Zabbix 监控之 - 报警篇 Actions
2015-10-08 22:41
330 查看
通常,一个报警的产生,是这样的一个过程。
如果某种条件符合,那么报警。
抽象成计算机语言,就是:
在Zabbix中,报警的途径是依附于用户的。即不能直接将一个Action设置为给某个邮箱发邮件,一定要设置Action向某个用户发送报警,发送报警的途径是邮箱,那么就会发送到用户的预先设置邮箱地址。 这个邮箱地址叫做用户的Media ,即联系方式。
下面来介绍Action的设置。
1,Action
Action是Zabbix非常强大的功能,可以基于Event的不同状态,执行不同的操作。 最常见的就是报警时,将报警通过各种方式发送给对应的用户。
目前Zabbix支持Action动作根据下面所列出的Events触发。
Trigger Events:当Trigger的状态变化,即从OK 到 Problem 或从 Problem 到OK时都会产生。
Discovery Events:当发生网络Discovery的时候产生。
Auto Registration Events: 当有新的Zabbix Agent自动注册到Zabbix的时候产生。
Internal Events:当Item变为“异常”状态 或者Trigger变为“未知”状态时产生。
下面进入Action的配置。
从菜单栏的“Configuration” → “Actions” 进入界面。
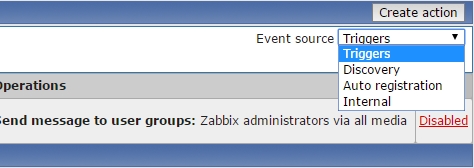
在“Event source”下拉框中,可以选择只显示依赖于某种源头的Action。
单击Action条目后,可以看到三个标签:“Action”、“Condition”、“Operations”。 “Action”用来定义Action本身的一些属性和说明;“Condition”用来定义触发Action的各种条件组合关系;“Operations”定义的是Action触发后的一些操作。
默认是建立基于Trigger Events的Action,如果需要其他的,选择对应的选项即可。

“Action”标签,有下面的属性可以设置。
Name:唯一的Action名字。
Default subject:报警的默认标题。
Default message:报警的默认内容。
Recovery message:恢复消息,是否在报警恢复正常后发送消息。 Zabbix将“OK”状态的Trigger认为是一个恢复recovery event。 注意:如果使用了Escalation机制,Recovery event只会触发一次。对已Recovery的报警,可以像发出报警的邮件一样,设置报警标题和内容。
以下几点需要注意:
1,自定义的恢复信息,只针对Condition,是“Trigger value is PROBLEM”的生效。
2,恢复信息只会发送给那些之前收到过关于这个Action报警信息的人。
3,恢复信息和Action 依赖PROBLEM生成的Evnet维护同一份ACK状态。
4,在Recovery信息中,EVENT.*Macro中的数据,都是基于出问题的Event,而不是Recovery。
5,在Recovery信息中,EVENT.RECOVERY.* 表示的是出自Recovery event的数据。
Recovery subject:Recovery信息的标题。
Recovery message:Recovery信息中的内容。
Enabled: 是否启用这个Action。
2,Operation
Operation指的是Action触发以后具体的操作,在Zabbix中,可以定义下面这些操作:
发送一条信息。
执行一个命令(包括IPMI)。
对于discovery事件,还有额外的一些操作:
添加一个Host。
移除一个Host。
启用一个Host。
禁用一个Host。
将Host添加到一个Host group。
将Host从一个Host grou中删除。
关联到一个Template。
取消和一个Template的关联。
对于auto-registration事件,也有额外的一些操作:
添加一个Host。
禁用一个Host。
添加Host到一个Host group。
关联到一个Template。
在配置Action的Operation标签页时,可以看到目前配置的Operation,单击“New”按钮。
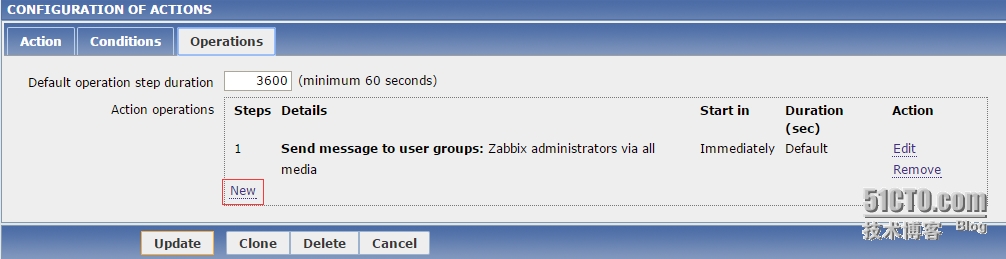
随后会出现配置一个新的Operation的界面

以下对各部分进行详细说明。
Default operation setp duration:最小是60秒,若设置为1小时(即这里的3600秒),则表明执行了一个操作后,要等待1个小时,才会执行下一个操作。
Action operations:需要设置的有Steps、Details、Start in、Duration(sec)和Action。
Steps:在escalation(报警的升级和扩散)的时候,会按照Step的顺序来执行,从1开始。
Details:操作的类型和目标。 从Zabbix 2.2开始,还会显示在发送信息时的media type(通知类型),用户的名字也会显示。
Start in:在Event发生后多久执行操作。
Duration(sec):显示的是Step的持续时间,如果Step使用了默认的“Default持续时间”,那么显示“Default”。
Action:显示的是两个标签“Edit”和“Remove”,用来编辑和移除Operation的操作。
Operation details:用来设置一个Operation的具体设置。
