03crawler01 爬取直播电视剧列表
2015-10-02 19:41
423 查看
不知道 大家没事的时候, 上不上一些直播平台瞅一愁, 有时候 你去翻列表, 是不是感觉眼睛都要花了, 你完全可以写一个爬虫程序将所有的感兴趣的数据下载下来, 然后再自己慢慢的来搜索了呗
一般来说 直播平台是分页的, 你可以将你感兴趣的栏目的所有的直播节目的相关信息下载下来, 然后 寻找自己感兴趣的直播节目
为了 简单, 我们这里只下载一个栏目的一个页面的直播信息
接下来 我们来实现一个功能, 抓取下面的页面的所有的电视剧的电视剧的名字 以及链接 [基于crawler.jar]
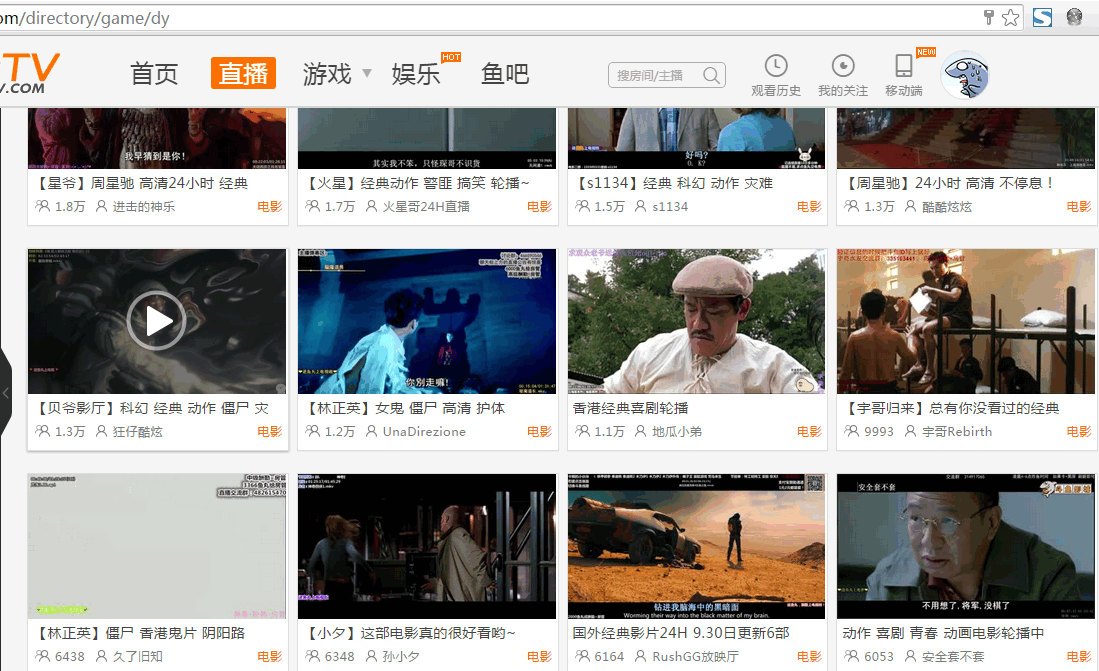
浏览器访问画面 :
结果截图 :
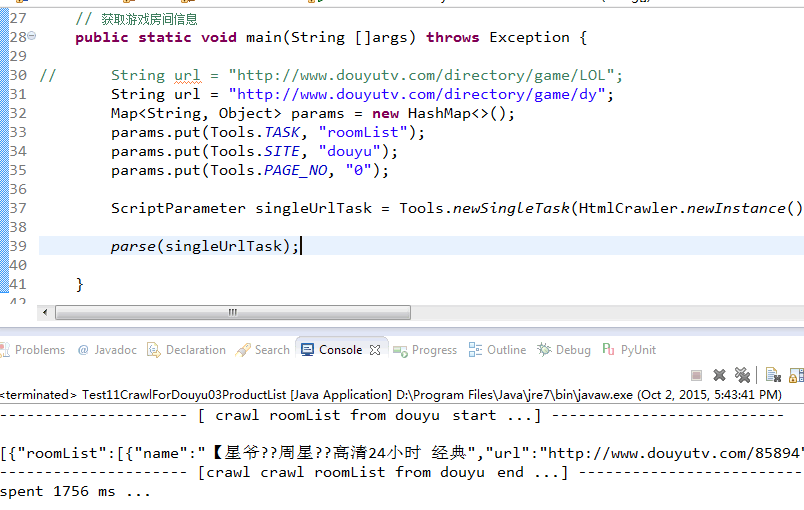
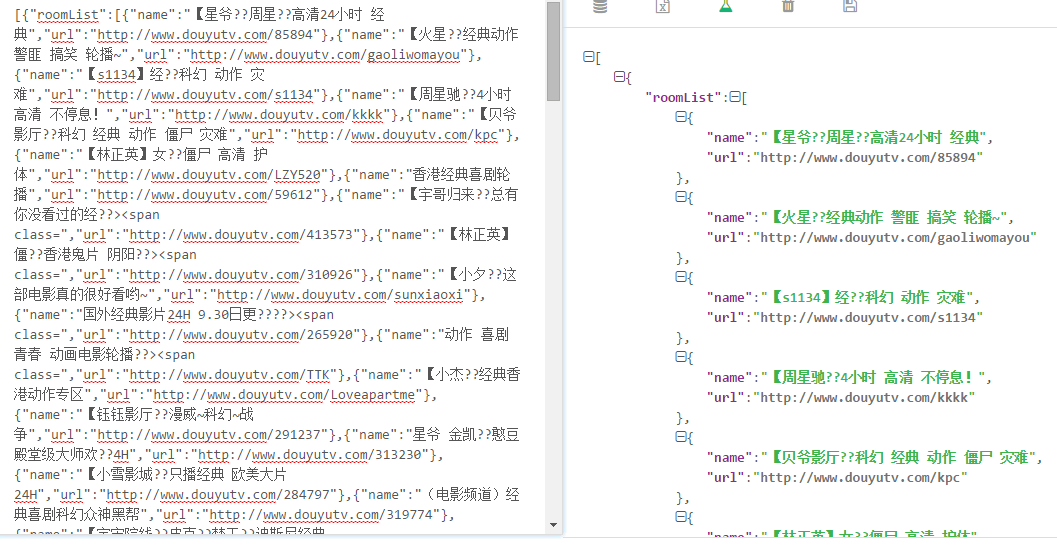
图中可能有一些乱码, 但是, 我没有找到原因所在…
代码如下 :
当然这里 只是一个简单的示例, 更多的想法, 大家可以任由自己的思路
注 : 因为作者的水平有限,必然可能出现一些bug, 所以请大家指出!
