Machine Learning Week 1
2015-10-09 19:37
190 查看
Mathine Learning Week1
Mathine Learning Week1Classify
Supervised learning
Unsupervised learning
Liner Regression
Hypothesis Function
Cost Function
Gradient Descent
Classify
Supervised learning:
“right answers”giveni) Regression: Predict continuous valued outputs

ii) Classification: Discrete valued output(0 or 1 or even more)
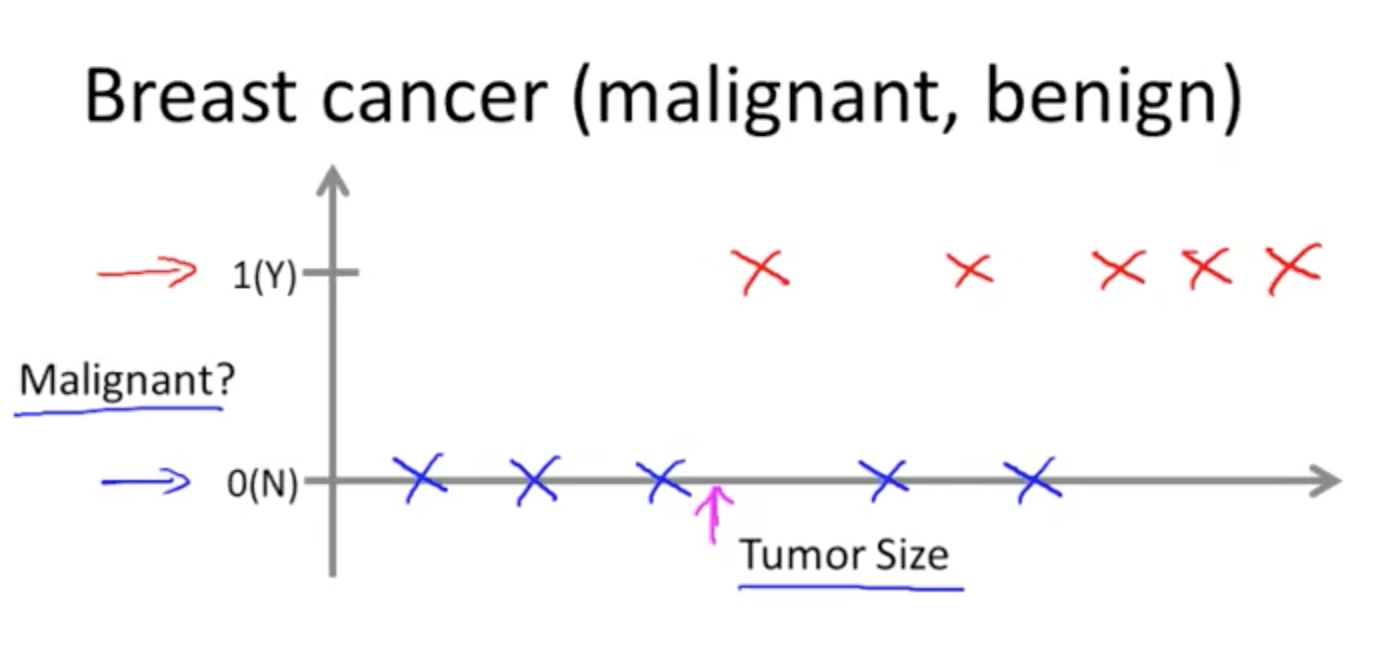
Unsupervised learning
Clustering(Algorithm)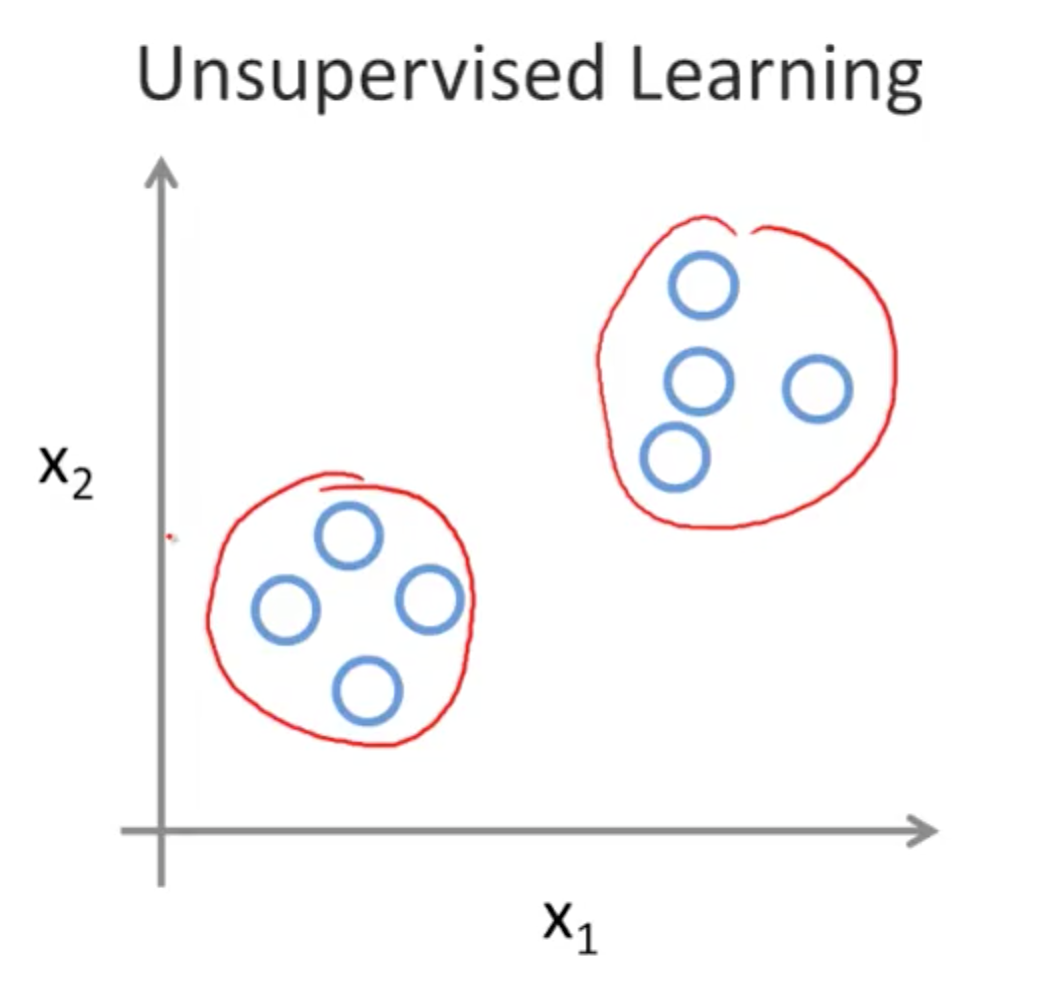
Liner Regression
Hypothesis Function
The Hypothesis Function:hθ(x)=θ0+θ1x