下面我们来看看Operation details的设置。
Step:在Escalation的过程中的执行计划。
From:表明从哪一步开始。
To:表明到哪一步结束。
Step duration:每一步持续的时间,如果填0,就是用上面的“Default operation setp duration”中的值。可以在同一个步骤中,进行多个操作。如果这些操作有多个duration,那么会选择最短的那个生效。
Operation type:选择操作的类型,可以选择的有如下两种。
- Send message:给用户发送信息(邮件,SMS信息 等,,)
- Remote command:远程执行命令。
注意:对于discovery事件和auto-registration 事件,可以在这里选择更多的操作。
Operation具体执行的操作是Operation的核心。在Zabbix中,“Send message”和“Remote command”是最重要的两个Operation。
报警的核心是什么?其一,是将问题通知到负责人; 其二,是对报警有对应的措施。 前者对应的是“Send message”功能,后者对应的是“Remote command”功能。
比方说,当一台PHP服务器的PHP进程意外退出后,Zabbix一边发送邮件给负责人,一边向Zabbix Agent发出命令,让他重启PHP服务器上的PHP进程。这是非常棒的处理流程。
下面,一起看下如何订制Operation。
首先看“Send message”,这个应该是所有Action都会具备的Operation。就算能够自动恢复(比如PHP进程重启),也需要将出错的信息及时发送给负责人。 对于“Send message”的配置有如下几点。
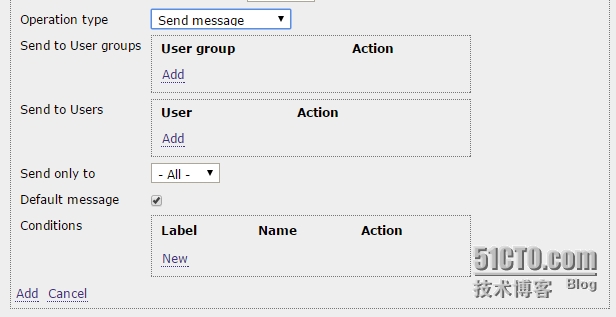
Send to User groups:可以添加一些User Group,将报警批量的发送给User Group中的所有User。
Send to User:类似于“Send to User groups”,只是发送警报的对象换成用户。
Send only to:选择是给“Send to User groups” 和 “Send to User”中发送消息时使用的Media type。 比如选择了“Email” ,那么就会向前面的User 发送电子邮件。
Default message:使用默认的消息格式。 默认这个是被打上勾的,取消选择,可以看到默认定义的消息格式。
Conditions:在后面进行介绍,因为它的设置是“Send message” 和“Remote command”所共有的。
注意,对于一个Host的报警,Zabbix只会把这个报警发送给这个Host至少有“读”权限的用户。Trigger中至少一个表达式关联的Host是正常工作的,即在Host中看到绿色的标识,

对于发送出去的消息,怎么查看历史消息呢? 怎么获知什么时间发送了什么消息呢?
在Monitoring→Events中可以看到有触发的Action列表。红色表示Action是失败的;“In progress”表示Action已经被触发了; “Failed”表示没有Action触发成功。
我们单击Event的时间,可以看到Action的细节,包括发送了信息的具体内容。
同时,我们也可以通过“Administration”→“Audit”在过滤条件中选择Action 就可以看到过去一段时间内发生的所有Action。
“Remote command”的参数有以下几种。

Target list:选择命令执行的Host,可以选择发生问题的Host,指定某个Host 或者 Host group。
Type:选择执行的命令的类型,其中“IPMI”、“SSH”、“Telnet”很好理解,主要看剩下的两个。
Custom script:执行在Commands 对话框中的Shell命令。
Global script:执行在Administration→Scripts中定义的一些命令。
Excute on:可以选择在Zabbix Agent还是Zabbix Server 上运行命令。
Conditions:后面进行单独介绍。
Remote command 最大的好处是什么呢? 是自动。 Zabbix会根据配置的条件,去执行对应的命令,下面看看Remote command的应用场景。
应用无法响应时,自动重启某些应用。
当服务器不响应时,使用IPMI的“reboot”命令重启服务器。
在磁盘要满了的情况下,自动删除一些文件(比如/tmp)。
根据CPU负载,自动进行虚拟机调配。
弹性计算,根据系统情况,新增或删除云节点。
Zabbix无法通过Zabbix Proxy向Zabbix Agent发送,一定要从Zabbix Server 发起。而且,发送的命令长度也有限制,即不能超过255个字符,这个对于一般命令绰绰有余了,只要不是cat某个文件之类的,都足够了。如果在多行写多个命令,Zabbix会按照顺序执行。而且在Remote command中,还支持Macro定义。
相比上面介绍的发送消息,Remote command稍显复杂。在Agent上执行的自定义脚本(即Custom scripts)一定要在Zabbix_agentd.conf中预先定义,而且在zabbix_agentd.conf中“EnableRemoteCommands”这一项要设置为1,否则无法远程执行命令。这是必然的,因为Active默认的Zabbix Agent其实根本没有在服务器上安装Zabbix Agent,怎么能发送命令给它执行呢?
