Memcached简介
2015-10-04 23:10
441 查看
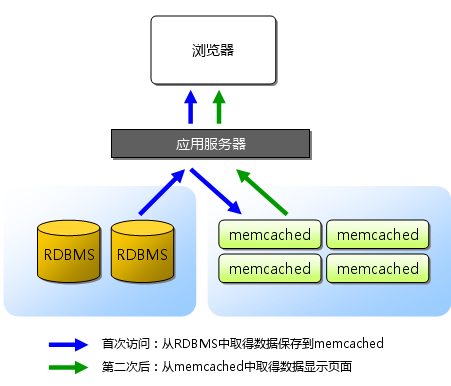
Memcached简介:Memcached是一款开源、高性能、分布式内存对象缓存系统,可应用各种需要缓存的场景,其主要目的是通过降低对Database的访问来加速web应用程序。它是一个基于内存的“键值对”存储,用于存储数据库调用、API调用或页面引用结果的直接数据,如字符串、对象等。Memcached是以LiveJournal旗下Danga Interactive 公司的Brad Fitzpatric 为首开发的一款软件。现在已成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。许多Web应用都将数据保存到RDBMS(关系型数据库管理系统)中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。这时就该Memcached大显身手了。Memcached是高性能的分布式内存缓存服务器。 一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。如下图,
Memcached是一款开发工具,它既不是一个代码加速器,也不是数据库中间件。其设计哲学思想主要反映在如下方面: 1. 简单key/value存储:服务器不关心数据本身的意义及结构,只要是可序列化数据即可。存储项由“键、过期时间、可选的标志及数据”四个部分组成。 2. 功能的实现一半依赖于客户端,一半基于服务器端:客户负责发送存储项至服务器端、从服务端获取数据以及无法连接至服务器时采用相应的动作;服务端负责接收、存储数据,并负责数据项的超时过期。 3. 各服务器间彼此无视,不在服务器间进行数据同步。 4. O(1)的执行效率。 5. 清理超期数据,默认情况下,Memcached是一个LRU缓存,同时,它按事先预订的时长清理超期数据。但事实上,Memcached不会删除任何已缓存数据,只是在其过期之后不再为客户所见;而且,Memcached也不会真正按期限清理缓存,而仅是当get命令到达时检查其时长。
Memcached的协议简介:Memcached的客户端通过TCP连接与服务器通信(UDP协议的接口也可以使用,详细说明请参考”UDP 协议”部分)。一个给定的运行中的Memcached服务器在某个(可配置的)端口上监听连接;客户端连接该端口,发送命令给服务器,读取反馈,最后关闭连接。没有必要发送一个专门的命令去结束会话。客户端可以在不需要该连接的时候就关闭它。注意:我们鼓励客户端缓存它们与服务器的连接,而不是每次要存储或读取数据的时候再次重新建立与服务器的连接。Memcached同时打开很多连接不会对性能造成到大的影响,这是因为Memcached在设计之处,就被设计成即使打开了很多连接(数百或者需要时上千个连接)也可以高效的运行。缓存连接可以节省与服务器建立TCP连接的时间开销(于此相比,在服务器段为建立一个新的连接所做准备的开销可以忽略不计)。
Memcached通信协议有两种类型的数据:文本行和非结构化数据。文本行用来发送从客户端到服务器的命令以及从服务器回送的反馈信息。非结构化的数据用在客户端希望存储或者读取数据时。服务器会以字符流的形式严格准确的返回相应数据在存储时存储的数据。服务器不关注字节序,它也不知道字节序的存在。Memcahced对非结构化数据中的字符没有任何限制,可以是任意的字符,读取数据时,客户端可以在前次返回的文本行中确切的知道接下来的数据块的长度。
文本行通常以“"r"n”结束。非结构化数据通常也是以“"r"n”结束,尽管"r、"n或者其他任何8位字符可以出现在数据块中。所以当客户端从服务器读取数据时,必须使用前面提供的数据块的长度,来确定数据流的结束,二不是依据跟随在字符流尾部的“"r"n”来确定数据流的结束,尽管实际上数据流格式如此。关键字 Keys:Memcached使用关键字来区分存储不同的数据。关键字是一个字符串,可以唯一标识一条数据。当前关键字的长度限制是250个字符(当然目前客户端似乎没有需求用这么长的关键字);关键字一定不能包含控制字符和空格。
Memcached提供了为数不多的几个命令来完成与服务器端的交互,这些命令基于Memcached的协议实现。
存储类命令:set, add, replace, append, prepend获取数据类命令:get, delete, incr/decr统计类命令:stats, stats items, stats slabs, stats sizes清理命令: flush_all所有的命令行总是以命令的名字开始,紧接着是以空格分割的参数。命令名称都是小写,并且是大小写敏感的。
Memcached依赖于libevent API: libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。Memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。 关于事件处理这里就不再详细介绍,可以参考libevent官方文档与The C10K Problem。
Memcached的内置内存存储方式: 研究Memcached这个产品,首先从它的内存模型开始:我们知道c++里分配内存有两种方式,预先分配和动态分配,显然,预先分配内存会使程序比较快,但是它的缺点是不能有效利用内存,而动态分配可以有效利用内存,但是会使程序运行效率下降,Memcached的内存分配就是基于以上原理,显然为了获得更快的速度,有时候我们不得不以空间换时间。Memcached的高性能源于两阶段哈希(two-stage hash)结构。Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。通过key,可以存储或查询任意的数据。 客户端可以把数据存储在多台Memcached上。当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后Memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)并返回给客户端。从实现的角度看,Memcached是一个非阻塞的、基于事件的服务器程序。 为了提高性能,Memcached 中保存的数据都存储在Memcached 内置的内存存储空间中。由于数据仅存在于内存中,因此重启Memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。Memcached 本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。Memcache使用了Slab Allocator的内存分配机制: 按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocator 的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free 来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached 进程本身还慢。Slab Allocator 就是为解决该问题而诞生的,Slab Allocation 的原理是按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把尺寸相同的块分成组,以完全解决内存碎片问题。但由于分配的是特定长度的内存,因此无法有效利用分配的内存。比如将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。还有slab allocator 还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。存储结构图如下:

Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。Chunk:用于缓存记录的内存空间。Slab Class:特定大小的chunk的组。Memcached根据收到的数据的大小,选择最适合数据大小的slab。Memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
Slab中缓存记录的原理:Memcached 根据收到的数据的大小,选择最适合数据大小的slab,Memcached 中保存着slab 内空闲chunk 的列表,根据该列表选择合适的chunk,然后将数据缓存于其中

Slab Allocator 的缺点:由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100 字节的数据缓存到128 字节的chunk 中,剩余的28字节就浪费了

对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。但是,我们可以调节slab class 的大小的差别。接下来说明growth factor 选项。
使用growth factor(增长因子) 进行调优:Memcached 在启动时指定growth factor 因子(通过f 选项),就可以在某种程度上控制slab 之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。下面是启动后的verbose 输出:slab class 1: chunk size 128 perslab 8192slab class 2: chunk size 256 perslab 4096slab class 3: chunk size 512 perslab 2048slab class 4: chunk size 1024 perslab 1024slab class 5: chunk size 2048 perslab 512slab class 6: chunk size 4096 perslab 256slab class 7: chunk size 8192 perslab 128slab class 8: chunk size 16384 perslab 64slab class 9: chunk size 32768 perslab 32slab class 10: chunk size 65536 perslab 16slab class 11: chunk size 131072 perslab 8slab class 12: chunk size 262144 perslab 4slab class 13: chunk size 524288 perslab 2可见,从128 字节的组开始,组的大小依次增大为原来的2 倍。这样设置的问题是,slab 之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,修改了growth factor 这个选项来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10 组):slab class 1: chunk size 88 perslab 11915slab class 2: chunk size 112 perslab 9362slab class 3: chunk size 144 perslab 7281slab class 4: chunk size 184 perslab 5698slab class 5: chunk size 232 perslab 4519slab class 6: chunk size 296 perslab 3542slab class 7: chunk size 376 perslab 2788slab class 8: chunk size 472 perslab 2221slab class 9: chunk size 592 perslab 1771slab class 10: chunk size 744 perslab 1409可见,组间差距比因子为2 时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。将Memcached 引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
Memcached的过期时间实现方式:采用Lazy Expiration + LRU的方式
Lazy Expiration:Memcached 内部不会监视记录是否过期,而是在get 时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,Memcached不会在过期监视上耗费CPU 时间。LRU :Memcached 会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当Memcached 的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。从缓存的实用角度来看,该模型十分理想。不过,有些情况下LRU 机制反倒会造成麻烦。Memcached 启动时通过“M”参数可以禁止LRU。
Memcached的分布式算法(不互相通信的分布式): Memcached 虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。Memcached 的分布式,则是完全由客户端应用程序实现的。这种分布式是Memcached 的最大特点。

Memcached的分布式是怎么实现的?下面假设memcached 服务器有node1~node3 三台,应用程序要保存键名为"luochen","zhangsan"的数据。首先向Memcached服务器 中添加"luochen",将"luochen"传给客户端应用程序后,客户端实现的算法就会根据“键”来决定保存数据的Memcached 服务器。服务器选定后,即命令它保存"luochen"及其值同样,"zhangsan"都是先选择服务器再接下来保存数据。获取时也要先获取"luochen"的“键”传递给应用程序。应用程序通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get 命令。只要数据没有因为某些原因被删除,就能获得保存的值。这样,将不同的键保存到不同的服务器上,就实现了Memcached 的分布式。Memcached 服务器增多后,键就会分散,即使一台Memcached 服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。第一种分布式算法(用键除以Memcached服务器的总数取余):就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。第一种算法的缺点:余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中,大量缓存会失效。第二中分布式(一致性哈希)算法:
知识补充:哈希算法,即散列函数。将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法。(常见的有MD5,SHA-1)。Consistent Hashing 的简单说明:Consistent Hashing 如下所示:首先求出Memcached 服务器(节点)的哈希值,并将其配置到0~232 的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232 仍然找不到服务器,就会保存到第一台Memcached 服务器上。

