leveldb设计分析之log
2015-09-25 10:49
316 查看
在leveldb中log的意义是什么?
所有的写操作都必须先成功的append到操作日志中,然后再更新内存memtable。这样做有两个有点:
1可以将随机的写IO变成append,极大的提高写磁盘速度;
2防止在节点down机导致内存数据丢失,造成数据丢失,这对系统来说是个灾难。
log由连续的block组成,每个大小为固定的32kb,而每个block由连续的record组成。
record的内部结构如下:
log有四种类型: FULL,FIRST, MIDDLE, LAST。为什么会有这四种类型?分开说。如果一个用户的数据小于32kb。那么它可以在一个block里存放。这时,数据所在record(只有一个)的logtype就是FULL,如果用户数据很大,超过32kb,并且占据了好多个block。那么第一个block中存放的数据record,就是FIRST(它其实是上次数据占用block部分空间后,剩余部分)。中间block的所有的record都是MIDDLE类型,而最后一个block,也有一部分数据,那么这个record就是LAST,当然它可能占不满block,那么剩下的空间就是下一个user data的FIRST。下面有个图比较直观:
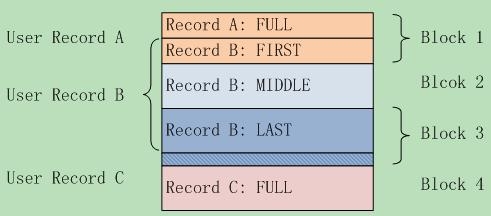
我们可以看出,由于record有data数据,所以它不是定长的。而且用户角度的record跟底层log中结构中的record是不一样的。用户的record数据可能很大,可能跨越很多block。由于record是block内部的结构,导致最终落实到内部结构时无法跨越block,所以导致了分拆。
在实现方面,通过leftover来跟踪当前block内剩余的空间,其中block_offset_在block内的偏移。当剩余空间少于7个字符(record内部结构图中的4+2+1)用0填充(一般是6个字符的空间)。剩下的逻辑就要其实是按block为单位大小来写入的,一直写直到处理完用户提交的数据。实际的写入动作其实委托给了EmitPhysicalRecord函数。在EmitPhysicalRecord函数内部首先会生成一个record头部(包括前面提到的4+2+1结构),然后把用户的payload追加到后面就可以了。
实际的读取动作在ReadPhysicalRecord函数里。在函数里面首先处理一个情况就是buffer_.size() < kHeaderSize。该条件成立,一种情况是出现在第一次read,因为buffer_在reader的构造函数里是初始化空的,第二种情况就是上次read是一个FULL类型的record,那么当前读到record后面剩余的内容为6个0的trailer。这里需要识别到这种情况,并反馈给上层告知EOF。
除了上面的情况,那么意味着当前读到了一个有效的record。核心的处理就是解析record header并告知上层,同时使用Slice *result参数携带解析得到的payload数据。
ReadRecord接下来处理各种record类型,并依次将user data追加到scratch参数提供的内存中, 并在发现FIRST类型时标记处本次处理的record的位置,即last_record_offset_。
其中使用in_fragmented_record来检测record的完整性。当发现FIRST类型的record时,该变量被置为true,那么在任何时候碰到MIDDLE,LAST,但是in_fragmented_record却为false的,都算是异常情况。
所有的写操作都必须先成功的append到操作日志中,然后再更新内存memtable。这样做有两个有点:
1可以将随机的写IO变成append,极大的提高写磁盘速度;
2防止在节点down机导致内存数据丢失,造成数据丢失,这对系统来说是个灾难。
log的结构
+-------------+-------------+-------------+-------------+ | block | block | block | block | +-------------+-------------+-------------+-------------+
log由连续的block组成,每个大小为固定的32kb,而每个block由连续的record组成。
+--------+ | record | +--------+ | record | +--------+ | record | +--------+
record的内部结构如下:
4 bytes 2 bytes 1 byte +-------------+-------------+--------------+-----------+ | crc32 | length | log type | data | +-------------+-------------+--------------+-----------+
