学习日志---hdfs配置及原理+yarn的配置
2015-09-18 23:37
316 查看
筛选算法:
关注度权重公式:
W = TF * Log(N/DF)
TF:当前关键字在该条记录中出现的总次数;
N:总的记录数;
DF:当前关键字在所有记录中出现的条数;
HDFS的 namenode HA和namenode Federation
(1)解决单点故障:
使用HDFS HA :通过主备namenode解决;如果主发生故障,则切换到备上。
(2)解决内存受限:
使用HDFS Federation,水平扩展,支持多个namenode,相互独立。共享所有datanode。
下面详细说明:
namenode HA:namenode对元数据的修改都会经过journalnode,在QJM的集群上备份一个,因此QJM上元数据和namenode上元数据是一样的(namenode的元数据就是QJM上的元数据镜像),在namenode挂掉后,standby的namenode会找QJM集群上的元数据,继续工作。如果使用namenode Federation,则每个namenode的共享数据都会在journalnode的集群上。相当于每个namenode上都存了一个对journalnode集群的镜像,namenode的读写,都是在jn集群上修改和寻找的。
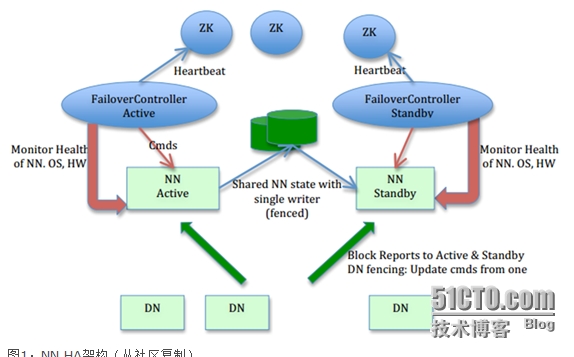
客户端一开始请求hdfs时,先访问zookeeper,去检查哪些namenode挂掉了,哪些活着,去决定访问哪个namenode。任何一个namenode都会对应一个FailoverController,也就是ZKFC竞争锁。在一个namenode挂掉后,有竞争锁来选择用哪一个namenode,这里使用的是投票机制,因此zookeeper要使用奇数的。
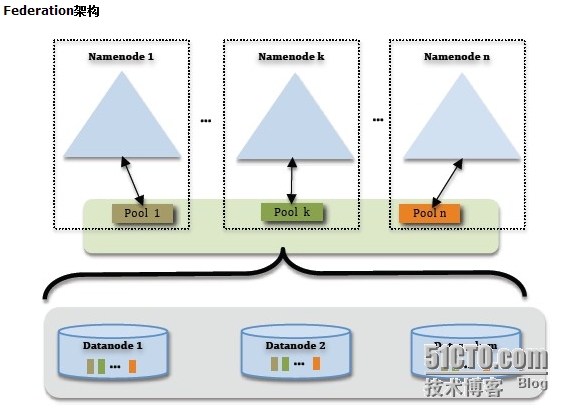
namenode Federation:是在一个集群中有若干个独立的namenode,相当于多个独立的集群,但是共用datanode。客户端访问这些namenode时,要选择使用哪个namenode才可以访问和使用。
在Federation上加HA,是对每一个namenode都加HA,互相独立。
YARN:
YARN是资源管理系统,管理HDFS的数据,知晓数据的所有情况;计算框架向yarn去申请资源去计算,可以做到资源不浪费,可以并发的运行计算框架;兼容其他第三方的并行计算框架;
在资源管理方面:
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。其在每个节点上工作时有nodeManager,这里面就有ApplicationMaster。
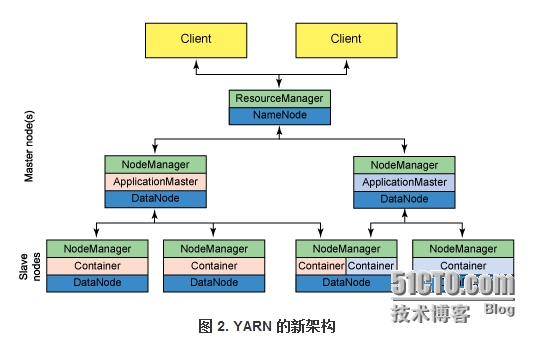
nodeManager最好是在datanode的机器上,因为方便计算;
以namenode HA的方式来配置启动hadoop集群
配置hdfs-site.xml及其说明:
这里都是对hdfs的配置进行操作,如哪些node上有哪些特定的操作。
root用户下的.bashrc文件是环境变量的配置文件,只供root用户使用
zookeeper的配置:
一个是先配置dir路径,以存放文件,避免关闭后zookeeper信息丢失
在zookeeper的配置文件中还有一个这个dataDir=/root/data/zookeeper,里面有个myid文件
[root@hadoop11 data]# cd zookeeper/
[root@hadoop11 zookeeper]# ls
myid version-2
这个myid文件指明了当前的zookeeper在集群中的编号是几。
配置过程简述:

现在每台机器上启动zookeeper,zk。。。启动。不要动
而后,hdfs-daemon.sh journalnode,启动journalnode,在其中一个机器上启动namenode,使用hdfs namenode -format,得到namenode的源文件,可以启动这个节点的namenode,再在另一个namenode上使用hdfs namenode -bootstrapStandby,作为备用的节点,两个namenode的元文件一样。
If you are setting up a fresh HDFS cluster, you should first run the format command (hdfs namenode -format) on one of NameNodes.
