Hadoop笔记--Reduce方法中获取迭代器的值
2015-10-02 14:00
281 查看
由于迭代器只能对每一个元素分别进行处理,但是某些时候,却需要获取所有元素后再进行处理。所以打算把迭代器中的所有值存储在数组中,然后再进行相应的运算。
下边是两种将迭代器内的数值存储在array中的过程
1.
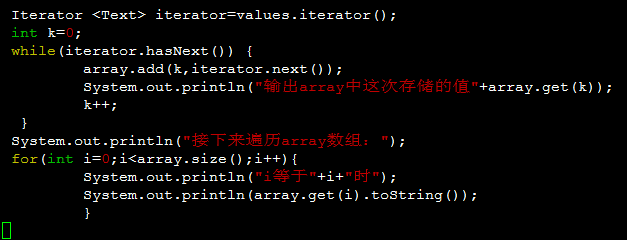
2.
两种做法均不正确。如果按照上边的代码执行。结果array中所有元素的值将等于迭代器的最后一个元素的值。
这是由于iterate.next()被单独分到了一个内存空间。而将iterate.next()赋值给array的过程传递的是iterate.next()的地址。这时array中所有元素保存的是iterate.next()的地址。
当最后一个迭代器中的内容将iterate.next()中存储的值改变后。array中元素的值都变为了迭代器的最后一个值。
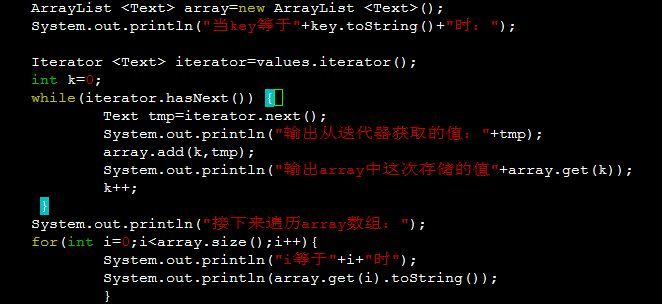
正确的做法是:
如果使用:
下边是两种将迭代器内的数值存储在array中的过程
1.
2.
两种做法均不正确。如果按照上边的代码执行。结果array中所有元素的值将等于迭代器的最后一个元素的值。
这是由于iterate.next()被单独分到了一个内存空间。而将iterate.next()赋值给array的过程传递的是iterate.next()的地址。这时array中所有元素保存的是iterate.next()的地址。
当最后一个迭代器中的内容将iterate.next()中存储的值改变后。array中元素的值都变为了迭代器的最后一个值。
正确的做法是:
Text tmp=new Text(iterator.next().toString());这就为新声明一个元素,并将迭代器中元素的值赋给它。这样每次循环都产生新的tmp,每个tmp保存不同的值。
如果使用:
for (Text val : values) {
}的方式去获取迭代器中的的每个元素也会出现上述问题。同样需要new一个新的内存空间。

相关文章推荐
- linux ethtool
- 挖墙脚?Linux 基金会让 Chromebook 用户安装 Linux
- nginx安装与配置
- opencv3.0.0环境搭建
- Linux 下编译自己的 OpenJDK7 包括JVM和JDK API
- Hadoop学习笔记(四)Hadoop伪分布式配置
- Linux电源管理(1)_整体架构
- linux命令一
- 不一样的命令行 – Windows PowerShell简介
- Shark machine learning library在linux下的安装
- windows和linux服务器之间的通信
- 几种在Linux下查询外网IP的办法。
- [置顶] OpenLayers 3 之 绘制图形(ol.interaction.Draw)原理解析
- linux中安装eclipse,安装好之后不能直接建servlet,不能直接在jsp页面中run on server.权限在作怪,我猜的,
- Linux系统下VI编辑器中如何删除整行
- Linux系统中设置串口属性的基本流程
- linux于test 订购具体解释
- apache2.2+tomcat实现负载均衡
- Apworks框架实战(四):使用Visual Studio开发面向经典分层架构的应用程序:从EasyMemo案例开始
- linux创建文件