从上图的状态中添加一台Memcached 服务器。余数分布式算法由于保存键的服务器会发生巨大变化,而影响缓存的命中率,但Consistent Hashing中,只有在continuum 上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响

Consistent Hashing(添加服务器):因此,Consistent Hashing 最大限度地抑制了键的重新分布。而且,有的Consistent Hashing 的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200 个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。通过上文中介绍的使用Consistent Hashing 算法的Memcached 客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下: (1 - n/(n+m)) * 100PS : 注意事项1. Memcached已经分配的内存不会再主动清理。
2. Memcached分配给某个slab的内存页不能再分配给其他slab。
3. flush_all不能重置Memcached分配内存页的格局,只是给所有的item置为过期。
4. Memcached最大存储的item(key+value)大小限制为1M,这由page大小1M限制
5.由于Memcached的分布式是客户端程序通过hash算法得到的key取模来实现,不同的语言可能会采用不同的hash算法,同样的客户端程序也有可能使用相异的方法,因此在多语言、多模块共用同一组Memcached服务时,一定要注意在客户端选择相同的hash算法
6.启动Memcached时可以通过-M参数禁止LRU替换,在内存用尽时add和set会返回失败
7.Memcached启动时指定的是数据存储量,没有包括本身占用的内存、以及为了保存数据而设置的管理空间。因此它占用的内存量会多于启动时指定的内存分配量,这点需要注意。
8.Memcached存储的时候对key的长度有限制,php和C的最大长度都是250
Memcached的安装:1.安装libevent(libevent-2.0.22-stable.tar.gz)
Memcached依赖于libevent API,因此要事先安装之,项目主页:http://libevent.org/,读者可自行选择需要的版本下载。 #tar xf libevent-2.0.22-stable.tar.gz # cd libevent-2.0.22 # ./configure --prefix=/usr/local/libevent # make && make install# echo "/usr/local/libevent/lib" > /etc/ld.so.conf.d/libevent.conf # ldconfig 2.安装Memcached(memcached-1.4.24.tar.gz )# tar xf memcached-1.4.24.tar.gz# cd memcached-1.4.24 # ./configure --prefix=/usr/local/memcached --with-libevent=/usr/local/libevent # make && make installPS:Memcached 默认不支持认证功能,需要安装sasl #yum -y install cyrus-sasl-devel在configure是加上 --enable-sasl
#rpm -qi libevent###查找libevent的安装位置3.提供Memcached SysV的服务脚本 #vim /etc/rc.d/init.d/memcached
#vim /etc/sysconfig/memcachedPORT="11211"USER="nobody"MAXCONN="1024"CACHESIZE="64"OPTIONS=""在原来的脚本文件里的参数后面添加 一行[ -f /etc/sysconfig/memcached ]&&./etc/sysconfig/memcached10.使用telnet命令测试Memcached的使用 #yum -y install telnetMemcached提供一组基本命令用于基于命令行调用其服务或查看服务器状态等。 # telnet 127.0.0.1 11211statsSTAT pid 8279 ###进程ID
STAT uptime 8000 ###服务器运行秒数
STAT time 1378284623###服务器当前unix时间戳
STAT version 1.4.24 ###服务器版本
STAT libevent 2.0.22-stable###libevent版本号
STAT pointer_size 32 ###操作系统指针大小(这台服务器是32位的)
STAT rusage_user 0.000999 ###进程累计用户时间
STAT rusage_system 0.003999 ###进程累计系统时间
STAT curr_connections 10 ###当前打开连接数
STAT total_connections 11 ###曾打开的连接总数
STAT connection_structures 11 ###服务器分配的连接结构数
STAT reserved_fds 20 ###内部使用的FD数
STAT cmd_get 0###执行get命令总数
STAT cmd_set 0###执行set命令总数
STAT cmd_flush 0###执行flush命令总数
STAT cmd_touch 0 ###执行touch命令总数
STAT get_hits 0 ###get命中次数
STAT get_misses 0###get未命中次数
STAT delete_misses 0 ###delete未命中次数
STAT delete_hits 0###delete命中次数
STAT incr_misses 0 ###incr未命中次数
STAT incr_hits 0###incr命中次数
STAT decr_misses 0 ###decr未命中次数
STAT decr_hits 0###decr命中次数
STAT cas_misses 0###cas未命中次数
STAT cas_hits 0###cas命中次数
STAT cas_badval 0###使用擦拭次数
STAT touch_hits 0###touch命中次数
STAT touch_misses 0###touch未命中次数
STAT auth_cmds 0###认证处理的次数
STAT auth_errors 0 ###认证失败次数
STAT bytes_read 7###读取字节总数
STAT bytes_written 0 ###写入字节总数
STAT limit_maxbytes 134217728###现在的内存大小为128M
STAT accepting_conns 1 ###目前接受的新接数
STAT listen_disabled_num 0###失效的监听数
STAT threads 4###当前线程数
STAT conn_yields 0###连接操作主支放弃数目
STAT hash_power_level 16###hash等级
STAT hash_bytes 524288 ###当前hash表等级
STAT hash_is_expanding 0###hash表扩展大小
STAT bytes 0 ###当前存储占用的字节数
