西风的数据结构教程(4)——hash表
2015-09-10 20:20
363 查看
今天是教师节,感恩老师们的辛勤工作,让我们不断成长。
今天制作的这份教程十分重要,是我们高中时必会,而且是计算机体系中占有关键地位的一种数据结构——hash表。
要说hash表为何常用,为何厉害,那么我们先来考虑一个问题。
而另外一种重要的模型,就是 key-value键值对 模型,hash算法,重在构建一个高效的key-value模型。例如,我们有很多网页要浏览,而刚刚浏览过的网页再次打开,一般会快很多,因为浏览器帮我们做了缓存,然而我们细想,如何缓存呢?我们怎么才能知道这个网页我们刚刚访问过么?
那么我们可以建立一个key-value的模型,如果刚刚访问过,我们就将网页内容存放到value处,而key就存放网页的url。
例如我们的手机应用,希望快速的查找一个联系人的相关信息,那么遍历所有人员恐怕不是一个好想法,而用key-value模型根据名字索引找到则更方便。
hash算法除了可以构建key-value模型,更可以作为数据校验和数据加密的重要算法。
hash函数是一种单向不可逆函数,MD5是流行的数据校验用hash算法,下载下来的数据是否和网络上的一致,用hash计算一下结果,然后比较网络上的hash值和本地计算的hash值,一致的话就说明数据不存在异常。
