03crawler02 爬取贴吧排名, 制作图片集
2015-10-02 20:48
579 查看
接下来一个应用是在贴吧看到的, 一位吧友发了一个关于前三百名的吧友的排名的头像,不过 在前几天, 没事的时候, 突然看见这个帖子漂了上来, 然后 思考这个问题的思路
后来 使用我的”爬虫框架”, 实现了这个功能
程序输入 : 贴吧的名称, 开始的排名, 获取多少个排名
keyWord startIdx offset
主要有四个脚本 :
1. 抓取排名页面中 “keyWord吧”, 中吧友的人数, 然后根据每一页显示的人数, 计算总共的页数, 然后根据startIdx, offset 计算需要抓取的页数, 拼接对应排名页面的url传递给下一个脚本
2. 抓取给定的url的页面, 中所有的人的数据, 排名, 吧友名字, 吧友的主页, 吧友的经验值, 其中最重要的是url, 将当前页面所有的吧友的主页url传入下一个脚本
3. 抓取吧友主页的用户头像的连接, 并下载该图片
4. 将收集的吧友图片展示出来, 主要是使用了swing的JPanel
排行榜 :
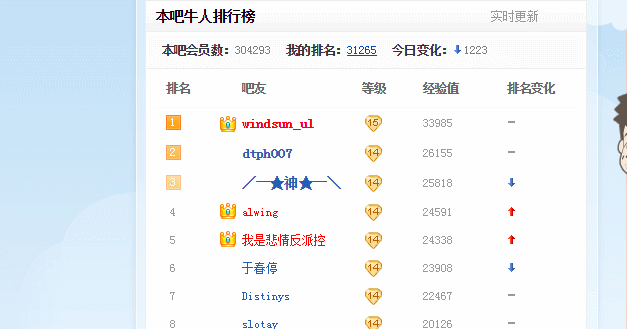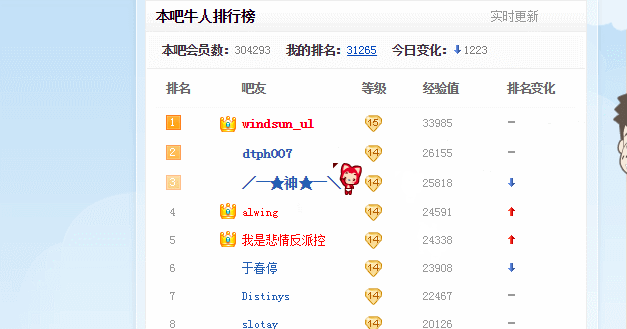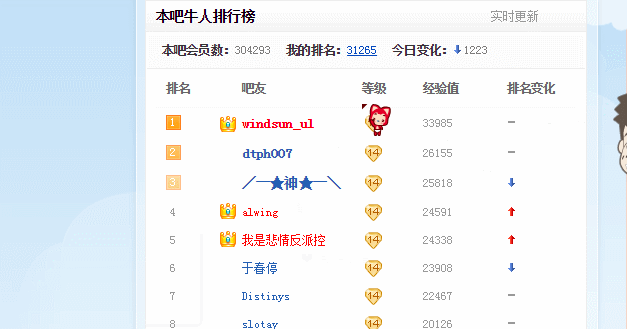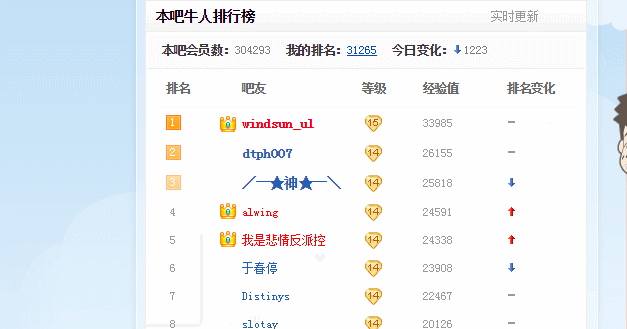
结果效果 :


代码 :
脚本1
脚本2
脚本3
脚本4
注 : 因为作者的水平有限,必然可能出现一些bug, 所以请大家指出!