STAT curr_items 0###当前存储数据总数
STAT total_items 0 ###启动以来存储的数据总数
STAT expired_unfetched 0###已过期但未获取的对象数目
STAT evicted_unfetched 0 ###已驱逐但未获取的对象数目
STAT evictions 0###LRU释放的对象数目
STAT reclaimed 0###用已过期的数据条目来存储新数据的数目
最后介绍下Memcached的常用客户端命令:Memcached客户端命令的格式 <command name><key><flags><exptime><bytes> <data block>参数说明 command name : 操作命令名称 key :缓存使用的键值 flags : 客户端使用它存储关于键值对的额外信息 exptime : 缓存过期时间,0表示永不过期 bytes : 键值的占用内存大小 data block : 数据块
PS :
1. 什么是CAS协议
很多中文的资料都不会告诉大家CAS的全称是什么,不过一定不要把CAS当作中国科学院(China Academy of Sciences)的缩写。谷歌一下,CAS是什么?CAS是Check And Set的缩写(真是无语了,百度出来没有一点有用的资料,要看协议原文的翻墙吧)。
2. CAS协议原文
http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt
3. CAS的基本原理
基本原理非常简单,一言以蔽之,就是“版本号”。每个存储的数据对象,多有一个版本号。我们可以从下面的例子来理解:
如果不采用CAS,则有如下的情景:
第一步,A取出数据对象X;
第二步,B取出数据对象X;
第三步,B修改数据对象X,并将其放入缓存;
第四步,A修改数据对象X,并将其放入缓存。
我们可以发现,第四步中会产生数据写入冲突。
如果采用CAS协议,则是如下的情景。
第一步,A取出数据对象X,并获取到CAS-ID1;
第二步,B取出数据对象X,并获取到CAS-ID2;
第三步,B修改数据对象X,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“一致”,就将修改后的带有CAS-ID2的X写入到缓存。
第四步,A修改数据对象Y,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“不一致”,则拒绝写入,返回存储失败。
就这样CAS协议就用了“版本号”的思想,解决了冲突问题。
本文出自 “珞辰的博客” 博客,请务必保留此出处http://luochen2015.blog.51cto.com/9772274/1700191
Memcached是一款开发工具,它既不是一个代码加速器,也不是数据库中间件。其设计哲学思想主要反映在如下方面: 1. 简单key/value存储:服务器不关心数据本身的意义及结构,只要是可序列化数据即可。存储项由“键、过期时间、可选的标志及数据”四个部分组成。 2. 功能的实现一半依赖于客户端,一半基于服务器端:客户负责发送存储项至服务器端、从服务端获取数据以及无法连接至服务器时采用相应的动作;服务端负责接收、存储数据,并负责数据项的超时过期。 3. 各服务器间彼此无视,不在服务器间进行数据同步。 4. O(1)的执行效率。 5. 清理超期数据,默认情况下,Memcached是一个LRU缓存,同时,它按事先预订的时长清理超期数据。但事实上,Memcached不会删除任何已缓存数据,只是在其过期之后不再为客户所见;而且,Memcached也不会真正按期限清理缓存,而仅是当get命令到达时检查其时长。
Memcached的协议简介:Memcached的客户端通过TCP连接与服务器通信(UDP协议的接口也可以使用,详细说明请参考”UDP 协议”部分)。一个给定的运行中的Memcached服务器在某个(可配置的)端口上监听连接;客户端连接该端口,发送命令给服务器,读取反馈,最后关闭连接。没有必要发送一个专门的命令去结束会话。客户端可以在不需要该连接的时候就关闭它。注意:我们鼓励客户端缓存它们与服务器的连接,而不是每次要存储或读取数据的时候再次重新建立与服务器的连接。Memcached同时打开很多连接不会对性能造成到大的影响,这是因为Memcached在设计之处,就被设计成即使打开了很多连接(数百或者需要时上千个连接)也可以高效的运行。缓存连接可以节省与服务器建立TCP连接的时间开销(于此相比,在服务器段为建立一个新的连接所做准备的开销可以忽略不计)。
Memcached通信协议有两种类型的数据:文本行和非结构化数据。文本行用来发送从客户端到服务器的命令以及从服务器回送的反馈信息。非结构化的数据用在客户端希望存储或者读取数据时。服务器会以字符流的形式严格准确的返回相应数据在存储时存储的数据。服务器不关注字节序,它也不知道字节序的存在。Memcahced对非结构化数据中的字符没有任何限制,可以是任意的字符,读取数据时,客户端可以在前次返回的文本行中确切的知道接下来的数据块的长度。
文本行通常以“"r"n”结束。非结构化数据通常也是以“"r"n”结束,尽管"r、"n或者其他任何8位字符可以出现在数据块中。所以当客户端从服务器读取数据时,必须使用前面提供的数据块的长度,来确定数据流的结束,二不是依据跟随在字符流尾部的“"r"n”来确定数据流的结束,尽管实际上数据流格式如此。关键字 Keys:Memcached使用关键字来区分存储不同的数据。关键字是一个字符串,可以唯一标识一条数据。当前关键字的长度限制是250个字符(当然目前客户端似乎没有需求用这么长的关键字);关键字一定不能包含控制字符和空格。
Memcached提供了为数不多的几个命令来完成与服务器端的交互,这些命令基于Memcached的协议实现。
存储类命令:set, add, replace, append, prepend获取数据类命令:get, delete, incr/decr统计类命令:stats, stats items, stats slabs, stats sizes清理命令: flush_all所有的命令行总是以命令的名字开始,紧接着是以空格分割的参数。命令名称都是小写,并且是大小写敏感的。
Memcached依赖于libevent API: libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。Memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。 关于事件处理这里就不再详细介绍,可以参考libevent官方文档与The C10K Problem。