sha系列hash算法,在网站密码的加密上有着重要的作用。一般开发网站的朋友都了解,网站用户的密码是不能明文保存的,因为万一数据泄露后,会对用户隐私造成重大威胁。那么用什么来判断密码是否正确呢?将hash后的密码作为值存储起来,判断密码正确前,也将用户的输入hash一次,这样就可以在不知道用户密码的前提下,判断是否为同一用户。
而我们需要的是,尽快根据一个名字索引到对应的数据。有人说,简单啊,排序一下,然后根据二分查找的思想,对应判断就可以了。没错,二分查找是一种好思想,但也不是完全没有问题,如果我们的系统是动态的话,就很困难了,先存入两个数据,再删除一条,如果真想按照刚才的思想做,就必须做一棵高效平衡二叉树,普通的排序树有风险,可能退化的。而这样就太复杂了,hash表则提供了一种快速简单的思路,实现这个效果。
简单的链地址法的hash表:
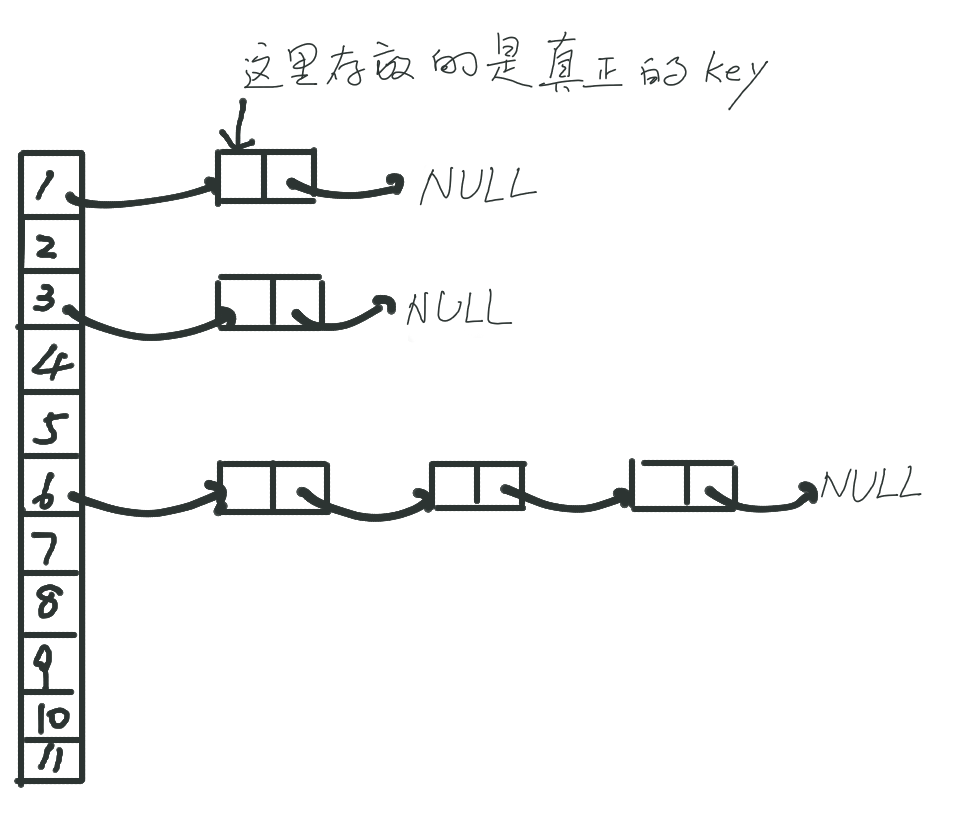
hash表的结构其实很简单,就是一个较大的线性表,然后你去将key用一个函数计算一下,让结果分布到整个线性表中。由于hash函数一般都没有什么实际含义,一般希望 分布均匀,具有雪崩效应 (输入变化小,输出变化大),这样的映射函数就比较好了。
而在字符串hash中, Times33 算法是一种著名的算法。
算法很简单,就是在不断的×33
一般来说,这个算法并没有什么特别深的理论依据,主要是经验性质的判断,对小心英文序列,33这个系数比较合适,对于大小写混合的,65比较好,还有使用31和131作为系数的版本,也都比较常见。
所以hash表重要的一环就是冲突的解决。