后来 使用我的”爬虫框架”, 实现了这个功能
程序输入 : 贴吧的名称, 开始的排名, 获取多少个排名
keyWord startIdx offset
主要有四个脚本 :
1. 抓取排名页面中 “keyWord吧”, 中吧友的人数, 然后根据每一页显示的人数, 计算总共的页数, 然后根据startIdx, offset 计算需要抓取的页数, 拼接对应排名页面的url传递给下一个脚本
2. 抓取给定的url的页面, 中所有的人的数据, 排名, 吧友名字, 吧友的主页, 吧友的经验值, 其中最重要的是url, 将当前页面所有的吧友的主页url传入下一个脚本
3. 抓取吧友主页的用户头像的连接, 并下载该图片
4. 将收集的吧友图片展示出来, 主要是使用了swing的JPanel
排行榜 :
结果效果 :
代码 :
脚本1
/**
* file name : Test11CrawlForDouyu01GameList.java
* created at : 9:32:38 PM Sep 5, 2015
* created by 970655147
*/
package com.hx.crawler;
public class Test13CrawlForBarRank01PageList {
// 测试站点 : http://tieba.baidu.com/f/like/furank?kw=java&pn=1 // 获取贴吧排名信息
public static void main(String []args) throws Exception {
String url = "http://tieba.baidu.com/f/like/furank?kw=%s&pn=%s";
Map<String, Object> params = new HashMap<>();
params.put(Tools.TASK, "pageList");
params.put(Tools.SITE, "tieba");
// params.put(Tools.KEY_WORD, "94%C9%E4%B5%F1");
params.put(Tools.KEY_WORD, "JAVA");
params.put(Tools.PAGE_NO, "1");
ScriptParameter singleUrlTask = Tools.newSingleTask(HtmlCrawler.newInstance(), url, params);
parse(singleUrlTask);
}
// 每一页的人数个数
// 获取的起始排名, 获取多少个元素
static int numPerPage = 20;
static int startIdx = 0;
static int offset = 100;
// parse 接口
// 1. 获取页数
// 2. 将分页信息传递给下一个脚本
public static void parse(ScriptParameter scriptParameter) throws Exception {
String nextStage = "com.hx.crawler.Test13CrawlForBarRank02RankList";
SingleUrlTask singleUrlTask = (SingleUrlTask) scriptParameter;
Crawler crawler = singleUrlTask.getCrawler();
String url = String.format(singleUrlTask.getUrl(), singleUrlTask.getParam().get(Tools.KEY_WORD), singleUrlTask.getParam().get(Tools.PAGE_NO) );
String xpath = "{\"name\":\"pageList\",\"xpath\":\"/html/body/div[@class='d_panel']\",\"values\":[{\"name\":\"memberNo\",\"xpath\":\".//span[@class='drl_info_txt_gray']\",\"attribute\":\"innertext\"}]}";
xpath = Tools.getRealXPathByXPathObj(xpath);
// ------------------------1------------------------------
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
Tools.appendCRLF(sb, "URL : " + url, true);
Tools.appendCRLF(sb, "--------------------- [" + Tools.getTaskName(singleUrlTask) + "start ...] --------------------------");
Log.log(sb.toString());
CrawlerConfig config = new CrawlerConfig();
config.setTimeout(30 * 1000);
Page page = crawler.getPage(url, config);
String html = page.getContent();
// Log.log(html);
// Tools.save(html, Tools.getTmpPath(7));
// Tools.getPreparedDoc(url, html, Tools.getTmpPath(7));
JSONArray fetchedData = Tools.getResultByXPath(html, url, xpath);
long spent = System.currentTimeMillis() - start;
Tools.appendCRLF(sb, fetchedData.toString(), true);
Tools.appendCRLF(sb, "--------------------- [crawl" + Tools.getTaskName(singleUrlTask) + "end ...] --------------------------");
Tools.appendCRLF(sb, "spent " + spent + " ms ...");
Log.log(sb.toString());
// ------------------------2------------------------------
if(! fetchedData.isEmpty()) {
JSONArray categories = fetchedData.getJSONObject(0).getJSONArray("pageList");
if(categories.size() > 0) {
int memberNo = Tools.dealPageNum(categories.getJSONObject(0).getString("memberNo") );
int pageSum = Tools.calcPageNums(memberNo, numPerPage);