对于远程执行命令,权限也是个问题。 默认情况下,Zabbix是没有权限来重启系统服务的,如果Zabbix用户想要有某个权限,需要修改下sudoer文件。
对于剩下的“Coditions”,它有两个选项“Not ACK” 和 “ACK”, “ACK”是“Acknowledge”的缩写,在Zabbix中,以为某个Evnet是否被人“认领”了,可以理解为,有没有在处理这个事情。 这里的“Not ack”和 “Ack”表达的在这种情况下需要执行Operation。如果选择“Not ack”,那么只有当Evnet没有被“Ack”的情况下需要执行。
3,Condition
报警,肯定是基于某个条件的,比如某个服务器的CPU负载超过20%。 在Zabbix,这种“条件”就是Trigger,那不能对每一个Trigger都设置一个Action吧? 最好的办法就是定义某一类的Trigger如果出问题了,就同意触发某个Action。Zabbix就是这么做的,它在Trigger和Action之间,抽象了一个Condition的概念。“Condition”的中文意思是“情况”,可以理解为某一种条件。即Action不是直接和Trigger挂钩,而是可以配置一组条件,如果都满足这些条件,就执行Action。 比如CPU负载超过20%这个Trigger,可能对于消耗CPU的服务器来说不需要报警,但是对于不消耗CPU的服务器来说就需要了。 那么可以组合这两个条件“CPU负载超过20%”和“服务器是CPU密集型”,对应到Zabbix,就是“CPU>20” 且 “Host属于CPU Host group”。
最常用的是基于Trigger的Evnet,在下表中,提到的Host等,指的都是和这个Event相关的Trigger中关联的Host。

如果设置的Condition中的任何一个对象(Host等)被删除了,那么这个相关的Condition会被删除,这个Action也会被禁用,放置出现错误执行Action,并且只能由用户自己重新启用。
Trigger的值是会变的,如果设置了“Trigger = Problem”,表示的是当Trigger从OK 变成PROBLEM的时候会被触发。反之亦然。
注意:使用 Trigger name like Traffic change > 400Mbps 类型的Contidions的时候 Traffic change > 400Mbps 不要跟容易引起歧义的关键字(当然你的Trigger名称可以包含该关键字),比如like的关键字是 Traffic change > 400Mbps Trigger 否则可能不会触发Action。
当创建一个Action的时候,默认会有两个Condition:一个是“Trigger=PROBLEM”,另一个是“Maintenance status=not in maintenance”。 为什么Zabbix要有这两个Condition呢?仔细想想是很有道理的,一般来说,我们的Action都是在某样东西出问题才需要行动的,而且,这个东西还不能是在维护中,否则明明有人维护这台服务器,Zabbix还在使劲的报警,就不好了。
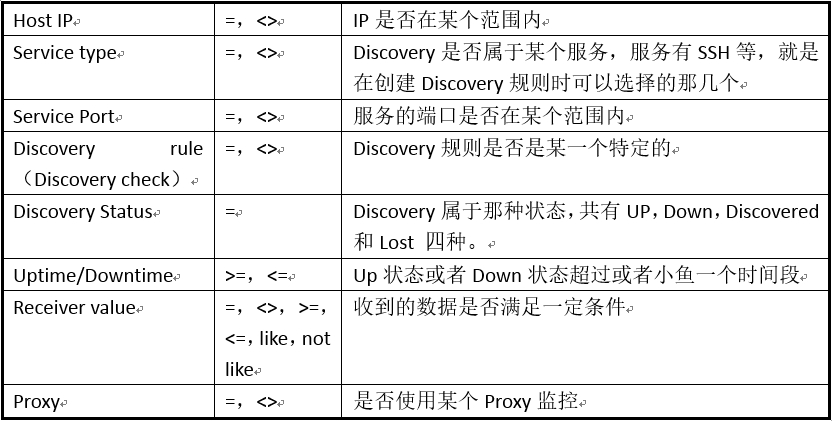
下表是基于Discovery 的Event可以使用的Condition。
下表是基于Active agent auto-registration的Condition。

下表是基于Zabbix内部事件的Condition。
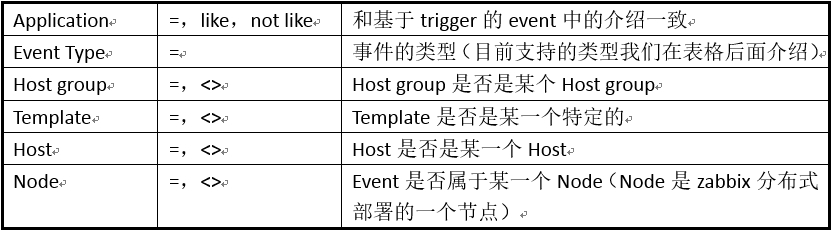
Event type中的事件类型有以下几种。
Item是“not supported”状态。
Item是“Normal”状态。
Low-level discovery 规则是“not supported”状态。
Low-level discovery 规则是“normal”状态。
Trigger是“unknown”状态。
Trigger是“normal”状态。
Event支持的Condition都介绍完了,对于不同的Condition的组合,Zabbix也有一套逻辑,比如需要同时满足两个Condition,又或者只要满足两个Condition中的一个等,Zabbix支持的Condition之间的逻辑运算符有以下几种。
AND:所有Condition同时满足。
OR:所有的Condition满足一个就行。
AND/OR:根据选择的条件,自动调整。选择相同类型的Condition时,他就变成and; 选择而不同的Condition,它就变成OR。
比如有下面这些Condition:
Host group = Oracle servers
Host group = MySQL servers
Trigger name like ‘Database is down’
Trigger name like ‘Database is unavailable’
那么最后组合的Condition就是(Host group = Oracle servers OR Host group = MySQL servers)AND (Trigger name like ‘Database is down’OR Trigger name like ‘Database is unavailable’)
4,Escalations
Escalation 的意思是“增大,扩大”,在Zabbix中,它指的意思是一个报警在一定条件下,会执行一些额外 的操作,比个比方,一台服务器磁盘满了,可能马上需要通知的是一线的运维工程师。如果6小时后都没人处理,这个故障且还没恢复,那么可能就要汇报给经理了。 或者,PHP进程挂了,可能首先是重启PHP进程,那么如果过了一段时间这个故障还没有恢复(即PHP进程没有重启成功),那么就要通知攻城师来进行恢复了。 这是一个报警扩散的过程,即Escalation 。