in details:
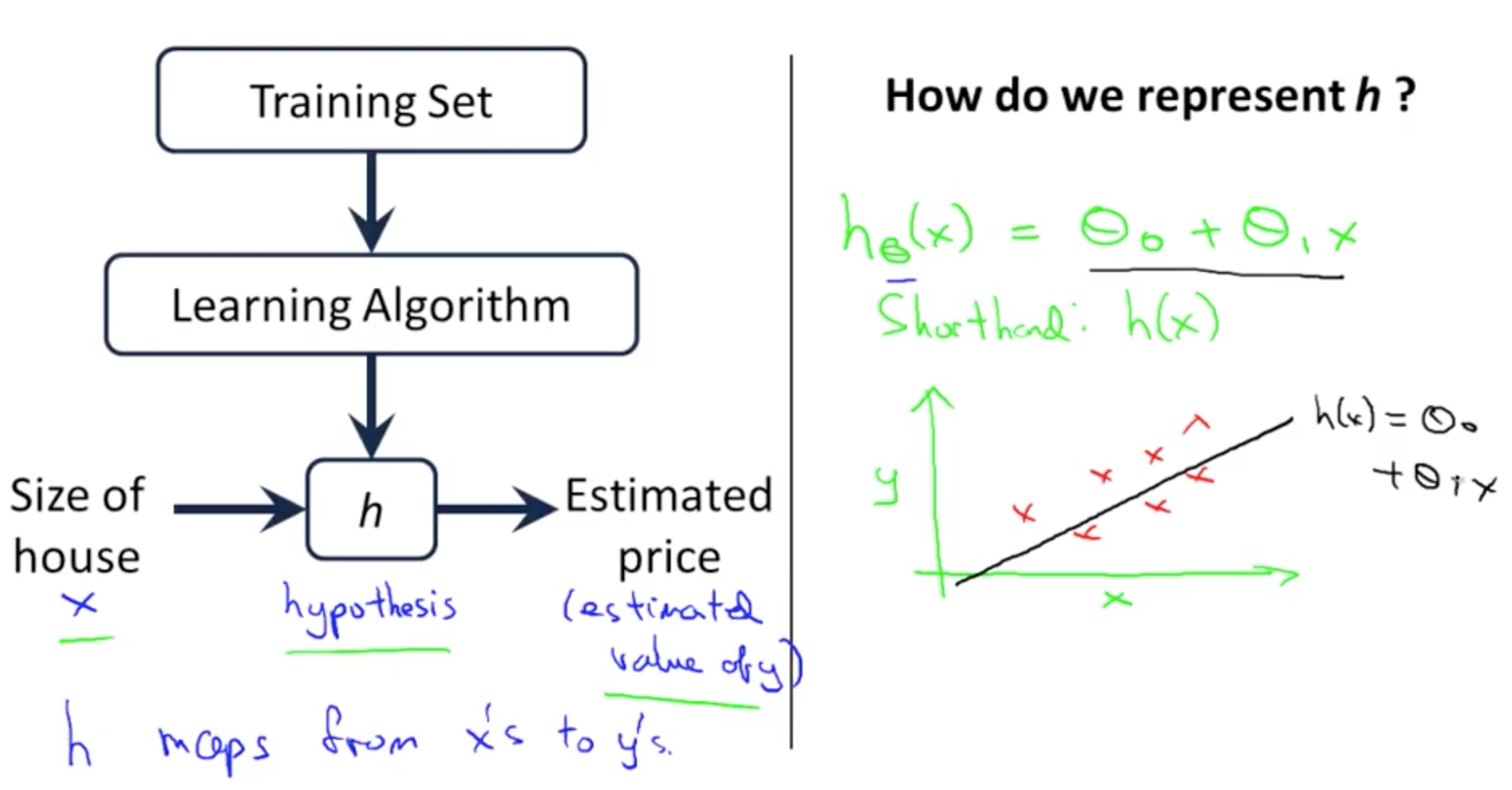
the way of choosing parameters:

Cost Function
Cost Function:J(θ0,θ1)=1<
4000
/span>2m∑i=1m(hθ(x(i)−y(i))2
3D cost function figures:
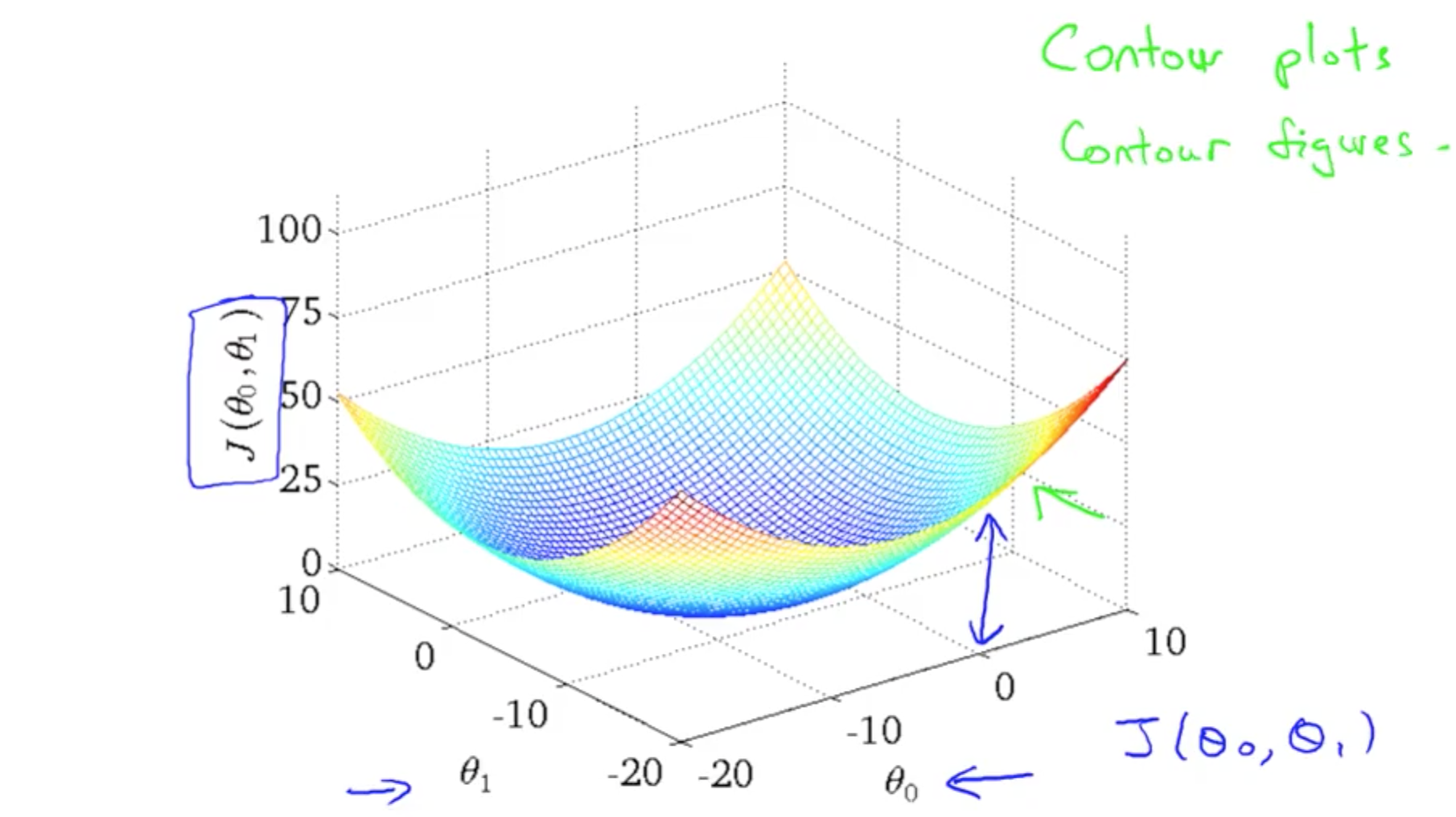
using contour figures to represent 3D plots:
