载完的ant解压到合适的路径下,如下图所示:

3)设置环境变量
新建ANT_HOME=D:\apache-ant-1.9.6(这里需要填写你自己的真实路径)
在PATH后面加 ;%ANT_HOME%\bin(注意最前面的分号)
4)cmd测试ant是否安装成功
若成功,会有如下图所示的显示:

安装Hadoop
1)下载hadoop包
hadoop-2.6.0.tar.gz
解压到本地磁盘,如图所示:

2)下载hadoop2x-eclipse-plugin-master.zip
解压到本地磁盘,如图所示:

3)下载并复制winutils+hadoop.dll等到bin目录下
下载winutils hadoop.dll等文件,解压并复制如下选中文件到hadoop-2.6.0\bin目录下。
文件包的下载地址如下(注意我的是64位):http://download.csdn.net/detail/u010997403/9169857

编译hadoop-eclipse-plugin插件
1)cd到hadoop2x-eclipse-plugin-master所在目录
2)执行ant jar
在命令行中执行如下命令:
ant jar -Dversion=2.6.0 -Declipse.home=[这里填你的eclipse目录路径] -Dhadoop.home=[这里填你的hadoop目录路径]
如下图所示:
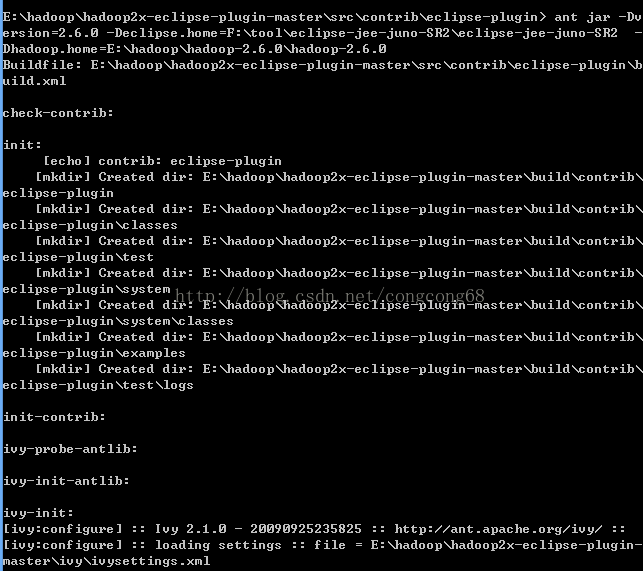
在编译过程中,可能遇到说jar包不存在的问题。可以直接从网上下相对应的jar包,或者直接去hadoop-2.6.0\share\hadoop\common\lib目录中,该目录中应该有相对应的jar包,只不过版本不对,我是直接把jar包名字改成了ant所需的jar包名。
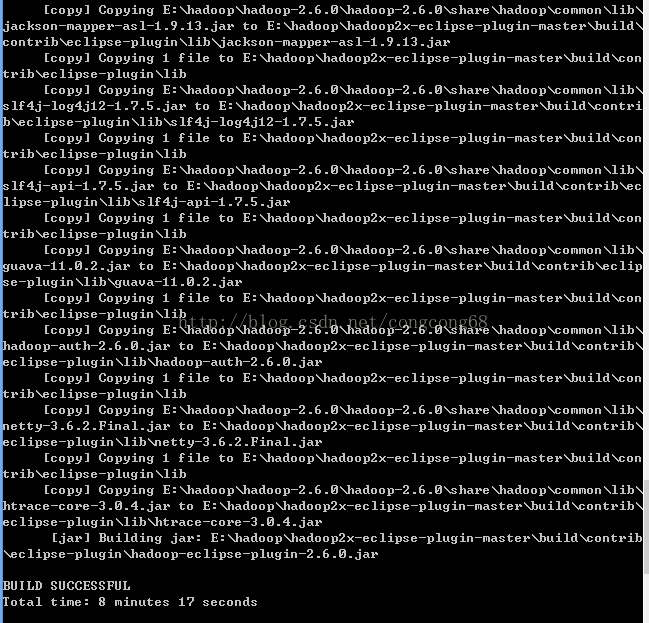
3)编译完成
编译生成的hadoop-eclipse-plugin-2.6.0.jar在hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin中。如下图所示:

Eclipse配置hadoop-eclipse-plugin插件
1)将jar包放入eclipse文件夹
将刚刚编译好的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse目录中的plugins文件夹。之后重启Eclipse,然后就可以看到如下图所示的内容:

