Cuckoo Filter:设计与实现
2015-09-29 14:42
232 查看
Cuckoo Filter:设计与实现
http://coolshell.cn/articles/17225.html
对于海量数据处理业务,我们通常需要一个索引数据结构,用来帮助查询,快速判断数据记录是否存在,这种数据结构通常又叫过滤器(filter)。考虑这样一个场景,上网的时候需要在浏览器上输入URL,这时浏览器需要去判断这是否一个恶意的网站,它将对本地缓存的成千上万的URL索引进行过滤,如果不存在,就放行,如果(可能)存在,则向远程服务端发起验证请求,并回馈客户端给出警告。
索引的存储又分为有序和无序,前者使用关联式容器,比如B树,后者使用哈希算法。这两类算法各有优劣:比如,关联式容器时间复杂度稳定O(logN),且支持范围查询;又比如哈希算法的查询、增删都比较快O(1),但这是在理想状态下的情形,遇到碰撞严重的情况,哈希算法的时间复杂度会退化到O(n)。因此,选择一个好的哈希算法是很重要的。
时下一个非常流行的哈希索引结构就是bloom filter,它类似于bitmap这样的hashset,所以空间利用率很高。其独特的地方在于它使用多个哈希函数来避免哈希碰撞,如图所示(来源wikipedia),bit数组初始化为全0,插入x时,x被3个哈希函数分别映射到3个不同的bit位上并置1,查询x时,只有被这3个函数映射到的bit位全部是1才能说明x可能存在,但凡至少出现一个0表示x肯定不存在。
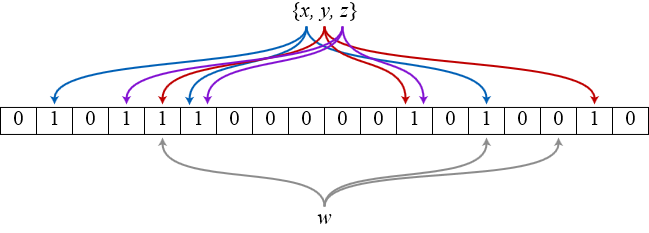
但是,bloom filter的这种位图模式带来两个问题:一个是误报(false positives),在查询时能提供“一定不存在”,但只能提供“可能存在”,因为存在其它元素被映射到部分相同bit位上,导致该位置1,那么一个不存在的元素可能会被误报成存在;另一个是漏报(false nagatives),同样道理,如果删除了某个元素,导致该映射bit位被置0,那么本来存在的元素会被漏报成不存在。由于后者问题严重得多,所以bloom filter必须确保“definitely
no”从而容忍“probably yes”,不允许元素的删除。
关于元素删除的问题,一个改良方案是对bloom filter引入计数,但这样一来,原来每个bit空间就要扩张成一个计数值,空间效率上又降低了。
Cuckoo Hashing
为了解决这一问题,本文引入了一种新的哈希算法——cuckoo filter,它既可以确保该元素存在的必然性,又可以在不违背此前提下删除任意元素,仅仅比bitmap牺牲了微量空间效率。先说明一下,这个算法的思想来源是一篇CMU论文,笔者按照其思路用C语言做了一个简单实现(Github),附上对一段文本数据进行导入导出的正确性测试。接下来我会结合自己的示例代码讲解哈希算法的实现。我们先来看看cuckoo hashing有什么特点,它的哈希函数是成对的(具体的实现可以根据需求设计),每一个元素都是两个,分别映射到两个位置,一个是记录的位置,另一个是备用位置。这个备用位置是处理碰撞时用的,这就要说到cuckoo这个名词的典故了,中文名叫布谷鸟,这种鸟有一种即狡猾又贪婪的习性,它不肯自己筑巢,而是把蛋下到别的鸟巢里,而且它的幼鸟又会比别的鸟早出生,布谷幼鸟天生有一种残忍的动作,幼鸟会拼命把未出生的其它鸟蛋挤出窝巢,今后以便独享“养父母”的食物。借助生物学上这一典故,cuckoo
hashing处理碰撞的方法,就是把原来占用位置的这个元素踢走,不过被踢出去的元素还要比鸟蛋幸运,因为它还有一个备用位置可以安置,如果备用位置上还有人,再把它踢走,如此往复。直到被踢的次数达到一个上限,才确认哈希表已满,并执行rehash操作。如下图所示(图片来源):
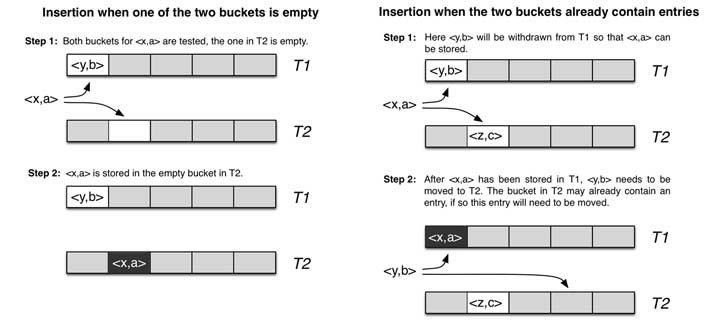
我们不禁要问发生哈希碰撞之前的空间利用率是多少呢?不幸地告诉你,一维数组的哈希表上跟其它哈希函数没什么区别,也就50%而已。但如果是二维的呢?