Zabbix中,支持的Escalation有以下几种。
发生问题后,第一时间通知用户。
在解决问题前,每隔一段时间就向用户报警。
延迟报警。
报警可以升级,发送给更多的用户。
Remote command可以在时间发生后马上执行,也可以在一定时间没有解决后才执行。
可以向用户发送恢复通知。
可以定义一个“Escalation Step”,意为“扩散步骤”,定义何时扩散报警,以及如何扩散。
每一个步骤可以定义一个Action和持续时间。步骤要在报警后马上发出,步骤个数没有限制,Zabbix只会从第一个开始逐个执行。
Escalation是一个比较复杂的机制,特别是跟其他东西结合起来后,下面看一些常见情况。
出问题的Host在发出第一个报警后进入了Maintainence状态:这个Action剩余的Escalation Step都会被执行。Maintainence状态不会停止Operation,只会对Action有关系简单的说,一旦这个Action被执行,那么其中的每一步都会执行。
在Time period中定义的时间在发出第一个报警后就结束了:同(A)中的情形,Time period也只会影响Action执行与否,而不会影响Action中的Operation执行与否。
在Maintainence状态时发生了问题,并且在Maintainence状态结束后依然没有恢复:所有Escalation Step都是从Host(或者其他)结束Maintainence状态后开始。
当Host在no-data Maintainence状态时发生问题,在结束no-date Maintainence状态时,这个问题还没有恢复:Trigger 的触发,一定是先于Escalation Step的开始。
不同的Escalation Step非常接近相互有重叠的部分:没一个Escalation都会接替之前的Escalation,但是由于步骤(A)是在问题发生后马上执行的,所以“之前的Escalation”至少会执行一个动作。这些行为跟Evnet 和 Action相关。
在Escalation执行过程中,Action被禁用了:正在发送过程中的信息和之后的那一条信息会被发送。其中后面的那条信息会在发送的信息之前加上“NOTE:Escalation cancelled:action‘<Action name>’ disabled”。这样,用户就会知道Action已经被禁用了,之后也不会受到关于这个Action的消息了。
Escalation稍微有点复杂,但很有用,下面一起看几则关于Escalation的例子,希望能帮助大家理解。
示例1:
要求每隔30分钟向“MySQL Administration”的User group发送一次报警,一共发送5次。
在Action的Operation标签中,将“Default operation step duration”(默认操作时间间隔)设置为1800秒,即要求中的30分钟。
在Steps的地方设置为“From 1 to 5”,表示Escalation Step的第一步到第五步都是执行这个操作。
选择“MySQL Administration”组作为发送报警的收件人。
通过这样的设置,假设Action是0点0分触发的,那么在0点30分,1点,1:30,2:00 都会将报警发送给“MySQL Administration”用户组中的所有用户,当然,如果在这个过程中,Trigger 恢复了,那么就会打断这些事件。
示例2:
如果示例1中的问题一直没有解决,我们希望吧这个问题通知到更加资深的DBA,可以进行下面的设置。
在Operation标签中,将默认时间设置为36000秒,即10个小时。
将escalation steps设置为“From 2 to 2”,意思就是只在第(2)步中执行。
在问题发生后,如果10个小时还没恢复,那么这个问题就会通知到资深DBA,可以在发送消息的内容中加上类似“这个问题已经10个小时没有处理”之类的话,提醒收到告警的工程师去解决。
示例3:
当出现问题时,先通知MySQL Administration,如果问题持续10个小时,将这个问题发送给DBA经理,如果还解决不了,会尝试重启数据库。 如果依然解决不了,那么只能邮件通知用户,最后使用IPMI命令,重启MySQL服务器。

示例4:
最后看一个自定义Duration的例子,先看是如何设置Action的。

假设问题是在00:00发生的,那么它的执行顺序如下。
在00:00、00:30、01:00、01:30 会向Zabbix administrators用户组发送邮件,这是由于我们设置了默认的时间间隔是1800秒,即30分钟。
在02:00 和 02:10向Admin发送邮件。
在02:00 、02:10 和 02:20 执行远程命令。
在04:00 向Admin 发送邮件。
这里有几个理解起来比较麻烦的地方,一个是在图中,只有02:00 和 02:10 时才会向 Admin发送邮件,而不会在03:00,这是因为在图中 5-6和5-7都设置了Operation,那么5-7中设置的600秒就会覆盖5-6中设置的3600秒。在条目3中,因为设置的600秒生效,所以每隔10分钟向Admin发送一次邮件。 在条目4中,由于经过了8、9、10、11则这4个Step,所以是默认的30分钟的4倍,即2个小时,到04:00,向Admin发送报警。
本文出自 “Professor哥” 博客,转载请与作者联系!