如果又有一个hash为4的元素来了怎么办?继续后移啊,要是到了末尾还没发现空位,就再回到头开始找,但如果找了一圈都没发现空位,那么说明表满了。
查找时,算出对应的位置,然后从这个位置一直往后找,直到找到这个元素为止,或者碰到空停下,或者全满时绕了一圈发现没有。
这种方法虽然简单,但效率确实不高,在不存在删除的情况下还比较好,但如果存在删除的情况时,那删除时,就必须向后找到最后一个对应元素,然后将其挪到当前位置上,否则,这个寻找的链就因为删除时的空断开了。
这个方法被成为 开地址法 ,也叫 线性探测法。
新地址:Hn=(H+1)
H是当前地址, Hn是下一次要探测的新地址
新地址:Hn=(Hkey+d) d=1, -1, 4, -4, 9, -9……
这样往后看一下,往前看一下,再往后,再往前,确实要比线下查找分布均匀一些,但计算依旧比较复杂。
随机探测法,就是说这的d序列,是一个随机序列,虽说是随机序列,但这随机序列的种子我们是知道的,所以可以确定好这个hash表中所使用的序列是什么,这种方法就是随机探测。
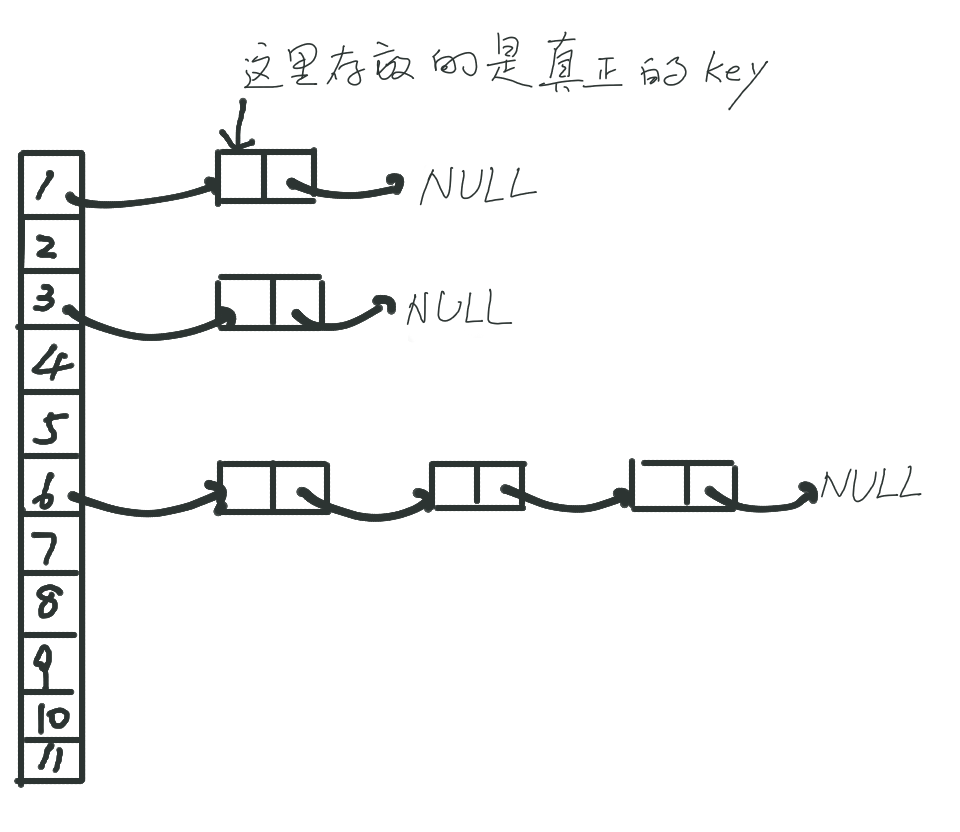
这样做的好处,其实显而易见,相比开地址法,这种挂链表的方式虽然更加繁琐,需要添加链表的操作,但也更加稳妥,效率较为稳定,各个地址间不会相互干扰,删除也十分方便。
块状链表我们第一节就有提到,块状链表能大大提升随机访问速度,是链表和线性表的混合产物,hash桶就是这种块状实现,用一个节点中放入几条记录的方式,就能处理有限条冲突,如果冲突实在太多,再想后面挂链表节点,再开空间。