If you have already formatted the NameNode, or are converting a
non-HA-enabled cluster to be HA-enabled, you should now copy over the
contents of your NameNode metadata directories to the other, unformatted
NameNode by running the command "hdfs namenode -bootstrapStandby" on the unformatted NameNode. Running this command will also ensure that the JournalNodes (as configured by dfs.namenode.shared.edits.dir) contain sufficient edits transactions to be able to start both NameNodes.
If you are converting a non-HA NameNode to be HA, you should run the command "hdfs -initializeSharedEdits", which will initialize the JournalNodes with the edits data from the local NameNode edits directories.
每个namenode上都有一个zkfc,是失败机制,与zookeeper交互的。
在某一个namenode上要执行下列指令,使得zkfc与zookeeper相关联
使得zkfc可以正常启动
initialize required state in ZooKeeper. You can do so by running the
following command from one of the NameNode hosts.
hdfs的一些特点:
sbin目录下的hadoop-deamon.sh 【节点】可以用于开启该机器上的某一个节点
可以用kill -9 哪个进程 去杀掉某一个进程的node
start-dfs.sh启动集群的hdfs
把hadoop的bin和sbin配置在环境变量后,可以使用hdfs实现很多操作,如下:
[root@hadoop11 ~]# hdfs
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
YARN的配置
mapred-site.xml 中
在每个节点上都有yarn,其会根据自己的yarn的配置去有序的形成一个集群,以resourcemanager为主。
在resourcemanager要求的地址启动yarn,才会启动resourcemanager。
如果要在hadoop上运行mapreduce:
要把mapreduce程序打包,放在hadoop集群中;
使用指令:hadoop jar [web.jar程序名] [主函数所在的类名] [输入文件路径] [输出文件路径]
如:hadoop jar web.jar org.shizhen.wordcount /test /output
之后就可在output上查看了
hadoop集群中本身的hadoop和yarn就对应了很多指令:
使用这些指令可以操作某个进程某个节点。。。。
[root@hadoop11 ~]# hadoop
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
使用这些yarn类的指令,可以操纵mapreduce相关的节点和监控程序的流程,如application。。。
[root@hadoop11 ~]# yarn
Usage: yarn [--config confdir] COMMAND
where COMMAND is one of:
resourcemanager run the ResourceManager
nodemanager run a nodemanager on each slave
historyserver run the application history server
rmadmin admin tools
version print the version
jar <jar> run a jar file
application prints application(s) report/kill application
applicationattempt prints applicationattempt(s) report
container prints container(s) report
node prints node report(s)
logs dump container logs
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
配置完成后:
启动时先zkServer.sh start 启动zookeeper,然后start-all.sh启动hadoop即可。
关注度权重公式:
W = TF * Log(N/DF)
TF:当前关键字在该条记录中出现的总次数;
N:总的记录数;
DF:当前关键字在所有记录中出现的条数;
HDFS的 namenode HA和namenode Federation
(1)解决单点故障:
使用HDFS HA :通过主备namenode解决;如果主发生故障,则切换到备上。
(2)解决内存受限:
使用HDFS Federation,水平扩展,支持多个namenode,相互独立。共享所有datanode。
下面详细说明:
namenode HA:namenode对元数据的修改都会经过journalnode,在QJM的集群上备份一个,因此QJM上元数据和namenode上元数据是一样的(namenode的元数据就是QJM上的元数据镜像),在namenode挂掉后,standby的namenode会找QJM集群上的元数据,继续工作。如果使用namenode Federation,则每个namenode的共享数据都会在journalnode的集群上。相当于每个namenode上都存了一个对journalnode集群的镜像,namenode的读写,都是在jn集群上修改和寻找的。
客户端一开始请求hdfs时,先访问zookeeper,去检查哪些namenode挂掉了,哪些活着,去决定访问哪个namenode。任何一个namenode都会对应一个FailoverController,也就是ZKFC竞争锁。在一个namenode挂掉后,有竞争锁来选择用哪一个namenode,这里使用的是投票机制,因此zookeeper要使用奇数的。
namenode Federation:是在一个集群中有若干个独立的namenode,相当于多个独立的集群,但是共用datanode。客户端访问这些namenode时,要选择使用哪个namenode才可以访问和使用。
在Federation上加HA,是对每一个namenode都加HA,互相独立。
YARN:
YARN是资源管理系统,管理HDFS的数据,知晓数据的所有情况;计算框架向yarn去申请资源去计算,可以做到资源不浪费,可以并发的运行计算框架;兼容其他第三方的并行计算框架;