int startPage = Tools.calcPageNums(startIdx, numPerPage) - 1;
if(startPage > pageSum) {
Log.log("startIdx is not good ...");
return ;
}
int endPage = Math.min(Tools.calcPageNums(startIdx+offset, numPerPage), pageSum);
JSONObject nextStageParamsTmp = JSONObject.fromObject(singleUrlTask.getParam() );
nextStageParamsTmp.put(Tools.TASK, "rankList");
for(int i=startPage; i<endPage; i++) {
JSONObject nextStageParams = JSONObject.fromObject(nextStageParamsTmp);
nextStageParams.put(Tools.URL, singleUrlTask.getUrl() );
nextStageParams.put(Tools.PAGE_NO, i+1);
// Log.log(nextStageParams);
Tools.parse(nextStage, nextStageParams.getString(Tools.URL), nextStageParams, Tools.PARSE_METHOD_NAME, Tools.IS_PARSE_METHOD_STATIC, Tools.PARSE_METHOD_PARAMTYPES);
}
}
}
}
}脚本2
/**
* file name : Test11CrawlForDouyu01GameList.java
* created at : 9:32:38 PM Sep 5, 2015
* created by 970655147
*/
package com.hx.crawler;
public class Test13CrawlForBarRank02RankList {
// 测试站点 : http://tieba.baidu.com/f/like/furank?kw=java&pn=1 // 获取贴吧排名信息
public static void main(String []args) throws Exception {
String url = "http://tieba.baidu.com/f/like/furank?kw=%s&pn=%s";
Map<String, Object> params = new HashMap<>();
params.put(Tools.TASK, "rankList");
params.put(Tools.SITE, "tieba");
params.put(Tools.KEY_WORD, "java");
params.put(Tools.PAGE_NO, "1");
ScriptParameter singleUrlTask = Tools.newSingleTask(HtmlCrawler.newInstance(), url, params);
parse(singleUrlTask);
}
// parse 接口
// 1. 获取目录
// 2. 将目录信息传递给下一个脚本
public static void parse(ScriptParameter scriptParameter) throws Exception {
String nextStage = "com.hx.crawler.Test13CrawlForBarRank03PageInfo";
SingleUrlTask singleUrlTask = (SingleUrlTask) scriptParameter;
Crawler crawler = singleUrlTask.getCrawler();
String url = String.format(singleUrlTask.getUrl(), singleUrlTask.getParam().get(Tools.KEY_WORD), singleUrlTask.getParam().get(Tools.PAGE_NO) );
String xpath = "{\"name\":\"rankList\",\"xpath\":\"/html/body//tr[@class='drl_list_item']\",\"values\":[{\"name\":\"rank\",\"xpath\":\".//td[@class='drl_item_index']\",\"attribute\":\"innertext\"},{\"name\":\"name\",\"xpath\":\".//td[@class='drl_item_name']\",\"attribute\":\"innertext\"},{\"name\":\"url\",\"xpath\":\".//td[@class='drl_item_name']//a\",\"attribute\":\"href\"},{\"name\":\"exp\",\"xpath\":\".//td[@class='drl_item_exp']\",\"attribute\":\"innertext\"}]}";
xpath = Tools.getRealXPathByXPathObj(xpath);
// ------------------------1------------------------------
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
Tools.appendCRLF(sb, "URL : " + url, true);
Tools.appendCRLF(sb, "--------------------- [" + Tools.getTaskName(singleUrlTask) + "start ...] --------------------------");
Log.log(sb.toString());
CrawlerConfig config = new CrawlerConfig();
config.setTimeout(30 * 1000);
Page page = crawler.getPage(url, config);
String html = page.getContent();
// Log.log(html);
// Tools.save(html, Tools.getTmpPath(7));
// Tools.getPreparedDoc(url, html, Tools.getTmpPath(7));
JSONArray fetchedData = Tools.getResultByXPath(html, url, xpath);
long spent = System.currentTimeMillis() - start;
Tools.appendCRLF(sb, fetchedData.toString(), true);