如果某种条件符合,那么报警。
抽象成计算机语言,就是:
if (ConditionA == true){
Alet();
}还可以选择给谁报警(哪个用户)、怎样报警(报警途径),具体如下:if (ConditionA == true){
Alert(userA.email);
Alert(userB.sms);
}如果处理问题不一定要报警,可以在服务器对于一些简单问题上运行一些命令的初步处理,比如Nginx挂了,自己就可以尝试的重启服务,则这又成了:if (ConditionA == true){
Alert(email);
Alert(sms);
Excute(command);
}再扩展一些,可能条件更复杂一些:if (ConditionA == true && ConditionB != true){
Alert(email);
Alert(sms);
Excute(command);
}这就是Zabbix的“报警”了,为什么这里的“报警”需要加上引号呢? 其实,发生问题后,去执行一些命令,这已经不是狭义上的“报警”了。在Zabbix 中,这个被定义为Action(动作) ,就是当某种Condition符合时,会进行一些操作,这些操作就叫做Action。 Condition译为“条件”,在Zabbix中,Action的触发是需要条件的,比如属于某个Host Group的Host,某个Trigger是Problem状态了,等等,,在Zabbix中,报警的途径是依附于用户的。即不能直接将一个Action设置为给某个邮箱发邮件,一定要设置Action向某个用户发送报警,发送报警的途径是邮箱,那么就会发送到用户的预先设置邮箱地址。 这个邮箱地址叫做用户的Media ,即联系方式。
下面来介绍Action的设置。
1,Action
Action是Zabbix非常强大的功能,可以基于Event的不同状态,执行不同的操作。 最常见的就是报警时,将报警通过各种方式发送给对应的用户。
目前Zabbix支持Action动作根据下面所列出的Events触发。
Trigger Events:当Trigger的状态变化,即从OK 到 Problem 或从 Problem 到OK时都会产生。
Discovery Events:当发生网络Discovery的时候产生。
Auto Registration Events: 当有新的Zabbix Agent自动注册到Zabbix的时候产生。
Internal Events:当Item变为“异常”状态 或者Trigger变为“未知”状态时产生。
下面进入Action的配置。
从菜单栏的“Configuration” → “Actions” 进入界面。
在“Event source”下拉框中,可以选择只显示依赖于某种源头的Action。
单击Action条目后,可以看到三个标签:“Action”、“Condition”、“Operations”。 “Action”用来定义Action本身的一些属性和说明;“Condition”用来定义触发Action的各种条件组合关系;“Operations”定义的是Action触发后的一些操作。
默认是建立基于Trigger Events的Action,如果需要其他的,选择对应的选项即可。
“Action”标签,有下面的属性可以设置。
Name:唯一的Action名字。
Default subject:报警的默认标题。
Default message:报警的默认内容。
Recovery message:恢复消息,是否在报警恢复正常后发送消息。 Zabbix将“OK”状态的Trigger认为是一个恢复recovery event。 注意:如果使用了Escalation机制,Recovery event只会触发一次。对已Recovery的报警,可以像发出报警的邮件一样,设置报警标题和内容。
以下几点需要注意:
1,自定义的恢复信息,只针对Condition,是“Trigger value is PROBLEM”的生效。
2,恢复信息只会发送给那些之前收到过关于这个Action报警信息的人。
3,恢复信息和Action 依赖PROBLEM生成的Evnet维护同一份ACK状态。
4,在Recovery信息中,EVENT.*Macro中的数据,都是基于出问题的Event,而不是Recovery。
5,在Recovery信息中,EVENT.RECOVERY.* 表示的是出自Recovery event的数据。
Recovery subject:Recovery信息的标题。
Recovery message:Recovery信息中的内容。
Enabled: 是否启用这个Action。
2,Operation
Operation指的是Action触发以后具体的操作,在Zabbix中,可以定义下面这些操作:
发送一条信息。
执行一个命令(包括IPMI)。
对于discovery事件,还有额外的一些操作:
添加一个Host。
移除一个Host。
启用一个Host。
禁用一个Host。
将Host添加到一个Host group。
将Host从一个Host grou中删除。
关联到一个Template。
取消和一个Template的关联。
对于auto-registration事件,也有额外的一些操作:
添加一个Host。
禁用一个Host。
添加Host到一个Host group。
关联到一个Template。
在配置Action的Operation标签页时,可以看到目前配置的Operation,单击“New”按钮。
随后会出现配置一个新的Operation的界面
以下对各部分进行详细说明。
Default operation setp duration:最小是60秒,若设置为1小时(即这里的3600秒),则表明执行了一个操作后,要等待1个小时,才会执行下一个操作。
Action operations:需要设置的有Steps、Details、Start in、Duration(sec)和Action。
Steps:在escalation(报警的升级和扩散)的时候,会按照Step的顺序来执行,从1开始。