在资源管理方面:
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。其在每个节点上工作时有nodeManager,这里面就有ApplicationMaster。
nodeManager最好是在datanode的机器上,因为方便计算;
以namenode HA的方式来配置启动hadoop集群
配置hdfs-site.xml及其说明:
这里都是对hdfs的配置进行操作,如哪些node上有哪些特定的操作。
<configuration> <property> <name>dfs.name.dir</name> <value>/root/data/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>/root/data/datanode</value> </property> <property> <name>dfs.tmp.dir</name> <value>/root/data/tmp</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> //nameservices是该集群的名字,是唯一的标示,供zookeeper去识别,mycluster就是名字,可以改为其他的 <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> //指明在该集群下,有几个namenode及其名字,这里有集群的名字,和上面的对应 <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> //每个namenode的rpc协议的地址,为了传递数据用的,客户端上传下载用这个 <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop11:4001</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop22:4001</value> </property> <property> <name>dfs.namenode.servicerpc-address.mycluster.nn1</name> <value>hadoop11:4011</value> </property> <property> <name>dfs.namenode.servicerpc-address.mycluster.nn2</name> <value>hadoop22:4011</value> </property> //http协议的端口,是为了通过网络,如浏览器,去查看hdfs的 <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop11:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop22:50070</value> </property> //这里是配置journalnode的主机,配置为奇数个,集群中在哪些机器上有journalnode。 //namenode进行读写时,请求的是这个地址,journalnode实时的记录了文件的情况,外界访问namenode,namenode一方面自己响应请求,一方面找journalnode进行读写,做好备份。 <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop11:8485;hadoop22:8485;hadoop33:8485/mycluster</value> </property> //journalNode在机器上的文件位置,工作目录 <property> <name>dfs.journalnode.edits.dir</name> <value>/root/data/journaldata/</value> </property> //外界连接激活的namenode调用的类 //供外界去找到active的namenode <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> //自动切换namenode <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> //用于一台机子登陆另一台机器使用的密匙的位置 <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> //私钥文件所在的位置 <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property>配置core-site.xml
//这个是hdfs的统一入口,mycluster是我们自己配置的该集群的统一服务标识 //外界访问的是这个集群 <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> //由zookeeper去管理hdfs,这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点 <property> <name>ha.zookeeper.quorum</name> <value>hadoop11:2181,hadoop22:2181,hadoop33:2181</value> </property>如果一个不是HA的namenode变为HA的,则在要改的namenode的主机上执行hdfs -initializeSharedEdits,这可以使该namenode上的元数据改为journalnode上的元数据。
root用户下的.bashrc文件是环境变量的配置文件,只供root用户使用
zookeeper的配置:
一个是先配置dir路径,以存放文件,避免关闭后zookeeper信息丢失
server.1=hadoop11:2888:3888 server.2=hadoop22:2888:3888 server.3=hadoop33:2888:3888server.1是指zookeeper在集群中的编号
在zookeeper的配置文件中还有一个这个dataDir=/root/data/zookeeper,里面有个myid文件
[root@hadoop11 data]# cd zookeeper/
[root@hadoop11 zookeeper]# ls
myid version-2
这个myid文件指明了当前的zookeeper在集群中的编号是几。
配置过程简述:
现在每台机器上启动zookeeper,zk。。。启动。不要动
而后,hdfs-daemon.sh journalnode,启动journalnode,在其中一个机器上启动namenode,使用hdfs namenode -format,得到namenode的源文件,可以启动这个节点的namenode,再在另一个namenode上使用hdfs namenode -bootstrapStandby,作为备用的节点,两个namenode的元文件一样。
If you are setting up a fresh HDFS cluster, you should first run the format command (hdfs namenode -format) on one of NameNodes.
