Amazon Redshift and Massively Parellel Processing
2015-10-06 08:24
573 查看
Today, Yelp held a tech talk in Columbia University about the data warehouse adopted by Yelp.
Yelp used Amazon Redshift as data warehouse.
There are several features for Redshift:
1. Massively Parellel Processing
2. SQL access
3. Column-based Datastore
Benefits are:
1. Data is structured, accessible and well documented.
2. Architecture allows for easy extensibility and sharing across teams.
3. Allows use of entire SQL-compatible tool ecosystem.
Details:
Massively Parellel Processing (MMP)
Traditional BigData always uses Hadoop + MapReduce. MapReduce's native control mechanism is Java code (to implement the Map and Reduce logic), whereas MPP products are queried with SQL(Structural Query Language). You can refer detail here.
Below is the structure for implementing MMP.
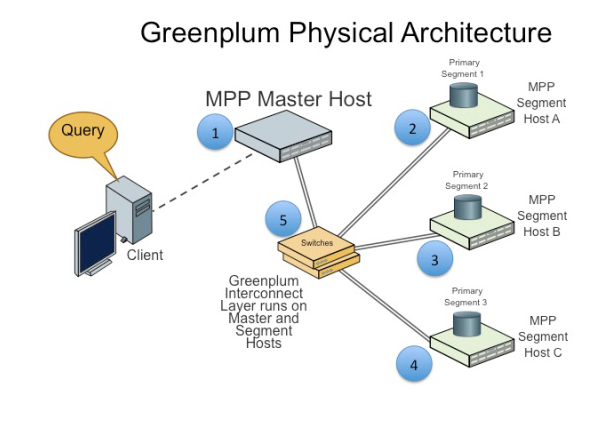
Similarly, Data is distributed across each segment database to achieve data and processing parallelism. This is achieved by creating a database table with DISTRIBUTED BY clause. By using this clause data is automatically distributed across segment databases. (referrence: Introduction to MMP)
Typical query sentence in MMP

Column-based Datastore
Enables sparse table definitions
Enables compact storage
Improve scanning/filtering
(Benefits: wiki)
Column-based Datastore
Column-oriented organizations are more efficient when an aggregate needs to be computed over many rows but only for a notably smaller subset of all columns of data, because reading that smaller subset of data can be faster than reading all data.
Column-oriented organizations are more efficient when new values of a column are supplied for all rows at once, because that column data can be written efficiently and replace old column data without touching any other columns for the rows.
Row-oriented organizations are more efficient when many columns of a single row are required at the same time, and when row-size is relatively small, as the entire row can be retrieved with a single disk seek.
Row-oriented organizations are more efficient when writing a new row if all of the row data is supplied at the same time, as the entire row can be written with a single disk seek.
In practice, row-oriented storage layouts are well-suited for OLTP-like workloads which are more heavily loaded with interactive transactions. Column-oriented storage layouts are well-suited for OLAP-like workloads (e.g., data warehouses) which typically involve a smaller number of highly complex queries over all data (possibly terabytes).
Yelp used Amazon Redshift as data warehouse.
There are several features for Redshift:
1. Massively Parellel Processing
2. SQL access
3. Column-based Datastore
Benefits are:
1. Data is structured, accessible and well documented.
2. Architecture allows for easy extensibility and sharing across teams.
3. Allows use of entire SQL-compatible tool ecosystem.
Details:
Massively Parellel Processing (MMP)
Traditional BigData always uses Hadoop + MapReduce. MapReduce's native control mechanism is Java code (to implement the Map and Reduce logic), whereas MPP products are queried with SQL(Structural Query Language). You can refer detail here.
Below is the structure for implementing MMP.
Similarly, Data is distributed across each segment database to achieve data and processing parallelism. This is achieved by creating a database table with DISTRIBUTED BY clause. By using this clause data is automatically distributed across segment databases. (referrence: Introduction to MMP)
Typical query sentence in MMP
Column-based Datastore
Enables sparse table definitions
Enables compact storage
Improve scanning/filtering
(Benefits: wiki)
Column-based Datastore
Column-oriented organizations are more efficient when an aggregate needs to be computed over many rows but only for a notably smaller subset of all columns of data, because reading that smaller subset of data can be faster than reading all data.
Column-oriented organizations are more efficient when new values of a column are supplied for all rows at once, because that column data can be written efficiently and replace old column data without touching any other columns for the rows.
Row-oriented organizations are more efficient when many columns of a single row are required at the same time, and when row-size is relatively small, as the entire row can be retrieved with a single disk seek.
Row-oriented organizations are more efficient when writing a new row if all of the row data is supplied at the same time, as the entire row can be written with a single disk seek.
In practice, row-oriented storage layouts are well-suited for OLTP-like workloads which are more heavily loaded with interactive transactions. Column-oriented storage layouts are well-suited for OLAP-like workloads (e.g., data warehouses) which typically involve a smaller number of highly complex queries over all data (possibly terabytes).

相关文章推荐
- Haar特征
- 经方败案群0924高坤锋鼻炎、咳嗽语音发言整理版
- 音频播放AVAudioPlayer后台播放
- HDU 1222 Wolf and Rabbit(数论)
- 执行eclipse,迅速failed to create the java virtual machine。
- Linux高性能server规划——多线程编程(在)
- ZXV10 B700V5机顶盒支持的无线网卡主芯片
- ifree卡黄金版和普通ifree卡的区别
- POJ 3074 解题报告
- 一秒解决直接双击启动tomcat-startup.bat闪退
- 直连网线和交叉网线
- UI初级连载12-------------滑动视图
- this 的用法
- *LeetCode-Find the Duplicate Number
- 揭秘利用互联网营销的全国拍卖骗子公司 - (深圳拍卖公司)
- Matlab Error (Matrix dimensions must agree)
- 不要学习代码,要学会思考
- 持有对象:总结JAVA中的常用容器和迭代器,随机数 速查
- 数据结构实践项目——队列
- 经方败案群9月鼻炎专题第1场交流整理版