Details:操作的类型和目标。 从Zabbix 2.2开始,还会显示在发送信息时的media type(通知类型),用户的名字也会显示。
Start in:在Event发生后多久执行操作。
Duration(sec):显示的是Step的持续时间,如果Step使用了默认的“Default持续时间”,那么显示“Default”。
Action:显示的是两个标签“Edit”和“Remove”,用来编辑和移除Operation的操作。
Operation details:用来设置一个Operation的具体设置。
下面我们来看看Operation details的设置。
Step:在Escalation的过程中的执行计划。
From:表明从哪一步开始。
To:表明到哪一步结束。
Step duration:每一步持续的时间,如果填0,就是用上面的“Default operation setp duration”中的值。可以在同一个步骤中,进行多个操作。如果这些操作有多个duration,那么会选择最短的那个生效。
Operation type:选择操作的类型,可以选择的有如下两种。
- Send message:给用户发送信息(邮件,SMS信息 等,,)
- Remote command:远程执行命令。
注意:对于discovery事件和auto-registration 事件,可以在这里选择更多的操作。
Operation具体执行的操作是Operation的核心。在Zabbix中,“Send message”和“Remote command”是最重要的两个Operation。
报警的核心是什么?其一,是将问题通知到负责人; 其二,是对报警有对应的措施。 前者对应的是“Send message”功能,后者对应的是“Remote command”功能。
比方说,当一台PHP服务器的PHP进程意外退出后,Zabbix一边发送邮件给负责人,一边向Zabbix Agent发出命令,让他重启PHP服务器上的PHP进程。这是非常棒的处理流程。
下面,一起看下如何订制Operation。
首先看“Send message”,这个应该是所有Action都会具备的Operation。就算能够自动恢复(比如PHP进程重启),也需要将出错的信息及时发送给负责人。 对于“Send message”的配置有如下几点。
Send to User groups:可以添加一些User Group,将报警批量的发送给User Group中的所有User。
Send to User:类似于“Send to User groups”,只是发送警报的对象换成用户。
Send only to:选择是给“Send to User groups” 和 “Send to User”中发送消息时使用的Media type。 比如选择了“Email” ,那么就会向前面的User 发送电子邮件。
Default message:使用默认的消息格式。 默认这个是被打上勾的,取消选择,可以看到默认定义的消息格式。
Conditions:在后面进行介绍,因为它的设置是“Send message” 和“Remote command”所共有的。
注意,对于一个Host的报警,Zabbix只会把这个报警发送给这个Host至少有“读”权限的用户。Trigger中至少一个表达式关联的Host是正常工作的,即在Host中看到绿色的标识,
对于发送出去的消息,怎么查看历史消息呢? 怎么获知什么时间发送了什么消息呢?
在Monitoring→Events中可以看到有触发的Action列表。红色表示Action是失败的;“In progress”表示Action已经被触发了; “Failed”表示没有Action触发成功。
我们单击Event的时间,可以看到Action的细节,包括发送了信息的具体内容。
同时,我们也可以通过“Administration”→“Audit”在过滤条件中选择Action 就可以看到过去一段时间内发生的所有Action。
“Remote command”的参数有以下几种。
Target list:选择命令执行的Host,可以选择发生问题的Host,指定某个Host 或者 Host group。
Type:选择执行的命令的类型,其中“IPMI”、“SSH”、“Telnet”很好理解,主要看剩下的两个。
Custom script:执行在Commands 对话框中的Shell命令。
Global script:执行在Administration→Scripts中定义的一些命令。
Excute on:可以选择在Zabbix Agent还是Zabbix Server 上运行命令。
Conditions:后面进行单独介绍。
Remote command 最大的好处是什么呢? 是自动。 Zabbix会根据配置的条件,去执行对应的命令,下面看看Remote command的应用场景。
应用无法响应时,自动重启某些应用。
当服务器不响应时,使用IPMI的“reboot”命令重启服务器。
在磁盘要满了的情况下,自动删除一些文件(比如/tmp)。
根据CPU负载,自动进行虚拟机调配。
弹性计算,根据系统情况,新增或删除云节点。
Zabbix无法通过Zabbix Proxy向Zabbix Agent发送,一定要从Zabbix Server 发起。而且,发送的命令长度也有限制,即不能超过255个字符,这个对于一般命令绰绰有余了,只要不是cat某个文件之类的,都足够了。如果在多行写多个命令,Zabbix会按照顺序执行。而且在Remote command中,还支持Macro定义。
相比上面介绍的发送消息,Remote command稍显复杂。在Agent上执行的自定义脚本(即Custom scripts)一定要在Zabbix_agentd.conf中预先定义,而且在zabbix_agentd.conf中“EnableRemoteCommands”这一项要设置为1,否则无法远程执行命令。这是必然的,因为Active默认的Zabbix Agent其实根本没有在服务器上安装Zabbix Agent,怎么能发送命令给它执行呢?