Memcached的内置内存存储方式: 研究Memcached这个产品,首先从它的内存模型开始:我们知道c++里分配内存有两种方式,预先分配和动态分配,显然,预先分配内存会使程序比较快,但是它的缺点是不能有效利用内存,而动态分配可以有效利用内存,但是会使程序运行效率下降,Memcached的内存分配就是基于以上原理,显然为了获得更快的速度,有时候我们不得不以空间换时间。Memcached的高性能源于两阶段哈希(two-stage hash)结构。Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。通过key,可以存储或查询任意的数据。 客户端可以把数据存储在多台Memcached上。当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后Memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)并返回给客户端。从实现的角度看,Memcached是一个非阻塞的、基于事件的服务器程序。 为了提高性能,Memcached 中保存的数据都存储在Memcached 内置的内存存储空间中。由于数据仅存在于内存中,因此重启Memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。Memcached 本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。Memcache使用了Slab Allocator的内存分配机制: 按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocator 的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free 来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached 进程本身还慢。Slab Allocator 就是为解决该问题而诞生的,Slab Allocation 的原理是按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把尺寸相同的块分成组,以完全解决内存碎片问题。但由于分配的是特定长度的内存,因此无法有效利用分配的内存。比如将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。还有slab allocator 还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。存储结构图如下:
Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。Chunk:用于缓存记录的内存空间。Slab Class:特定大小的chunk的组。Memcached根据收到的数据的大小,选择最适合数据大小的slab。Memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
Slab中缓存记录的原理:Memcached 根据收到的数据的大小,选择最适合数据大小的slab,Memcached 中保存着slab 内空闲chunk 的列表,根据该列表选择合适的chunk,然后将数据缓存于其中
Slab Allocator 的缺点:由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100 字节的数据缓存到128 字节的chunk 中,剩余的28字节就浪费了
对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。但是,我们可以调节slab class 的大小的差别。接下来说明growth factor 选项。
使用growth factor(增长因子) 进行调优:Memcached 在启动时指定growth factor 因子(通过f 选项),就可以在某种程度上控制slab 之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。下面是启动后的verbose 输出:slab class 1: chunk size 128 perslab 8192slab class 2: chunk size 256 perslab 4096slab class 3: chunk size 512 perslab 2048slab class 4: chunk size 1024 perslab 1024slab class 5: chunk size 2048 perslab 512slab class 6: chunk size 4096 perslab 256slab class 7: chunk size 8192 perslab 128slab class 8: chunk size 16384 perslab 64slab class 9: chunk size 32768 perslab 32slab class 10: chunk size 65536 perslab 16slab class 11: chunk size 131072 perslab 8slab class 12: chunk size 262144 perslab 4slab class 13: chunk size 524288 perslab 2可见,从128 字节的组开始,组的大小依次增大为原来的2 倍。这样设置的问题是,slab 之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,修改了growth factor 这个选项来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10 组):slab class 1: chunk size 88 perslab 11915slab class 2: chunk size 112 perslab 9362slab class 3: chunk size 144 perslab 7281slab class 4: chunk size 184 perslab 5698slab class 5: chunk size 232 perslab 4519slab class 6: chunk size 296 perslab 3542slab class 7: chunk size 376 perslab 2788slab class 8: chunk size 472 perslab 2221slab class 9: chunk size 592 perslab 1771slab class 10: chunk size 744 perslab 1409可见,组间差距比因子为2 时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。将Memcached 引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
Memcached的过期时间实现方式:采用Lazy Expiration + LRU的方式
Lazy Expiration:Memcached 内部不会监视记录是否过期,而是在get 时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,Memcached不会在过期监视上耗费CPU 时间。LRU :Memcached 会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当Memcached 的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。从缓存的实用角度来看,该模型十分理想。不过,有些情况下LRU 机制反倒会造成麻烦。Memcached 启动时通过“M”参数可以禁止LRU。
Memcached的分布式算法(不互相通信的分布式): Memcached 虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。Memcached 的分布式,则是完全由客户端应用程序实现的。这种分布式是Memcached 的最大特点。