一般来说 直播平台是分页的, 你可以将你感兴趣的栏目的所有的直播节目的相关信息下载下来, 然后 寻找自己感兴趣的直播节目
为了 简单, 我们这里只下载一个栏目的一个页面的直播信息
接下来 我们来实现一个功能, 抓取下面的页面的所有的电视剧的电视剧的名字 以及链接 [基于crawler.jar]
浏览器访问画面 :
结果截图 :
图中可能有一些乱码, 但是, 我没有找到原因所在…
代码如下 :
/**
* file name : Test11CrawlForDouyu01GameList.java
* created at : 9:32:38 PM Sep 5, 2015
* created by 970655147
*/
package com.hx.crawler;
public class Test11CrawlForDouyu03ProductList {
// 测试站点 : http://www.douyutv.com/directory/game/LOL // 获取游戏房间信息
public static void main(String []args) throws Exception {
String url = "http://www.douyutv.com/directory/game/dy";
Map<String, Object> params = new HashMap<>();
params.put(Tools.TASK, "roomList");
params.put(Tools.SITE, "douyu");
params.put(Tools.PAGE_NO, "0");
ScriptParameter singleUrlTask = Tools.newSingleTask(HtmlCrawler.newInstance(), url, params);
parse(singleUrlTask);
}
// parse 接口
// 1. 获取目录
// 2. 将目录信息传递给下一个脚本
public static void parse(ScriptParameter scriptParameter) throws Exception {
String nextStage = Tools.Test11CrawlForDouyu04ProductInfo;
SingleUrlTask singleUrlTask = (SingleUrlTask) scriptParameter;
Crawler crawler = singleUrlTask.getCrawler();
String url = singleUrlTask.getUrl();
Map<String, Object> param = singleUrlTask.getParam();
String xpath = "{\"name\":\"roomList\",\"xpath\":\"/html/body//li/a[@class='list']\",\"values\":[{\"name\":\"name\",\"attribute\":\"title\"},{\"name\":\"url\",\"attribute\":\"href\"}]}";
xpath = Tools.getRealXPathByXPathObj(xpath);
// ------------------------1------------------------------
StringBuilder sb = new StringBuilder();
long start = System.currentTimeMillis();
Tools.appendCRLF(sb, "URL : " + url, true);
Tools.appendCRLF(sb, "--------------------- [" + Tools.getTaskName(singleUrlTask) + "start ...] --------------------------");
Log.log(sb.toString());
CrawlerConfig config = new CrawlerConfig();
config.setTimeout(30 * 1000);
Page page = crawler.getPage(url, config);
String html = page.getContent();
html = new String(html.getBytes(), "utf-8");
// Log.log(html);
// Tools.save(html, Tools.getTmpPath(7));
// Tools.getPreparedDoc(url, html, Tools.getTmpPath(7));
JSONArray fetchedData = Tools.getResultByXPath(html, url, xpath);
long spent = System.currentTimeMillis() - start;
Tools.appendCRLF(sb, fetchedData.toString(), true);
Tools.appendCRLF(sb, "--------------------- [crawl" + Tools.getTaskName(singleUrlTask) + "end ...] --------------------------");
Tools.appendCRLF(sb, "spent " + spent + " ms ...");
Log.log(sb.toString());
// ------------------------2------------------------------
if(! fetchedData.isEmpty()) {
}
}
}当然这里 只是一个简单的示例, 更多的想法, 大家可以任由自己的思路
注 : 因为作者的水平有限,必然可能出现一些bug, 所以请大家指出!

相关文章推荐
- Python3写爬虫(四)多线程实现数据爬取
- Scrapy的架构介绍
- 爬虫笔记
- 搜狗百度360市值齐跌:搜索引擎们陷入集体焦虑?
- 本人即将筹备败家日志,敬请期待!
- IE:使用搜索助手
- C++深度优先搜索的实现方法
- 基于文本的搜索
- php实现搜索一维数组元素并删除二维数组对应元素的方法
- 使用Sphinx对索引进行搜索
- asp 多关键词搜索的简单实现方法
- C#使用foreach语句搜索数组元素的方法
- JavaScript中数组的排序、乱序和搜索实现代码
- C#编程实现Excel文档中搜索文本内容的方法及思路
- sqlserver中在指定数据库的所有表的所有列中搜索给定的值
- 可以用来搜索当前页面内容的js代码
- 全文搜索和替换
- javascript搜索自动提示功能的实现第1/3页
- mysql 模糊搜索的方法介绍
- C#搜索文字在文件及文件夹中出现位置的方法