对于远程执行命令,权限也是个问题。 默认情况下,Zabbix是没有权限来重启系统服务的,如果Zabbix用户想要有某个权限,需要修改下sudoer文件。
# visudo #允许“Zabbix”用户不需要密码就可以运行所有root权限的命令 zabbix ALL=NOPASSWD: ALL #允许“zabbix”用户可以在不需要密码的情况下运行/etc/init.d/httpd restart ,即重启apache zabbix ALL=NOPASSWD: /etc/init.d/httpd restart如果Host上某一类的Interface有多个(比如有多个Zabbix Agent实例),那么Zabbix会选择默认的去运行。
对于剩下的“Coditions”,它有两个选项“Not ACK” 和 “ACK”, “ACK”是“Acknowledge”的缩写,在Zabbix中,以为某个Evnet是否被人“认领”了,可以理解为,有没有在处理这个事情。 这里的“Not ack”和 “Ack”表达的在这种情况下需要执行Operation。如果选择“Not ack”,那么只有当Evnet没有被“Ack”的情况下需要执行。
3,Condition
报警,肯定是基于某个条件的,比如某个服务器的CPU负载超过20%。 在Zabbix,这种“条件”就是Trigger,那不能对每一个Trigger都设置一个Action吧? 最好的办法就是定义某一类的Trigger如果出问题了,就同意触发某个Action。Zabbix就是这么做的,它在Trigger和Action之间,抽象了一个Condition的概念。“Condition”的中文意思是“情况”,可以理解为某一种条件。即Action不是直接和Trigger挂钩,而是可以配置一组条件,如果都满足这些条件,就执行Action。 比如CPU负载超过20%这个Trigger,可能对于消耗CPU的服务器来说不需要报警,但是对于不消耗CPU的服务器来说就需要了。 那么可以组合这两个条件“CPU负载超过20%”和“服务器是CPU密集型”,对应到Zabbix,就是“CPU>20” 且 “Host属于CPU Host group”。
最常用的是基于Trigger的Evnet,在下表中,提到的Host等,指的都是和这个Event相关的Trigger中关联的Host。
如果设置的Condition中的任何一个对象(Host等)被删除了,那么这个相关的Condition会被删除,这个Action也会被禁用,放置出现错误执行Action,并且只能由用户自己重新启用。
Trigger的值是会变的,如果设置了“Trigger = Problem”,表示的是当Trigger从OK 变成PROBLEM的时候会被触发。反之亦然。
注意:使用 Trigger name like Traffic change > 400Mbps 类型的Contidions的时候 Traffic change > 400Mbps 不要跟容易引起歧义的关键字(当然你的Trigger名称可以包含该关键字),比如like的关键字是 Traffic change > 400Mbps Trigger 否则可能不会触发Action。
当创建一个Action的时候,默认会有两个Condition:一个是“Trigger=PROBLEM”,另一个是“Maintenance status=not in maintenance”。 为什么Zabbix要有这两个Condition呢?仔细想想是很有道理的,一般来说,我们的Action都是在某样东西出问题才需要行动的,而且,这个东西还不能是在维护中,否则明明有人维护这台服务器,Zabbix还在使劲的报警,就不好了。
下表是基于Discovery 的Event可以使用的Condition。
下表是基于Active agent auto-registration的Condition。
下表是基于Zabbix内部事件的Condition。
Event type中的事件类型有以下几种。
Item是“not supported”状态。
Item是“Normal”状态。
Low-level discovery 规则是“not supported”状态。
Low-level discovery 规则是“normal”状态。
Trigger是“unknown”状态。
Trigger是“normal”状态。
Event支持的Condition都介绍完了,对于不同的Condition的组合,Zabbix也有一套逻辑,比如需要同时满足两个Condition,又或者只要满足两个Condition中的一个等,Zabbix支持的Condition之间的逻辑运算符有以下几种。
AND:所有Condition同时满足。
OR:所有的Condition满足一个就行。
AND/OR:根据选择的条件,自动调整。选择相同类型的Condition时,他就变成and; 选择而不同的Condition,它就变成OR。
比如有下面这些Condition:
Host group = Oracle servers
Host group = MySQL servers
Trigger name like ‘Database is down’
Trigger name like ‘Database is unavailable’
那么最后组合的Condition就是(Host group = Oracle servers OR Host group = MySQL servers)AND (Trigger name like ‘Database is down’OR Trigger name like ‘Database is unavailable’)
4,Escalations
Escalation 的意思是“增大,扩大”,在Zabbix中,它指的意思是一个报警在一定条件下,会执行一些额外 的操作,比个比方,一台服务器磁盘满了,可能马上需要通知的是一线的运维工程师。如果6小时后都没人处理,这个故障且还没恢复,那么可能就要汇报给经理了。 或者,PHP进程挂了,可能首先是重启PHP进程,那么如果过了一段时间这个故障还没有恢复(即PHP进程没有重启成功),那么就要通知攻城师来进行恢复了。 这是一个报警扩散的过程,即Escalation 。
Zabbix中,支持的Escalation有以下几种。
发生问题后,第一时间通知用户。
在解决问题前,每隔一段时间就向用户报警。
延迟报警。