Tools.appendCRLF(sb, "--------------------- [crawl" + Tools.getTaskName(singleUrlTask) + "end ...] --------------------------");
Tools.appendCRLF(sb, "spent " + spent + " ms ...");
Log.log(sb.toString());
// ------------------------2------------------------------
if(! fetchedData.isEmpty()) {
JSONArray categories = fetchedData.getJSONObject(0).getJSONArray("rankList");
JSONObject nextStageParamsTmp = JSONObject.fromObject(singleUrlTask.getParam() );
nextStageParamsTmp.put(Tools.TASK, "pageInfo");
for(int i=0; i<categories.size(); i++) {
JSONObject game = categories.getJSONObject(i);
JSONObject nextStageParams = JSONObject.fromObject(nextStageParamsTmp);
nextStageParams.put(Tools.NAME, game.getString("name") );
nextStageParams.put(Tools.URL, game.getString("url") );
// Log.log(nextStageParams);
Tools.parse(nextStage, nextStageParams.getString(Tools.URL), nextStageParams, Tools.PARSE_METHOD_NAME, Tools.IS_PARSE_METHOD_STATIC, Tools.PARSE_METHOD_PARAMTYPES);
}
}
}
}脚本3
/**
* file name : Test11CrawlForDouyu01GameList.java
* created at : 9:32:38 PM Sep 5, 2015
* created by 970655147
*/
package com.hx.crawler;
public class Test13CrawlForBarRank03PageInfo {
// 测试站点 : http://tieba.baidu.com/home/main/?un=%C1%F5%B9%FA%B7%A211&fr=furank // 获取贴吧排名信息
public static void main(String []args) throws Exception {
String url = "http://tieba.baidu.com/home/main/?un=%C1%F5%B9%FA%B7%A211&fr=furank";
Map<String, Object> params = new HashMap<>();
params.put(Tools.TASK, "pageInfo");
params.put(Tools.SITE, "tieba");
params.put(Tools.KEY_WORD, "java");
params.put(Tools.PAGE_NO, "1");
ScriptParameter singleUrlTask = Tools.newSingleTask(HtmlCrawler.newInstance(), url, params);
parse(singleUrlTask);
}
// parse 接口
// 1. 获取目录
// 2. 将目录信息传递给下一个脚本
public static void parse(ScriptParameter scriptParameter) throws Exception {
SingleUrlTask singleUrlTask = (SingleUrlTask) scriptParameter;
Crawler crawler = singleUrlTask.getCrawler();
String url = singleUrlTask.getUrl();
String xpath = "{\"name\":\"infoList\",\"xpath\":\"/html/body\",\"values\":[{\"name\":\"img\",\"xpath\":\".//a[@class='userinfo_head']/img\",\"attribute\":\"src\"}]}";
xpath = Tools.getRealXPathByXPathObj(xpath);
// ------------------------1------------------------------
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
Tools.appendCRLF(sb, "URL : " + url, true);
Tools.appendCRLF(sb, "--------------------- [" + Tools.getTaskName(singleUrlTask) + "start ...] --------------------------");
Log.log(sb.toString());
CrawlerConfig config = new CrawlerConfig();
config.setTimeout(30 * 1000);
Page page = crawler.getPage(url, config);
String html = page.getContent();
// Log.log(html);
// Tools.save(html, Tools.getTmpPath(7));
// Tools.getPreparedDoc(url, html, Tools.getTmpPath(7));
JSONArray fetchedData = Tools.getResultByXPath(html, url, xpath);
long spent = System.currentTimeMillis() - start;
Tools.appendCRLF(sb, fetchedData.toString(), true);
Tools.appendCRLF(sb, "--------------------- [crawl" + Tools.getTaskName(singleUrlTask) + "end ...] --------------------------");
Tools.appendCRLF(sb, "spent " + spent + " ms ...");
Log.log(sb.toString());
// ------------------------2------------------------------
if(! fetchedData.isEmpty()) {