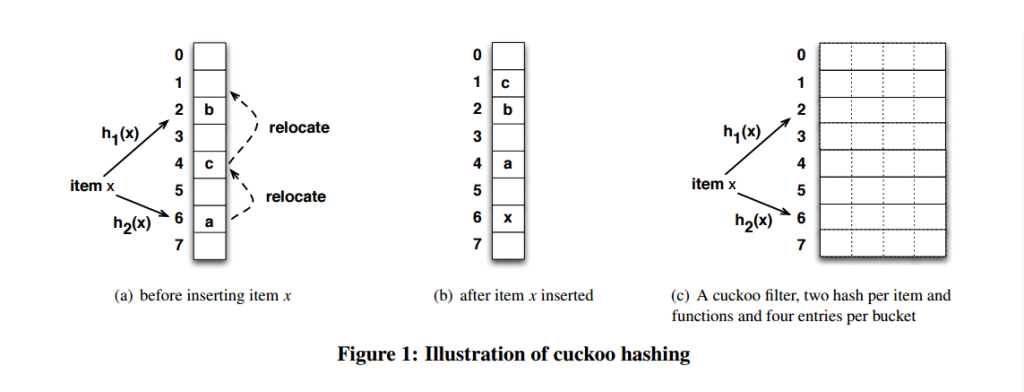
一个改进的哈希表如下图所示,每个桶(bucket)有4路槽位(slot)。当哈希函数映射到同一个bucket中,在其它三路slot未被填满之前,是不会有元素被踢的,这大大缓冲了碰撞的几率。笔者自己的简单实现上测过,采用二维哈希表(4路slot)大约80%的占用率(CMU论文数据据说达到90%以上,应该是扩大了slot关联数目所致)。
Cuckoo Filter设计与实现
cuckoo hashing的原理介绍完了,下面就来演示一下笔者自己实现的一个cuckoo filter应用,简单易用为主,不到500行C代码。应用场景是这样的:假设有一段文本数据,我们把它通过cuckoo filter导入到一个虚拟的flash中,再把它导出到另一个文本文件中。flash存储的单元页面是一个log_entry,里面包含了一对key/value,value就是文本数据,key就是这段大小的数据的SHA1值(照理说SHA1是可以通过数据源生成,没必要存储到flash,但这里主要为了测试而故意设计的,万一key和value之间没有推导关系呢)。以上是flash的存储结构,至于哈希表里的slot有三个成员tag,status和offset,分别是哈希值,状态值和在flash的偏移位置。其中status有三个枚举值:AVAILIBLE,OCCUPIED,DELETED,分别表示这个slot是空闲的,占用的还是被删除的。至于tag,按理说应该有两个哈希值,对应两个哈希函数,但其中一个已经对应bucket的位置上了,所以我们只要保存另一个备用bucket的位置就行了,这样万一被踢,只要用这个tag就可以找到它的另一个安身之所。
至于哈希表以及bucket和slot的创建见初始化代码。buckets是一个二级指针,每个bucket指向4个slot大小的缓存,即4路slot,那么bucket_num也就是slot_num的1/4。这里我们故意把slot_num调小了点,为的是测试rehash的发生。
参考资料
Cuckoo Filter的论文和PPT:CuckooFilter: Practically Better Than Bloom

相关文章推荐
- 需要安装 MongoDB,RabbitMQ,或者 MySQL?使用 Docker 来简化开发和测试
- java中的String作为参数引起的一些研究
- [IOS 开发] iOS 如何将日期字符串转成NSDate
- 需要安装 MongoDB,RabbitMQ,或者 MySQL?使用 Docker 来简化开发和测试
- SNMP v1 v2 v3
- B树、B+树、AVL树、红黑树
- Android清除本地数据缓存代码
- txt无法正常保存正文的解决办法
- [PHP-Debug] 使用 php -l 调试 PHP 错误遇到的坑
- [置顶] 我的Android进阶之旅------>Android解决异常: startRecording() called on an uninitialized AudioRecord.
- 四个PHP非常实用的功能
- CooradicatoarLayout 介绍
- Objective-C---5---字典,集合
- 【LeetCode】136 & 137 & 260 - Single Number I & II &III
- python中的enumerate
- git push 时遇到的问题
- 利用JDBC根据表结构生成ModelClass
- 重写和重载的区别
- Oracle中单引号的使用
- Mac-OSX下Ruby更新