如图中左侧红色框圈中的部分所示,如果插件安装成功,会出现DFS Locations。
如果没出现,则先看看图中右上角圈中的部分,是不是Java EE窗口。如果是的话,则关闭Eclipse,清理一下Eclipse缓存之后,再重新打开Eclipse试试。
2)添加Hadoop installation directory
打开Windows -> Preferens,可以看到Hadoop Map/Reduce选项,点击该选项,然后将hadoop2.6.0文件夹添加进来。如图所示:

3)配置Map/ReduceLocations
点击Window -> Show View -> Other -> MapReduce Tools -> Map/Reduce Locations,然后点击OK。
之后点击新出现的Map/Reduce Locations选项卡,点击右侧小象按钮,如图所示:

点击后会弹出New Hadoop Location窗口。如下图所示,填写红框圈中的内容。
左侧9001那部分的内容,是与你hdfs-site.xml中的dfs.namenode.secondary.http-address中的value一致。具体该配置文件的内容见我上一篇文章。
右侧9000那块的内容,是与你core-site.xml中的fs.defaultFS的value一致。

若点击小象按钮后,没弹出该窗口,则点击Window -> Show View -> Other -> General -> Error Log,打开Error Log窗口,看看里面有没有什么错误提示。如果有提示说NoClassDefFoundError的错误,则需要找到对应的jar包,然后将其放入之前编译的hadoop-eclipse-plugin-2.6.0.jar的lib目录中,然后打开jar包中META-INF目录中的MANIFEST.MF文件,在Bundle-ClassPath中添加该jar包的信息,如下图所示:

4)查看是否连接成功
若连接成功,则能看到类似如下图所示的内容。其中data/test/README.txt是我HDFS中所存的文件,这里是根据你HDFS中实际目录文件结构而定的。

新建MapReduce项目
点击File -> New -> Other弹出New窗口,选择Map/Reduce -> Map/Reduce Project。如下图所示:

新建Map/Reduce项目,如下图所示:

新建WordCount.java。然后从hadoop-2.6.0\share\hadoop\mapreduce\sources目录中的hadoop-mapreduce-examples-2.6.0-sources.jar中找到org\apache\hadoop\examples\WordCount.java,将其中的内容全部复制到自己新建的WordCount.java中,修改一下package的路径。复制过来的内容如下图所示:

在HDFS中创建input目录(输出目录可以不用创建,运行MapReduce时会自动创建),并上传一个file1.txt文件(随便写几个单词)
hdfs dfs -mkdir -p /test/input/
hadoop fs -put file1.txt /test/input

点击WordCount.java,右击 -> Run as -> Run Configurations。设置输入和输出目录路径。之后点击Apply,然后关闭窗口。如下图所示:

然后在WordCount.java上右击选择Run As -> Run on Hadoop。
如果运行成功,刷新一下HDFS中的test目录,会看到其中多了output目录,以及output目录中的内容。
其中part-r-00000就是WordCount的结果:

