特征提取,特征选择
2015-10-04 16:32
369 查看
参考文献
特征提取是机器学习的准备工作。
一、特征大体上分几种呢
有人分:high features 和low features. high features 指比较泛的特征;low features 指相对具体的特征。
有人分:具体特征,原始特征(不加工raw),抽象特征。
总体上,Low Level 比较有针对性,单个特征覆盖面小(含有这个特征的数据不多),特征数量(维度)很大。High Level比较泛化,单个特征覆盖面大(含有这个特征的数据很多),特征数量(维度)不大。长尾样本的预测值主要受High Level特征影响。高频样本的预测值主要受Low Level特征影响。
非线性模型的特征
1)可以主要使用High Level特征,因为计算复杂度大,所以特征维度不宜太高;
2)通过High Level非线性映射可以比较好地拟合目标。
线性模型的特征
1)特征体系要尽可能全面,High Level和Low Level都要有;
2)可以将High Level转换Low Level,以提升模型的拟合能力。
Rescaling:
归一化到[0,1] 或 [-1,1],用类似方式:
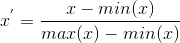
Standardization:
设
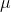
为x分布的均值,
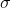
为x分布的标准差;
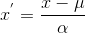
Scaling to unit length:
归一化到单位长度向量
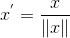
Filter:
假设特征子集对模型预估的影响互相独立,选择一个特征子集,分析该子集和数据Label的关系,如果存在某种正相关,则认为该特征子集有效。衡量特征子集和数据Label关系的算法有很多,如Chi-square,Information Gain。
Wrapper:
选择一个特征子集加入原有特征集合,用模型进行训练,比较子集加入前后的效果,如果效果变好,则认为该特征子集有效,否则认为无效。
Embedded:
将特征选择和模型训练结合起来,如在损失函数中加入L1 Norm ,L2 Norm。
特征提取是机器学习的准备工作。
一、特征大体上分几种呢
有人分:high features 和low features. high features 指比较泛的特征;low features 指相对具体的特征。
有人分:具体特征,原始特征(不加工raw),抽象特征。
总体上,Low Level 比较有针对性,单个特征覆盖面小(含有这个特征的数据不多),特征数量(维度)很大。High Level比较泛化,单个特征覆盖面大(含有这个特征的数据很多),特征数量(维度)不大。长尾样本的预测值主要受High Level特征影响。高频样本的预测值主要受Low Level特征影响。
非线性模型的特征
1)可以主要使用High Level特征,因为计算复杂度大,所以特征维度不宜太高;
2)通过High Level非线性映射可以比较好地拟合目标。
线性模型的特征
1)特征体系要尽可能全面,High Level和Low Level都要有;
2)可以将High Level转换Low Level,以提升模型的拟合能力。
二、特征归一化
特征抽取后,如果不同特征的取值范围相差很大,最好对特征进行归一化,以取得更好的效果,常见的归一化方式如下:Rescaling:
归一化到[0,1] 或 [-1,1],用类似方式:
Standardization:
设
为x分布的均值,
为x分布的标准差;
Scaling to unit length:
归一化到单位长度向量
三、特征选择
特征抽取和归一化之后,如果发现特征太多,导致模型无法训练,或很容易导致模型过拟合,则需要对特征进行选择,挑选有价值的特征。Filter:
假设特征子集对模型预估的影响互相独立,选择一个特征子集,分析该子集和数据Label的关系,如果存在某种正相关,则认为该特征子集有效。衡量特征子集和数据Label关系的算法有很多,如Chi-square,Information Gain。
Wrapper:
选择一个特征子集加入原有特征集合,用模型进行训练,比较子集加入前后的效果,如果效果变好,则认为该特征子集有效,否则认为无效。
Embedded:
将特征选择和模型训练结合起来,如在损失函数中加入L1 Norm ,L2 Norm。

相关文章推荐
- 通过身边小事解释机器学习是什么?
- LeetCode -- Unique Paths
- 第一天研究了salt stack 完整笔记
- jQuery UI基础----5jQuery UI Interactions-selectable(可选择的
- C# 操作Memcached
- cuda vs2010 关键字字体颜色设置
- 变量初始化规则以及声明和定义
- LeetCode -- Summary Ranges
- Reverse bits of a given 32 bits unsigned integer
- LeetCode -- Maximal Square
- jQuery UI基础----4jQuery UI Interactions-resizeable( 可变尺寸的
- LeetCode -- Max Points on a Line
- LCD1602 显示数字,字符,自定义字符,字符串,光标
- jQuery UI基础----3jQuery UI Interactions-droppable(适于投下的
- codeforces 22B B. Bargaining Table(dp)
- ScrollView中放ListView,ListView中放GridView冲突问题
- hdu 5496 Beauty of Sequence
- leetcode题目 寻找和为SUM的两数(O(nlogn)和O(n)解法)
- GDB实用的调试工具
- LeetCode -- Majority Element