Memcached的分布式是怎么实现的?下面假设memcached 服务器有node1~node3 三台,应用程序要保存键名为"luochen","zhangsan"的数据。首先向Memcached服务器 中添加"luochen",将"luochen"传给客户端应用程序后,客户端实现的算法就会根据“键”来决定保存数据的Memcached 服务器。服务器选定后,即命令它保存"luochen"及其值同样,"zhangsan"都是先选择服务器再接下来保存数据。获取时也要先获取"luochen"的“键”传递给应用程序。应用程序通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get 命令。只要数据没有因为某些原因被删除,就能获得保存的值。这样,将不同的键保存到不同的服务器上,就实现了Memcached 的分布式。Memcached 服务器增多后,键就会分散,即使一台Memcached 服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。第一种分布式算法(用键除以Memcached服务器的总数取余):就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。第一种算法的缺点:余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中,大量缓存会失效。第二中分布式(一致性哈希)算法:
知识补充:哈希算法,即散列函数。将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法。(常见的有MD5,SHA-1)。Consistent Hashing 的简单说明:Consistent Hashing 如下所示:首先求出Memcached 服务器(节点)的哈希值,并将其配置到0~232 的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232 仍然找不到服务器,就会保存到第一台Memcached 服务器上。
从上图的状态中添加一台Memcached 服务器。余数分布式算法由于保存键的服务器会发生巨大变化,而影响缓存的命中率,但Consistent Hashing中,只有在continuum 上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响
Consistent Hashing(添加服务器):因此,Consistent Hashing 最大限度地抑制了键的重新分布。而且,有的Consistent Hashing 的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200 个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。通过上文中介绍的使用Consistent Hashing 算法的Memcached 客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下: (1 - n/(n+m)) * 100PS : 注意事项1. Memcached已经分配的内存不会再主动清理。
2. Memcached分配给某个slab的内存页不能再分配给其他slab。
3. flush_all不能重置Memcached分配内存页的格局,只是给所有的item置为过期。
4. Memcached最大存储的item(key+value)大小限制为1M,这由page大小1M限制
5.由于Memcached的分布式是客户端程序通过hash算法得到的key取模来实现,不同的语言可能会采用不同的hash算法,同样的客户端程序也有可能使用相异的方法,因此在多语言、多模块共用同一组Memcached服务时,一定要注意在客户端选择相同的hash算法
6.启动Memcached时可以通过-M参数禁止LRU替换,在内存用尽时add和set会返回失败
7.Memcached启动时指定的是数据存储量,没有包括本身占用的内存、以及为了保存数据而设置的管理空间。因此它占用的内存量会多于启动时指定的内存分配量,这点需要注意。
8.Memcached存储的时候对key的长度有限制,php和C的最大长度都是250
Memcached的安装:1.安装libevent(libevent-2.0.22-stable.tar.gz)
Memcached依赖于libevent API,因此要事先安装之,项目主页:http://libevent.org/,读者可自行选择需要的版本下载。 #tar xf libevent-2.0.22-stable.tar.gz # cd libevent-2.0.22 # ./configure --prefix=/usr/local/libevent # make && make install# echo "/usr/local/libevent/lib" > /etc/ld.so.conf.d/libevent.conf # ldconfig 2.安装Memcached(memcached-1.4.24.tar.gz )# tar xf memcached-1.4.24.tar.gz# cd memcached-1.4.24 # ./configure --prefix=/usr/local/memcached --with-libevent=/usr/local/libevent # make && make installPS:Memcached 默认不支持认证功能,需要安装sasl #yum -y install cyrus-sasl-devel在configure是加上 --enable-sasl
#rpm -qi libevent###查找libevent的安装位置3.提供Memcached SysV的服务脚本 #vim /etc/rc.d/init.d/memcached
#!/bin/bash
#
# Init file for memcached
#
# chkconfig: - 86 14
# description: Distributed memory caching daemon
#
# processname: memcached
# config: /etc/sysconfig/memcached
. /etc/rc.d/init.d/functions
## Default variables
PORT="11211"
USER="nobody"
MAXCONN="1024"
CACHESIZE="64"
OPTIONS=""
RETVAL=0
prog="/usr/local/memcached/bin/memcached"
desc="Distributed memory caching"
lockfile="/var/lock/subsys/memcached"
start() {
echo -n $"Starting $desc (memcached): "
daemon $prog -d -p $PORT -u $USER -c $MAXCONN -m $CACHESIZE $OPTIONS
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && touch $lockfile
return $RETVAL
}
stop() {
echo -n $"Shutting down $desc (memcached): "
killproc $prog
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && rm -f $lockfile
return $RETVAL
}
restart() {
stop
start
}
reload() {
echo -n $"Reloading $desc ($prog): "
killproc $prog -HUP
RETVAL=$?
echo
return $RETVAL
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
condrestart)
[ -e $lockfile ] && restart
RETVAL=$?