log有四种类型: FULL,FIRST, MIDDLE, LAST。为什么会有这四种类型?分开说。如果一个用户的数据小于32kb。那么它可以在一个block里存放。这时,数据所在record(只有一个)的logtype就是FULL,如果用户数据很大,超过32kb,并且占据了好多个block。那么第一个block中存放的数据record,就是FIRST(它其实是上次数据占用block部分空间后,剩余部分)。中间block的所有的record都是MIDDLE类型,而最后一个block,也有一部分数据,那么这个record就是LAST,当然它可能占不满block,那么剩下的空间就是下一个user data的FIRST。下面有个图比较直观:
我们可以看出,由于record有data数据,所以它不是定长的。而且用户角度的record跟底层log中结构中的record是不一样的。用户的record数据可能很大,可能跨越很多block。由于record是block内部的结构,导致最终落实到内部结构时无法跨越block,所以导致了分拆。
write
写入的接口是AddRecord。Status Writer::AddRecord(const Slice& slice)
在实现方面,通过leftover来跟踪当前block内剩余的空间,其中block_offset_在block内的偏移。当剩余空间少于7个字符(record内部结构图中的4+2+1)用0填充(一般是6个字符的空间)。剩下的逻辑就要其实是按block为单位大小来写入的,一直写直到处理完用户提交的数据。实际的写入动作其实委托给了EmitPhysicalRecord函数。在EmitPhysicalRecord函数内部首先会生成一个record头部(包括前面提到的4+2+1结构),然后把用户的payload追加到后面就可以了。
read
ReadRecord函数执行具体的读取log的动作。在一开始需要先设置一下处理点,如果last_record_offset_小于initial_offset_,那么需要将处理点移动到initial_offset_开始(函数SkipToInitialBlock)。在reader构造函数中,initial_offset_跟last_record_offset_都是0。那么在什么情况下,last_record_offset_会比initial_offset_小呢?实际的读取动作在ReadPhysicalRecord函数里。在函数里面首先处理一个情况就是buffer_.size() < kHeaderSize。该条件成立,一种情况是出现在第一次read,因为buffer_在reader的构造函数里是初始化空的,第二种情况就是上次read是一个FULL类型的record,那么当前读到record后面剩余的内容为6个0的trailer。这里需要识别到这种情况,并反馈给上层告知EOF。
除了上面的情况,那么意味着当前读到了一个有效的record。核心的处理就是解析record header并告知上层,同时使用Slice *result参数携带解析得到的payload数据。
ReadRecord接下来处理各种record类型,并依次将user data追加到scratch参数提供的内存中, 并在发现FIRST类型时标记处本次处理的record的位置,即last_record_offset_。
其中使用in_fragmented_record来检测record的完整性。当发现FIRST类型的record时,该变量被置为true,那么在任何时候碰到MIDDLE,LAST,但是in_fragmented_record却为false的,都算是异常情况。

相关文章推荐
- 基于zookeeper+leveldb搭建activemq集群
- [转]Leveldb实现原理
- LevelDB的实现原理
- leveldb中的编码方式的分析
- caffe RGB转gay存储为Leveldb 格式(CIFAR10)示例
- 编译、测试 leveldb
- LevelDb 详解
- undefined reference to `snappy::MaxCompressedLength(unsigned long)'
- option-levelDB源码解析
- Slice-levelDB源码解析
- Status-levelDB源码解析
- varint-levelDB源码解析
- VersionSet-levelDB源码解析
- Version-levelDB源码解析
- VersionEdit-levelDB源码解析
- memtable-levelDB源码解析
- log::Writer-levelDB源码解析
- log::Reader-levelDB源码解析
- log format-levelDB源码解析
- Block-levelDB源码解析