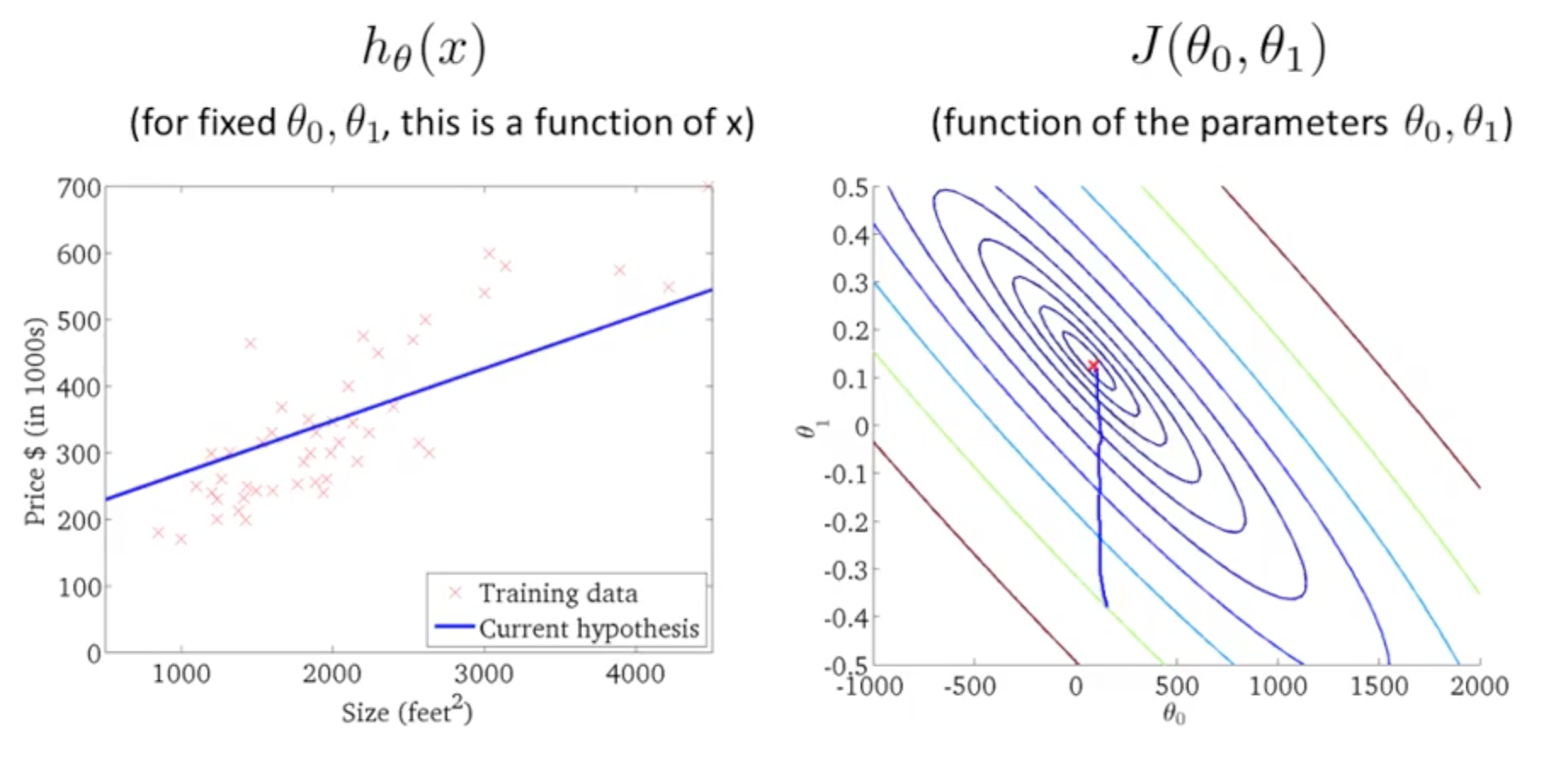
Gradient Descent
Gradient Descent:θj:=θj−α∂∂θjJ(θ0,θ1) for j=0 and j=1
Especially Gradient Descent for Linear Regression:
repeat until convergence:{θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))
θ1:=θ1−α1m∑i=1m((hθ(x(i))−y(i))x(i))}