报警可以升级,发送给更多的用户。
Remote command可以在时间发生后马上执行,也可以在一定时间没有解决后才执行。
可以向用户发送恢复通知。
可以定义一个“Escalation Step”,意为“扩散步骤”,定义何时扩散报警,以及如何扩散。
每一个步骤可以定义一个Action和持续时间。步骤要在报警后马上发出,步骤个数没有限制,Zabbix只会从第一个开始逐个执行。
Escalation是一个比较复杂的机制,特别是跟其他东西结合起来后,下面看一些常见情况。
出问题的Host在发出第一个报警后进入了Maintainence状态:这个Action剩余的Escalation Step都会被执行。Maintainence状态不会停止Operation,只会对Action有关系简单的说,一旦这个Action被执行,那么其中的每一步都会执行。
在Time period中定义的时间在发出第一个报警后就结束了:同(A)中的情形,Time period也只会影响Action执行与否,而不会影响Action中的Operation执行与否。
在Maintainence状态时发生了问题,并且在Maintainence状态结束后依然没有恢复:所有Escalation Step都是从Host(或者其他)结束Maintainence状态后开始。
当Host在no-data Maintainence状态时发生问题,在结束no-date Maintainence状态时,这个问题还没有恢复:Trigger 的触发,一定是先于Escalation Step的开始。
不同的Escalation Step非常接近相互有重叠的部分:没一个Escalation都会接替之前的Escalation,但是由于步骤(A)是在问题发生后马上执行的,所以“之前的Escalation”至少会执行一个动作。这些行为跟Evnet 和 Action相关。
在Escalation执行过程中,Action被禁用了:正在发送过程中的信息和之后的那一条信息会被发送。其中后面的那条信息会在发送的信息之前加上“NOTE:Escalation cancelled:action‘<Action name>’ disabled”。这样,用户就会知道Action已经被禁用了,之后也不会受到关于这个Action的消息了。
Escalation稍微有点复杂,但很有用,下面一起看几则关于Escalation的例子,希望能帮助大家理解。
示例1:
要求每隔30分钟向“MySQL Administration”的User group发送一次报警,一共发送5次。
在Action的Operation标签中,将“Default operation step duration”(默认操作时间间隔)设置为1800秒,即要求中的30分钟。
在Steps的地方设置为“From 1 to 5”,表示Escalation Step的第一步到第五步都是执行这个操作。
选择“MySQL Administration”组作为发送报警的收件人。
通过这样的设置,假设Action是0点0分触发的,那么在0点30分,1点,1:30,2:00 都会将报警发送给“MySQL Administration”用户组中的所有用户,当然,如果在这个过程中,Trigger 恢复了,那么就会打断这些事件。
示例2:
如果示例1中的问题一直没有解决,我们希望吧这个问题通知到更加资深的DBA,可以进行下面的设置。
在Operation标签中,将默认时间设置为36000秒,即10个小时。
将escalation steps设置为“From 2 to 2”,意思就是只在第(2)步中执行。
在问题发生后,如果10个小时还没恢复,那么这个问题就会通知到资深DBA,可以在发送消息的内容中加上类似“这个问题已经10个小时没有处理”之类的话,提醒收到告警的工程师去解决。
示例3:
当出现问题时,先通知MySQL Administration,如果问题持续10个小时,将这个问题发送给DBA经理,如果还解决不了,会尝试重启数据库。 如果依然解决不了,那么只能邮件通知用户,最后使用IPMI命令,重启MySQL服务器。
示例4:
最后看一个自定义Duration的例子,先看是如何设置Action的。
假设问题是在00:00发生的,那么它的执行顺序如下。
在00:00、00:30、01:00、01:30 会向Zabbix administrators用户组发送邮件,这是由于我们设置了默认的时间间隔是1800秒,即30分钟。
在02:00 和 02:10向Admin发送邮件。
在02:00 、02:10 和 02:20 执行远程命令。
在04:00 向Admin 发送邮件。
这里有几个理解起来比较麻烦的地方,一个是在图中,只有02:00 和 02:10 时才会向 Admin发送邮件,而不会在03:00,这是因为在图中 5-6和5-7都设置了Operation,那么5-7中设置的600秒就会覆盖5-6中设置的3600秒。在条目3中,因为设置的600秒生效,所以每隔10分钟向Admin发送一次邮件。 在条目4中,由于经过了8、9、10、11则这4个Step,所以是默认的30分钟的4倍,即2个小时,到04:00,向Admin发送报警。
本文出自 “Professor哥” 博客,转载请与作者联系!

相关文章推荐
- photoshop学习笔记
- Android和Linux kernel版本对应表
- Hadoop之HDFS---浅谈DN、NN、SNN
- nginx重新加载配置
- 【转】每天一个linux命令(1):ls命令
- properties类的相关用法
- 内核层监控进程 线程 创建和销毁
- Eclipse使用问题—Tomcat部署ClassNotFound问题
- linux sizeof 详解
- linux下socket编程(udp)
- 优设 - 一个前端设计相关网站
- 制作网页3---XAMPP的配置(环境是Linux Ubuntu)
- opencv2-6 图像分割MeanShift
- Linux内核模块指南(第十一章===>附录)。。。翻译完。。。
- 【Linux命令与工具】系统资源查看——free、uname、dmesg以及netstat
- S3C2440上移植内核之编译Linux2.6.31出现问题
- linux 初学者之进程控制
- Nginx介绍及企业web服务软件选择
- Linux性能测试strace命令
- 基本操作Linux系统服务器