;;
reload)
reload
;;
status)
status $prog
RETVAL=$?
;;
*)
echo $"Usage: $0 {start|stop|restart|condrestart|status}"
RETVAL=1
esac
exit $RETVAL4.添加服务至服务管理列表,并让其开机自动启动 # chmod +x /etc/rc.d/init.d/memcached # chkconfig --add memcached #chkconfig memcached on # service memcached start5.修改PATH环境变量,让系统可以直接使用memcached的相关命令# vim /etc/profile.d/memcached.shexport PATH=$PATH:/usr/local/memcached/bin#source /etc/profile6.Memcached命令的选项解释 -pTCP监听端口 (default: 11211) -UUDP 监听端口 (default: 11211, 0 is off) -s UNIX socket监听路径,不支持网络 -a UNIX socket访问掩码, 八进制 (default: 0700) -l监听的服务器IP地址 (default: all addresses) -d 以服务模式运行 -r最大限度利用核心文件限制 -u 以指定的用户身份运行memcached进程 -m用于缓存数据的最大内存空间,单位为MB,默认为64MB -M当内存空间不够使用时返回错误信息,而不是按LRU算法利用空间 -c最大支持的并发连接数,默认为1024 -k锁定所有分页内存 -v输出警告和错误信息 -vv同时打印客户端请求和返回信息 -vvv打印内部状态转换信息 -i打印memcached 和 libevent 版本信息 -P 设置保存pid文件, only used with -d option -f设定Slab Allocator定义预先分配内存空间大小固定的块时使用的增长因子 -n指定最小的slab chunk大小;单位是字节 -L 如何有效,尝试使用大内存页。增加内存页大小可以减少失误的TLB数量,提高性能。 -D指定key和IDs的分隔符 default is “:” (colon). 如果指定此选项,统计信息收集自动开启 -t 用于处理入站请求的最大线程数,仅在memcached编译时开启了支持线程才有效 -R每个事件的最大请求数 (default: 20) -C禁止使用 CAS -b设置积压队列数限制 (default: 1024)、 -B绑定协议 – one of ascii, binary, or auto (default) -I 分配给每个slab页(default: 1mb, min: 1k, max: 128m) -S: 启用sasl进行用户认证 -o配置额外选项7.启动Memcached(手动指定各种参数方式)# memcached -d -m 500 -u root -l 192.168.x.x -c 200 -P /tmp/memcached.pid -vvv PS : 默认使用11211端口,root用户,最大使用500M内存,200个并发连接,输出详细信息,以守护进程方式运行。从输出信息可看出Memcached分配内存的过程。8.查看端口是否在被监听 #netstat -tnulp9.刚刚上面是在脚本中直接写死参数配置,也可以将参数写到配置文件里(这样后期修改容易)#vim /etc/sysconfig/memcachedPORT="11211"USER="nobody"MAXCONN="1024"CACHESIZE="64"OPTIONS=""在原来的脚本文件里的参数后面添加 一行[ -f /etc/sysconfig/memcached ]&&./etc/sysconfig/memcached10.使用telnet命令测试Memcached的使用 #yum -y install telnetMemcached提供一组基本命令用于基于命令行调用其服务或查看服务器状态等。 # telnet 127.0.0.1 11211statsSTAT pid 8279 ###进程ID
STAT uptime 8000 ###服务器运行秒数
STAT time 1378284623###服务器当前unix时间戳
STAT version 1.4.24 ###服务器版本
STAT libevent 2.0.22-stable###libevent版本号
STAT pointer_size 32 ###操作系统指针大小(这台服务器是32位的)
STAT rusage_user 0.000999 ###进程累计用户时间
STAT rusage_system 0.003999 ###进程累计系统时间
STAT curr_connections 10 ###当前打开连接数
STAT total_connections 11 ###曾打开的连接总数
STAT connection_structures 11 ###服务器分配的连接结构数
STAT reserved_fds 20 ###内部使用的FD数
STAT cmd_get 0###执行get命令总数
STAT cmd_set 0###执行set命令总数
STAT cmd_flush 0###执行flush命令总数
STAT cmd_touch 0 ###执行touch命令总数
STAT get_hits 0 ###get命中次数
STAT get_misses 0###get未命中次数
STAT delete_misses 0 ###delete未命中次数
STAT delete_hits 0###delete命中次数
STAT incr_misses 0 ###incr未命中次数
STAT incr_hits 0###incr命中次数
STAT decr_misses 0 ###decr未命中次数
STAT decr_hits 0###decr命中次数
STAT cas_misses 0###cas未命中次数
STAT cas_hits 0###cas命中次数
STAT cas_badval 0###使用擦拭次数
STAT touch_hits 0###touch命中次数
STAT touch_misses 0###touch未命中次数
STAT auth_cmds 0###认证处理的次数
STAT auth_errors 0 ###认证失败次数
STAT bytes_read 7###读取字节总数
STAT bytes_written 0 ###写入字节总数
STAT limit_maxbytes 134217728###现在的内存大小为128M
