一个例子解释MapReduce计算模型
2015-10-08 08:40
169 查看
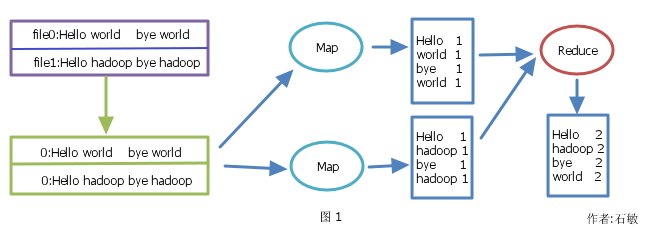
最近在学习关于Hadoop相关的知识,了解到了MapReduce这个优秀的编程模型。MapReduce是一个分析和处理大量数据的通用的解决方案,它许多的底层的细节处理,比如说数据切分,任务调度,存储,容错等这些对使用者来说是透明的,因此我们可以很方便的编写代码来并行的分析处理海量的数据。这个模型就是把一个大的任务划分成若干小的任务然后在不同的计算机中并行处理,最后化简合并得到一个结果,从而充分的利用集群中的存储和计算资源在一个合理的时间内完成大量数据的分析和处理任务。个人觉得这一处理过程有点像归并排序(虽然不是很严谨嘿嘿)的处理的特点。一个比较经典的例子就是文本的单词计数,比如说在文本检索领域我们通常会需要计算词频(TF),文档频率(DF)等都会用到这个。图1是这个例子的简单的数据流向图。
为了更通俗易懂的解释这个编程模型,我想出了一个感觉比较好的例子(可能不是很严谨),使得没有相关知识的人也能明白这种通用的并行计算模型。假如我有一批货物100吨要从A地运往B地,这时我有两种方式可以选择:
1)串行运输:全程只派一辆车运货,货车载重量为25吨,则把所有货物从A运到B需要4趟。如图2 所示。


2)并行运输:全程派4量车同时运输,反正成本差不多,而且道路这么宽。如图3 所示。

但是比较这两种方式的物流可知,单纯从运费来看,两者都差不多,即消耗的硬件资源是一样的,因为从整体来看,都只运输了4趟。但是并行运输方式要高效得多,运输所拥用时间基本上节约了3倍。而且假如串行运输方式中货车中途坏了,我们还必须忍受等它修好然后继续完成任务,这种方式是无法保证时间的,因为修车可能会花很多时间。但是对于并行运输方式,如果有一辆车坏了,我们可以等它修好后继续运输,还可以等从其它运输完的货车中再次调度一辆替代坏得货车完成任务,这种方式具有更大的灵活性,而且能保证任务能在一定时间范围内完成(最坏情况就是和一辆车运输的总时间一样),除非4辆车都坏了(现实中这种可能性很小)。这就是并行运输的好处。
总而言之,MapReduce计算模型使得大数据的处理分析变得容易快速,充分利用集群中计算机的计算能力,协同完成整个大的任务。当然它也有自己的不足之处,比如它在处理大量的小数据会显得力不从心。所以我们要首先弄明白自己的需求然后在选择合适的方法,这样才会打到预期的效果。
4000
为了更通俗易懂的解释这个编程模型,我想出了一个感觉比较好的例子(可能不是很严谨),使得没有相关知识的人也能明白这种通用的并行计算模型。假如我有一批货物100吨要从A地运往B地,这时我有两种方式可以选择:
1)串行运输:全程只派一辆车运货,货车载重量为25吨,则把所有货物从A运到B需要4趟。如图2 所示。
2)并行运输:全程派4量车同时运输,反正成本差不多,而且道路这么宽。如图3 所示。
但是比较这两种方式的物流可知,单纯从运费来看,两者都差不多,即消耗的硬件资源是一样的,因为从整体来看,都只运输了4趟。但是并行运输方式要高效得多,运输所拥用时间基本上节约了3倍。而且假如串行运输方式中货车中途坏了,我们还必须忍受等它修好然后继续完成任务,这种方式是无法保证时间的,因为修车可能会花很多时间。但是对于并行运输方式,如果有一辆车坏了,我们可以等它修好后继续运输,还可以等从其它运输完的货车中再次调度一辆替代坏得货车完成任务,这种方式具有更大的灵活性,而且能保证任务能在一定时间范围内完成(最坏情况就是和一辆车运输的总时间一样),除非4辆车都坏了(现实中这种可能性很小)。这就是并行运输的好处。
总而言之,MapReduce计算模型使得大数据的处理分析变得容易快速,充分利用集群中计算机的计算能力,协同完成整个大的任务。当然它也有自己的不足之处,比如它在处理大量的小数据会显得力不从心。所以我们要首先弄明白自己的需求然后在选择合适的方法,这样才会打到预期的效果。
4000

相关文章推荐
- [实验]10.9号实验内容(网络14)
- 一道网易笔试题
- 利用drawinrect在control中画入图片和文字
- java线程笔记
- 围城
- Jquery知识小点备注
- javascript实现下拉列表和复选框的选中
- xml追加节点
- CentOS7下升级glib
- 泛型委托
- Android GridView的简单使用
- FBO
- JAVA语法基础作业
- [优化篇]Ubuntu使用corosync+pacemaker+drbd实现MySQL的HA(1)
- javascript基础资料
- CentOS源码安装gftp缺失stropts.h
- 英语阅读网站推荐
- 根据客户区大小反推窗口大小
- 5 个在 Linux 中管理文件类型和系统时间的有用命令
- 倒数阶乘之和