由于hash表设计的好时,冲突本身就不多,那么hash桶实际上是一种高效优雅的解决方案。
但由于有些情况,我们不知道hash表要存储的数据最大量,所以我们需要一种更灵活的方式来处理。
当我们发现hash表空间不够时,那么我们就将hash表增大一倍,方法同线性表,然后新进入的元素映射到新的空间,如果再不够,再将表扩大一倍,然后将元素映射到新空间。
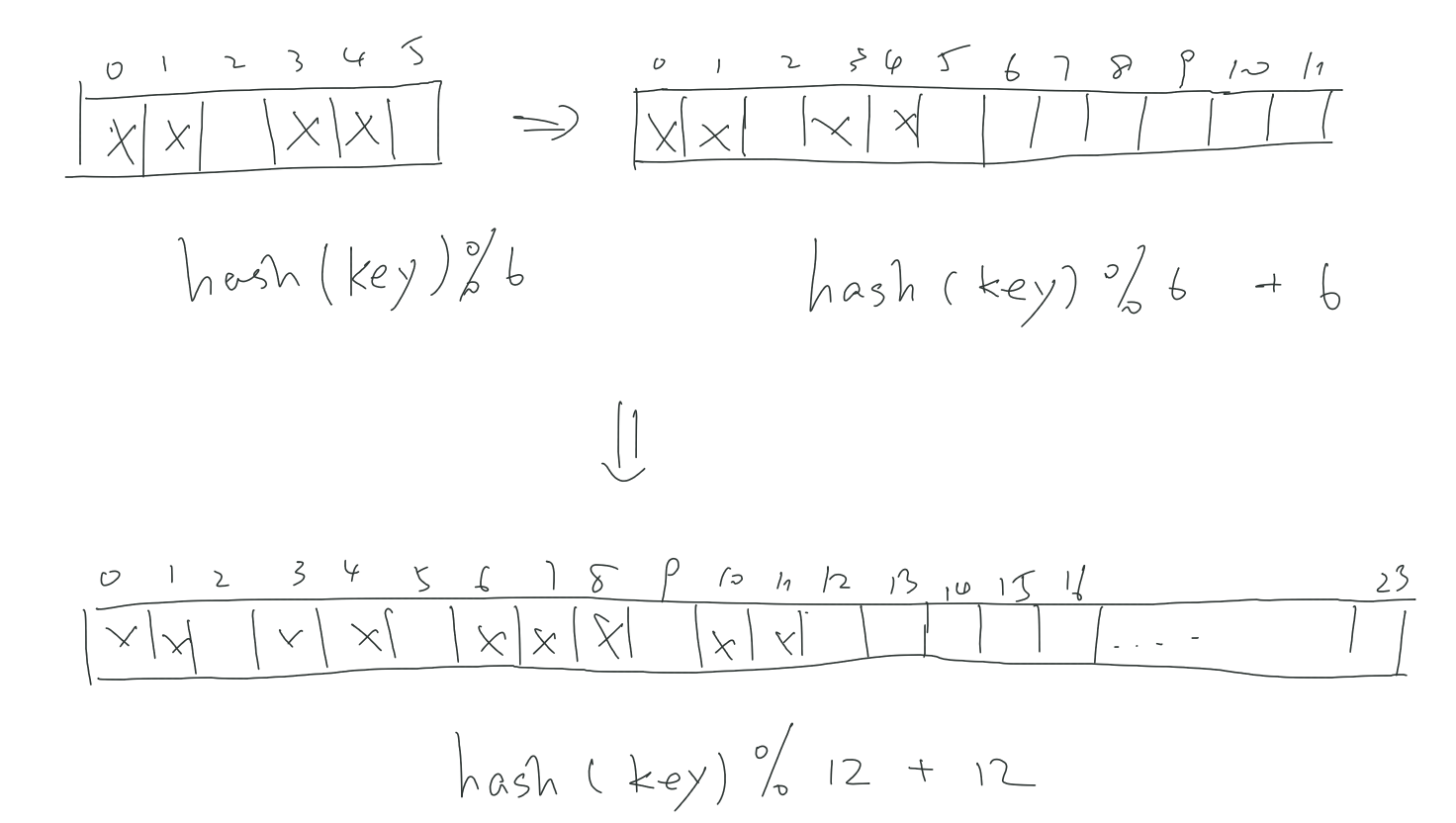
查找时,先找最新的空间有没有,如果没找到,再递归往左半边找,期间不断变化对应的hash函数即可。
注意一点,插入时,不能直接插入,需要先向左半边查找,确认元素不存在时,再插入右半边。
今天制作的这份教程十分重要,是我们高中时必会,而且是计算机体系中占有关键地位的一种数据结构——hash表。
要说hash表为何常用,为何厉害,那么我们先来考虑一个问题。
为什么说hash算法重要
计算机中,经常用到很多数学模型,例如,线性表 就是一种非常常用的数学模型,这里,不是在说他的数据结构,而是说,线性存储的这种方式,在很多情况下都用的到。而另外一种重要的模型,就是 key-value键值对 模型,hash算法,重在构建一个高效的key-value模型。例如,我们有很多网页要浏览,而刚刚浏览过的网页再次打开,一般会快很多,因为浏览器帮我们做了缓存,然而我们细想,如何缓存呢?我们怎么才能知道这个网页我们刚刚访问过么?