JSONArray categories = fetchedData.getJSONObject(0).getJSONArray("infoList");
String imgUrl = categories.getJSONObject(0).getString("img");
try {
Tools.downloadFrom(imgUrl, Tools.getNextTmpPath(Tools.PNG) );
} catch (IOException e) {
Log.err("error in page : " + imgUrl);
}
}
}
}脚本4
/**
* file name : Test11CrawlForDouyu01GameList.java
* created at : 9:32:38 PM Sep 5, 2015
* created by 970655147
*/
package com.hx.crawler;
public class Test13CrawlForBarRank04DrawIt {
// 绘制图片
public static void main(String []args) throws Exception {
Frame frame = new Frame();
for(int i=0; i<1; i++) {
frame.saveImgs(i * GRID_SUM);
}
}
// 常量
// 窗口的宽高, 行数, 列数, 显示的元素中枢
// 每一个元素的宽高, 结果的开始, 结果的索引[递增]
static int FRAMEWIDTH = 720;
static int FRAMEHEIGHT = 720;
static int ROW = 10;
static int COL = 10;
static int GRID_SUM = ROW * COL;
static int PIXES_PER_ROW = (FRAMEHEIGHT - 30) / ROW;
static int PIXES_PER_COL = (FRAMEWIDTH - 10) / COL;
static int SUM_START = 1000;
static int SUM_IDX = 0;
// 有些吧友的图片并没有110 例如 : 无名指七年 80x80
// static int IMG_HEIGHT = 110;
// static int IMG_WIDTH = 110;
// 窗口
static class Frame extends JFrame {
MyPanel panel;
// 初始化
public Frame() {
panel = new MyPanel(); add(panel);
this.setVisible(true);
this.setBounds(100, 100, FRAMEWIDTH, FRAMEHEIGHT);
this.setTitle("DrawImg");
this.setDefaultCloseOperation(EXIT_ON_CLOSE);
this.setResizable(false);
}
// 绘制图片
public void saveImgs(int idx) {
// 绘制图片
Image img = this.createImage(this.getWidth(), this.getHeight() );
this.panel.initImgs(idx);
this.panel.paint(img.getGraphics() );
img.flush();
try {
ImageIO.write((RenderedImage)img, "png", new File(Tools.getTmpPath(SUM_START + (SUM_IDX ++), Tools.PNG)) );
Log.log("save img success ...");
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 主面板
static class MyPanel extends JPanel {
// 所有需要展示的图片
static Image[] imgs;
// 初始化, 获取所有的需要展示的图片
static {
imgs = new Image[GRID_SUM];
initImgs(0);
}
// 绘制所有的图片
@Override
public void paint(Graphics g) {
int idx = 0;
for(int col=0; col<COL; col++) {
for(int row=0; row<ROW; row++) {
g.drawImage(imgs[idx], getRowIdx(row), getColIdx(col), getRowIdx(row+1), getColIdx(col+1), 0, 0, imgs[idx].getWidth(null), imgs[idx].getHeight(null), this);
idx ++;
}
}
}
// 获取第row行的相对于panel顶部
private int getRowIdx(int row) {
return row * PIXES_PER_COL;
}
private int getColIdx(int col) {
return col * PIXES_PER_ROW;
}
// 初始化图片
private static void initImgs(int idx) {
int picNum = GRID_SUM;
String suffix = Tools.PNG;
try {
for(int i=0; i<picNum; i++) {
imgs[i] = ImageIO.read(new File(Tools.getTmpPath(idx, suffix)) );
idx ++;
}
// swallow it
} catch (IOException e) {
// e.printStackTrace();
Log.err(Tools.getTmpPath(idx, suffix) + " is not an valid png picture ..");
}
}
}
}注 : 因为作者的水平有限,必然可能出现一些bug, 所以请大家指出!

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- 爬虫笔记
- PHP实现简单爬虫的方法
- NodeJS制作爬虫全过程(续)
- 一个PHP实现的轻量级简单爬虫
- nodejs爬虫抓取数据乱码问题总结
- nodejs爬虫抓取数据之编码问题
- JAVA使用爬虫抓取网站网页内容的方法
- 零基础写Java知乎爬虫之抓取知乎答案
- 零基础写Java知乎爬虫之先拿百度首页练练手
- 零基础写Java知乎爬虫之获取知乎编辑推荐内容
- Python编写百度贴吧的简单爬虫
- 零基础写python爬虫之使用urllib2组件抓取网页内容
- 零基础写python爬虫之抓取百度贴吧代码分享
- 零基础写python爬虫之urllib2使用指南
- python利用beautifulSoup实现爬虫
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- 零基础写python爬虫之urllib2中的两个重要概念:Openers和Handlers