STAT accepting_conns 1 ###目前接受的新接数
STAT listen_disabled_num 0###失效的监听数
STAT threads 4###当前线程数
STAT conn_yields 0###连接操作主支放弃数目
STAT hash_power_level 16###hash等级
STAT hash_bytes 524288 ###当前hash表等级
STAT hash_is_expanding 0###hash表扩展大小
STAT bytes 0 ###当前存储占用的字节数
STAT curr_items 0###当前存储数据总数
STAT total_items 0 ###启动以来存储的数据总数
STAT expired_unfetched 0###已过期但未获取的对象数目
STAT evicted_unfetched 0 ###已驱逐但未获取的对象数目
STAT evictions 0###LRU释放的对象数目
STAT reclaimed 0###用已过期的数据条目来存储新数据的数目
最后介绍下Memcached的常用客户端命令:Memcached客户端命令的格式 <command name><key><flags><exptime><bytes> <data block>参数说明 command name : 操作命令名称 key :缓存使用的键值 flags : 客户端使用它存储关于键值对的额外信息 exptime : 缓存过期时间,0表示永不过期 bytes : 键值的占用内存大小 data block : 数据块
| Command Name | Description | Example |
| get | Reads a value | get mykey |
| set | Set a key unconditionally | set mykey 0 60 5 |
| add | Add a new key | add luochen 0 60 5 |
| replace | Overwrite existing key | replace key 0 60 5 |
| append | Append data to existing key | append key 0 60 15 |
| prepend | Prepend data to existing key | prepend key 0 60 15 |
| incr | Increments numerical key value by given numbermykey 存放的应当是数字 才能增加和减少 | incr mykey 1 |
| decr | Decrements numerical key value by given numbermykey 存放的应当是数字 才能增加和减少 | decr mykey 1 |
| flush_all | Invalidate specific items immediatelyInvalidate all items in n seconds | flush_allflush_all 900 |
| stats | Prints general statisticsPrints memory statisticsPrints memory statisticsPrint higher level allocation statistics Resets statistics | statsstats slabsstats mallocstats itemsstats detailstats sizesstats reset |
| version | Prints server version | version |
| verbosity | Increases log level | verbosity |
| quit | Terminate telnet session | quit |
1. 什么是CAS协议
很多中文的资料都不会告诉大家CAS的全称是什么,不过一定不要把CAS当作中国科学院(China Academy of Sciences)的缩写。谷歌一下,CAS是什么?CAS是Check And Set的缩写(真是无语了,百度出来没有一点有用的资料,要看协议原文的翻墙吧)。
2. CAS协议原文
http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt
3. CAS的基本原理
基本原理非常简单,一言以蔽之,就是“版本号”。每个存储的数据对象,多有一个版本号。我们可以从下面的例子来理解:
如果不采用CAS,则有如下的情景:
第一步,A取出数据对象X;
第二步,B取出数据对象X;
第三步,B修改数据对象X,并将其放入缓存;
第四步,A修改数据对象X,并将其放入缓存。
我们可以发现,第四步中会产生数据写入冲突。
如果采用CAS协议,则是如下的情景。
第一步,A取出数据对象X,并获取到CAS-ID1;
第二步,B取出数据对象X,并获取到CAS-ID2;
第三步,B修改数据对象X,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“一致”,就将修改后的带有CAS-ID2的X写入到缓存。
第四步,A修改数据对象Y,在写入缓存前,检查CAS-ID与缓存空间中该数据的CAS-ID是否一致。结果是“不一致”,则拒绝写入,返回存储失败。
就这样CAS协议就用了“版本号”的思想,解决了冲突问题。
本文出自 “珞辰的博客” 博客,请务必保留此出处http://luochen2015.blog.51cto.com/9772274/1700191

相关文章推荐
- C# 操作Memcached
- spring-xmemcached 集成
- Memcached 笔记与总结(4)memcache 扩展的使用
- 02.XMemcached的使用
- memcached 介绍
- Memcached 安装
- wamp环境下安装memcached最好的详解教程^.^:(只需要3个步骤 )
- xampp3.2.1安装memcached扩展
- 01.安装Memcached
- Memcached完全解剖–1. memcached基金会
- php中使用memcache扩展的性能问题
- Ehcache与Memcached比较
- Redis与Memcached比较
- Memcached java 简单实例
- memcached之数据优化(转)
- memcached之java客户端:spymemcached与spring整合
- memcache原理
- Nginx+Tomcat+Memcached集群实践
- C#调用Couchbase中的Memcached缓存
- memcache学习使用