虚拟机:VMWare(64位)
Linux版本:centOS6.5 64位
Windows版本:win10 64位
Hadoop版本:2.6.0
Eclipse版本:Juno Service Release 2(64位)
Windows中JDK版本:1.7.0_13(64位)
Linux中JDK版本:1.7.0_71(64位)
参考网页:
Windows下使用Hadoop2.6.0-eclipse-plugin插件
本文中,安装插件的主要流程借鉴了上述网页。本文额外还会列出一些自己安装环境时候遇到的问题及其解决方案。
本文安装插件时所用到的hadoop环境是我上一篇文章中所述的伪分布式环境,链接如下:Hadoop I 搭建Linux下Hadoop2.6.0伪分布式环境
安装JDK
在Windows中安装JDK的步骤在网上有很多,在这里就不详述了。
安装Eclipse
在网上下载eclipse-jee-juno-SR2.rar并安装,在这里不详述。在下文中,以$ECLIPSE_HOME代表Eclipse的安装路径。
安装Ant
1)下载
http://ant.apache.org/bindownload.cgi
下载其中的:apache-ant-1.9.4-bin.zip
2)解压
将下载完的ant解压到合适的路径下,如下图所示:
3)设置环境变量
新建ANT_HOME=D:\apache-ant-1.9.6(这里需要填写你自己的真实路径)
在PATH后面加 ;%ANT_HOME%\bin(注意最前面的分号)
4)cmd测试ant是否安装成功
若成功,会有如下图所示的显示:
安装Hadoop
1)下载hadoop包
hadoop-2.6.0.tar.gz
解压到本地磁盘,如图所示:
2)下载hadoop2x-eclipse-plugin-master.zip
解压到本地磁盘,如图所示:
3)下载并复制winutils+hadoop.dll等到bin目录下
下载winutils hadoop.dll等文件,解压并复制如下选中文件到hadoop-2.6.0\bin目录下。
文件包的下载地址如下(注意我的是64位):http://download.csdn.net/detail/u010997403/9169857
编译hadoop-eclipse-plugin插件
1)cd到hadoop2x-eclipse-plugin-master所在目录
2)执行ant jar
在命令行中执行如下命令:
ant jar -Dversion=2.6.0 -Declipse.home=[这里填你的eclipse目录路径] -Dhadoop.home=[这里填你的hadoop目录路径]
如下图所示:
在编译过程中,可能遇到说jar包不存在的问题。可以直接从网上下相对应的jar包,或者直接去hadoop-2.6.0\share\hadoop\common\lib目录中,该目录中应该有相对应的jar包,只不过版本不对,我是直接把jar包名字改成了ant所需的jar包名。
3)编译完成
编译生成的hadoop-eclipse-plugin-2.6.0.jar在hadoop2x-eclipse-plugin-master\build\contrib\eclipse-plugin中。如下图所示:
Eclipse配置hadoop-eclipse-plugin插件
1)将jar包放入eclipse文件夹
将刚刚编译好的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse目录中的plugins文件夹。之后重启Eclipse,然后就可以看到如下图所示的内容:
如图中左侧红色框圈中的部分所示,如果插件安装成功,会出现DFS Locations。
如果没出现,则先看看图中右上角圈中的部分,是不是Java EE窗口。如果是的话,则关闭Eclipse,清理一下Eclipse缓存之后,再重新打开Eclipse试试。
2)添加Hadoop installation directory
打开Windows -> Preferens,可以看到Hadoop Map/Reduce选项,点击该选项,然后将hadoop2.6.0文件夹添加进来。如图所示:
3)配置Map/ReduceLocations
点击Window -> Show View -> Other -> MapReduce Tools -> Map/Reduce Locations,然后点击OK。
之后点击新出现的Map/Reduce Locations选项卡,点击右侧小象按钮,如图所示:
点击后会弹出New Hadoop Location窗口。如下图所示,填写红框圈中的内容。
左侧9001那部分的内容,是与你hdfs-site.xml中的dfs.namenode.secondary.http-address中的value一致。具体该配置文件的内容见我上一篇文章。
右侧9000那块的内容,是与你core-site.xml中的fs.defaultFS的value一致。
若点击小象按钮后,没弹出该窗口,则点击Window -> Show View -> Other -> General -> Error Log,打开Error Log窗口,看看里面有没有什么错误提示。如果有提示说NoClassDefFoundError的错误,则需要找到对应的jar包,然后将其放入之前编译的hadoop-eclipse-plugin-2.6.0.jar的lib目录中,然后打开jar包中META-INF目录中的MANIFEST.MF文件,在Bundle-ClassPath中添加该jar包的信息,如下图所示:
4)查看是否连接成功
若连接成功,则能看到类似如下图所示的内容。其中data/test/README.txt是我HDFS中所存的文件,这里是根据你HDFS中实际目录文件结构而定的。
新建MapReduce项目
点击File -> New -> Other弹出New窗口,选择Map/Reduce -> Map/Reduce Project。如下图所示:
新建Map/Reduce项目,如下图所示:
新建WordCount.java。然后从hadoop-2.6.0\share\hadoop\mapreduce\sources目录中的hadoop-mapreduce-examples-2.6.0-sources.jar中找到org\apache\hadoop\examples\WordCount.java,将其中的内容全部复制到自己新建的WordCount.java中,修改一下package的路径。复制过来的内容如下图所示:
在HDFS中创建input目录(输出目录可以不用创建,运行MapReduce时会自动创建),并上传一个file1.txt文件(随便写几个单词)
hdfs dfs -mkdir -p /test/input/
hadoop fs -put file1.txt /test/input
点击WordCount.java,右击 -> Run as -> Run Configurations。设置输入和输出目录路径。之后点击Apply,然后关闭窗口。如下图所示:
然后在WordCount.java上右击选择Run As -> Run on Hadoop。
如果运行成功,刷新一下HDFS中的test目录,会看到其中多了output目录,以及output目录中的内容。
其中part-r-00000就是WordCount的结果:

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- 详解HDFS Short Circuit Local Reads
- PropertyChangeListener简单理解
- 如何重装TCP/IP协议
- 插入排序
- 冒泡排序
- 堆排序