那么我们可以建立一个key-value的模型,如果刚刚访问过,我们就将网页内容存放到value处,而key就存放网页的url。
例如我们的手机应用,希望快速的查找一个联系人的相关信息,那么遍历所有人员恐怕不是一个好想法,而用key-value模型根据名字索引找到则更方便。
hash算法除了可以构建key-value模型,更可以作为数据校验和数据加密的重要算法。
hash函数是一种单向不可逆函数,MD5是流行的数据校验用hash算法,下载下来的数据是否和网络上的一致,用hash计算一下结果,然后比较网络上的hash值和本地计算的hash值,一致的话就说明数据不存在异常。
sha系列hash算法,在网站密码的加密上有着重要的作用。一般开发网站的朋友都了解,网站用户的密码是不能明文保存的,因为万一数据泄露后,会对用户隐私造成重大威胁。那么用什么来判断密码是否正确呢?将hash后的密码作为值存储起来,判断密码正确前,也将用户的输入hash一次,这样就可以在不知道用户密码的前提下,判断是否为同一用户。
详解hash表
hash表又称散列表,这个名字就是在说,要将数据分散开存放到一些位置上。一般我们有一个很大的名字空间,例如,200位的英文字母组成的字符串,当然,我们不会全部使用,名字太多了,所以我们使用的,只会是其中的一小部分。同时,每一个名字还对应一条数据,往往名字只是标示,而其中的数据,才是我们最关注的。而我们需要的是,尽快根据一个名字索引到对应的数据。有人说,简单啊,排序一下,然后根据二分查找的思想,对应判断就可以了。没错,二分查找是一种好思想,但也不是完全没有问题,如果我们的系统是动态的话,就很困难了,先存入两个数据,再删除一条,如果真想按照刚才的思想做,就必须做一棵高效平衡二叉树,普通的排序树有风险,可能退化的。而这样就太复杂了,hash表则提供了一种快速简单的思路,实现这个效果。
简单的链地址法的hash表:
hash表的结构其实很简单,就是一个较大的线性表,然后你去将key用一个函数计算一下,让结果分布到整个线性表中。由于hash函数一般都没有什么实际含义,一般希望 分布均匀,具有雪崩效应 (输入变化小,输出变化大),这样的映射函数就比较好了。
字符串hash——Times33
hash算法的基础算法之一,将字符串作为索引,存储key-value型数据。而在字符串hash中, Times33 算法是一种著名的算法。
算法很简单,就是在不断的×33
int hash(String str)
{
int hash_ans = 0;
for (int i = 0; i< str.length; ++i)
hash_ans = hash_ans*33 + str[i];
return hash_ans;
}一般来说,这个算法并没有什么特别深的理论依据,主要是经验性质的判断,对小心英文序列,33这个系数比较合适,对于大小写混合的,65比较好,还有使用31和131作为系数的版本,也都比较常见。
字符串hash——ELFhash算法