If you have already formatted the NameNode, or are converting a
non-HA-enabled cluster to be HA-enabled, you should now copy over the
contents of your NameNode metadata directories to the other, unformatted
NameNode by running the command "hdfs namenode -bootstrapStandby" on the unformatted NameNode. Running this command will also ensure that the JournalNodes (as configured by dfs.namenode.shared.edits.dir) contain sufficient edits transactions to be able to start both NameNodes.
If you are converting a non-HA NameNode to be HA, you should run the command "hdfs -initializeSharedEdits", which will initialize the JournalNodes with the edits data from the local NameNode edits directories.
每个namenode上都有一个zkfc,是失败机制,与zookeeper交互的。
在某一个namenode上要执行下列指令,使得zkfc与zookeeper相关联
使得zkfc可以正常启动
Initializing HA state in ZooKeeper
After the configuration keys have been added, the next step is toinitialize required state in ZooKeeper. You can do so by running the
following command from one of the NameNode hosts.
$ hdfs zkfc -formatZKThis will create a znode in ZooKeeper inside of which the automatic failover system stores its data.
hdfs的一些特点:
sbin目录下的hadoop-deamon.sh 【节点】可以用于开启该机器上的某一个节点
可以用kill -9 哪个进程 去杀掉某一个进程的node
start-dfs.sh启动集群的hdfs
把hadoop的bin和sbin配置在环境变量后,可以使用hdfs实现很多操作,如下:
[root@hadoop11 ~]# hdfs
Usage: hdfs [--config confdir] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
YARN的配置
mapred-site.xml 中
mapred-site.xml <configuration> //这里是指明mapreduce使用的是哪个框架 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>yarn-site.xml中
yarn-site.xml <configuration> //下面几个在每个节点中配置的都一样,因为这里指明集群中使用哪台机器作为resourcemanager //这个是yarn资源管理器地址,用于外界连接到资源管理器(这个) <property> <name>yarn.resourcemanager.address</name> <value>hadoop1:9080</value> </property> //应用程序宿主借此与资源管理器通信 <property> <name>yarn.resourcemanager.scheduler.address</name> <value>hadoop1:9081</value> </property> //节点管理器借此与资源管理器通信的端口,如在hadoop2中陪这个,2中的nodemanager就可以找到1的resourcemanager <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>hadoop1:9082</value> </property> //节点管理器运行的附加服务列表 <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>每台机器都可以自己启动nodemanager,使用yarn-darmon.sh start nodemanager,这是启动的nodemanager会根据yarn-site.xml文件中的配置找到其resourcemanager。但是在集群中nodemanager是运行在datanode上,去管理datanode的,因此如果在slaves中指明哪些机器上有datanode,在主机上使用start-yarn.sh时,该主机作为resourcemanager,同时会从slaves中,把该文件中的节点上启动nodemanager。
在每个节点上都有yarn,其会根据自己的yarn的配置去有序的形成一个集群,以resourcemanager为主。
在resourcemanager要求的地址启动yarn,才会启动resourcemanager。
如果要在hadoop上运行mapreduce:
要把mapreduce程序打包,放在hadoop集群中;
使用指令:hadoop jar [web.jar程序名] [主函数所在的类名] [输入文件路径] [输出文件路径]
如:hadoop jar web.jar org.shizhen.wordcount /test /output
之后就可在output上查看了
hadoop集群中本身的hadoop和yarn就对应了很多指令:
使用这些指令可以操作某个进程某个节点。。。。
[root@hadoop11 ~]# hadoop
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
使用这些yarn类的指令,可以操纵mapreduce相关的节点和监控程序的流程,如application。。。
[root@hadoop11 ~]# yarn
Usage: yarn [--config confdir] COMMAND
where COMMAND is one of:
resourcemanager run the ResourceManager
nodemanager run a nodemanager on each slave
historyserver run the application history server
rmadmin admin tools
version print the version
jar <jar> run a jar file
application prints application(s) report/kill application
applicationattempt prints applicationattempt(s) report
container prints container(s) report
node prints node report(s)
logs dump container logs
classpath prints the class path needed to get the
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
配置完成后:
启动时先zkServer.sh start 启动zookeeper,然后start-all.sh启动hadoop即可。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- java结合HADOOP集群文件上传下载
- 用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
- Hadoop安装感悟
- hadoop安装lzo