Simultaneous update the parameters:

Gradient descent with one variable:
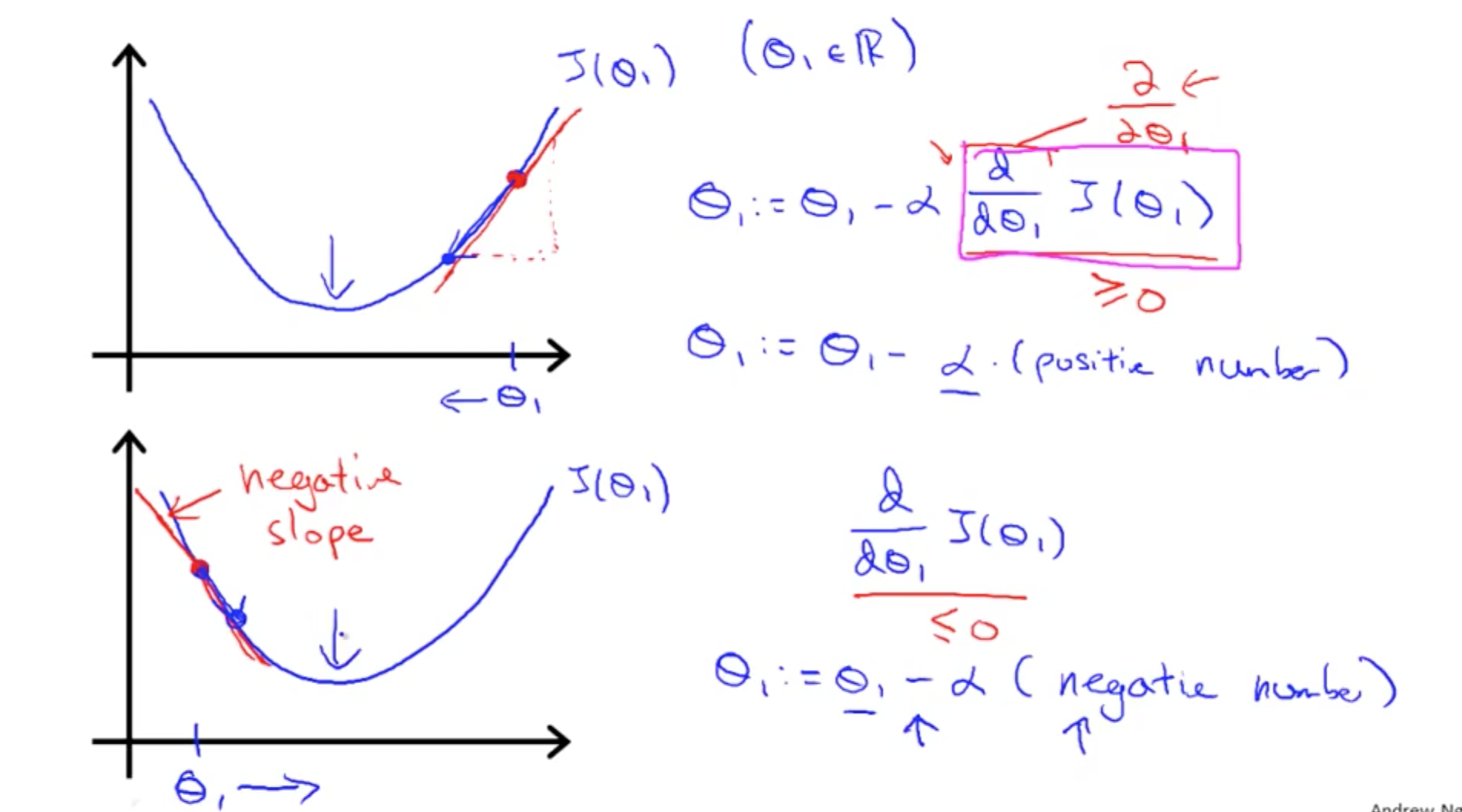
Why learning rate shouldn’t be too big or small:

But you can keep the learning rate fixed with the steps automatically getting small:
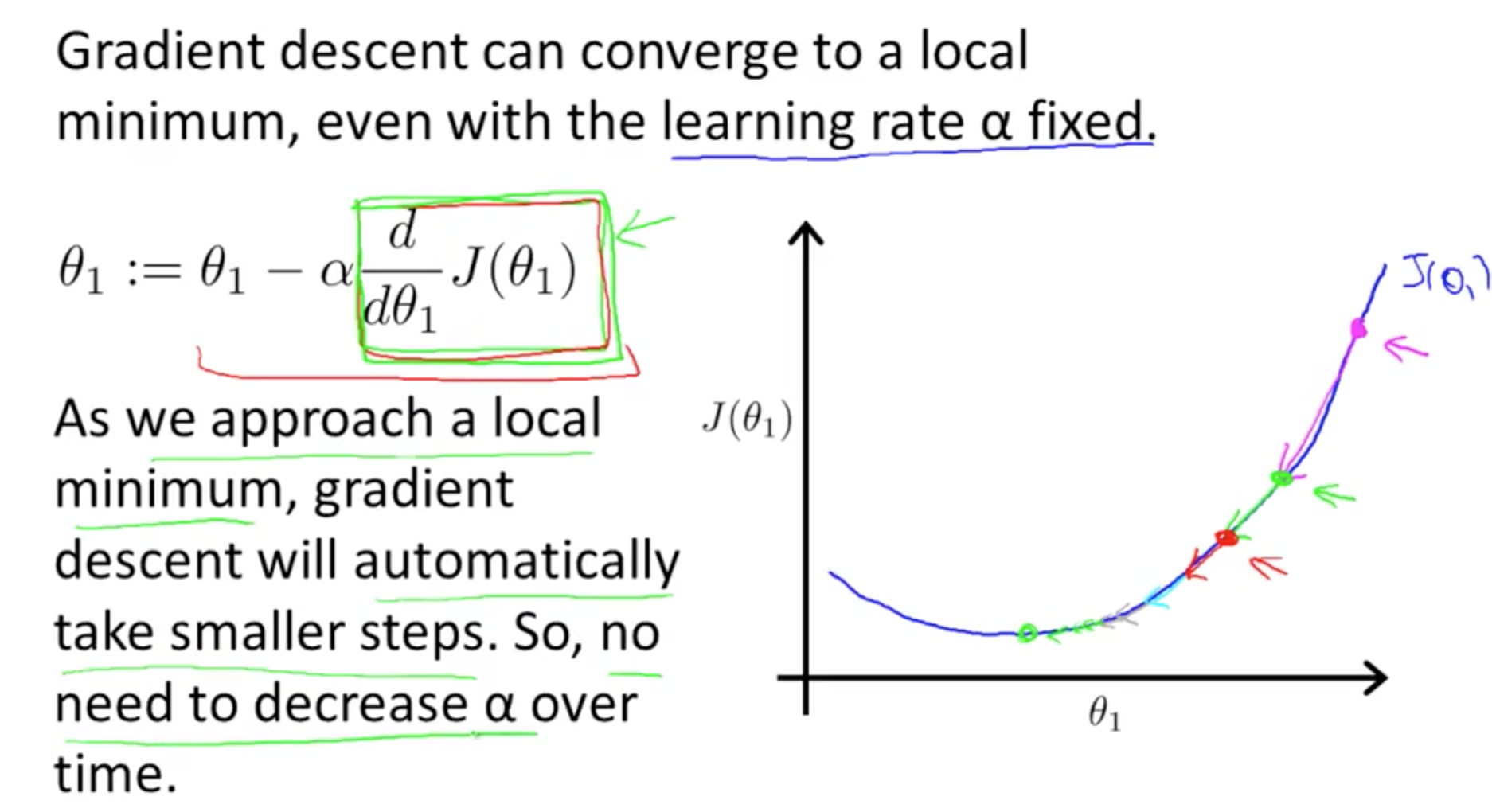
with 2 parameters:

Liner regression’s cost function is always bowl shape:
So there are no local optima but only one global optimum


相关文章推荐
- Android必备的Java知识点
- bzoj2005
- 第四周实践项目5--循环双链表应用
- NIOS II IDE编译出错:no file name for '-include'。Quartus ii中的.tcl文件run不起来
- 数组对称判断方法
- bzoj2005
- Android中的距离单位
- android集成微信支付(全是坑)
- junit 的classpath文件
- 51nod 01背包(DP)
- 编写Win32 lib时使用CString的方法
- 二分法查找
- 隐藏属性
- 正则表达式学习(基础篇)(原创)
- CS224D Deep Learning for NLP lecture2
- Android五大布局
- 《软件需求模式》阅读笔记一
- 20151009 C# 第一篇 程序编写规范
- INSTALL_FAILED_INSUFFICIENT_STORAGE.
- 浅谈技术管理(转载,讲的非常不错,技术和产品都值得一看)