这是另外一种流行的hash算法,转自网友 阳光四季 的博文:http://blog.csdn.net/zhccl/article/details/7826137/// ELF Hash Function
unsigned int ELFHash(char *str)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);//hash左移4位,把当前字符ASCII存入hash低四位。
if ((x = hash & 0xF0000000L) != 0)
{
//如果最高的四位不为0,则说明字符多余7个,现在正在存第7个字符,如果不处理,再加下一个字符时,第一个字符会被移出,因此要有如下处理。
//该处理,如果最高位为0,就会仅仅影响5-8位,否则会影响5-31位,因为C语言使用的算数移位
//因为1-4位刚刚存储了新加入到字符,所以不能>>28
hash ^= (x >> 24);
//上面这行代码并不会对X有影响,本身X和hash的高4位相同,下面这行代码&~即对28-31(高4位)位清零。
hash &= ~x;
}
}
//返回一个符号位为0的数,即丢弃最高位,以免函数外产生影响。(我们可以考虑,如果只有字符,符号位不可能为负)
return (hash & 0x7FFFFFFF);
}hash几乎都会有冲突
除了放少量几个元素外,大部分哈希函数都不能保障,两个不一样的输入,得出相同的hash值,虽然这个概率很小,但毕竟名称空间很大,难免冲突。所以hash表重要的一环就是冲突的解决。
开地址法
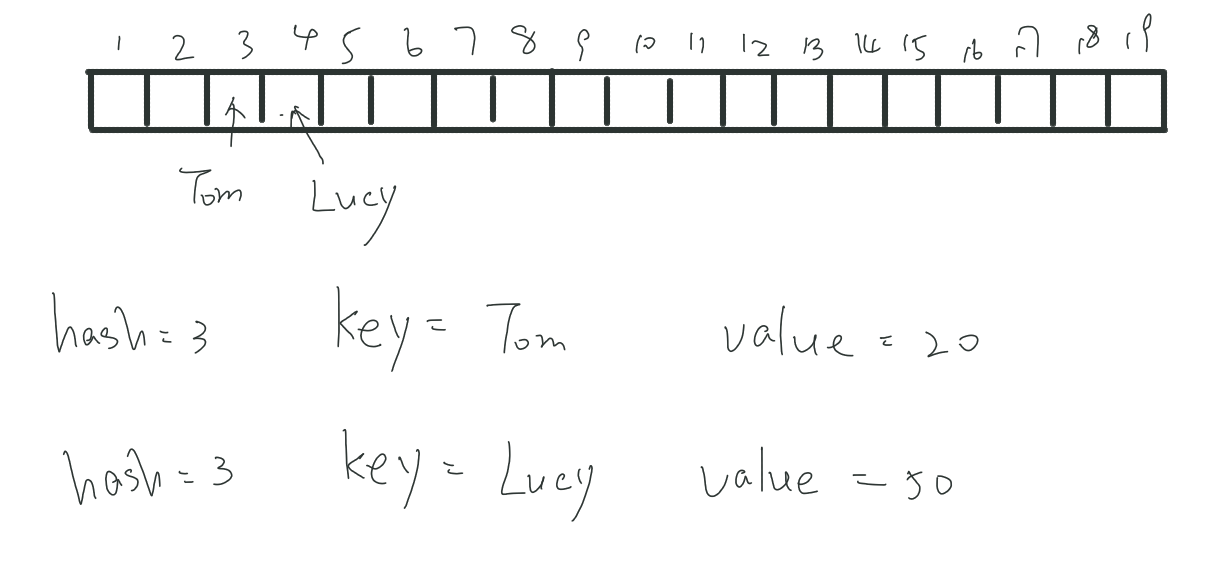
这个方法是一种非常简单的方法,例如下面这个例子,Tom和Lucy两个字符串经过hash后(这里只是假设)冲突了,他们的hash值恰好都是3,那么开地址法怎么做呢?先存放的就先占上这个位置,后放的Lucy发现没地方了,就一直往后找,找的第一个空位,就坐下了,占上了4这个位置。注意一点,开地址法也必须要把原来的key存放起来。如果又有一个hash为4的元素来了怎么办?继续后移啊,要是到了末尾还没发现空位,就再回到头开始找,但如果找了一圈都没发现空位,那么说明表满了。
查找时,算出对应的位置,然后从这个位置一直往后找,直到找到这个元素为止,或者碰到空停下,或者全满时绕了一圈发现没有。
这种方法虽然简单,但效率确实不高,在不存在删除的情况下还比较好,但如果存在删除的情况时,那删除时,就必须向后找到最后一个对应元素,然后将其挪到当前位置上,否则,这个寻找的链就因为删除时的空断开了。
这个方法被成为 开地址法 ,也叫 线性探测法。
新地址:Hn=(H+1)
H是当前地址, Hn是下一次要探测的新地址
开地址法的改进——二次探测法和随机探测法
由于开地址法存在一种情况,就是本来没冲突的两个元素,有可能碰撞在一起,这种情况叫做 堆积 。为了避免堆积情况的产生,有人采用了这样的算法,往后找平方序列个元素,并且是往后找一次,往前找一次,跳跃检测的步数序列是这样的:1, -1, 4, -4, 9, -9……新地址:Hn=(Hkey+d) d=1, -1, 4, -4, 9, -9……
这样往后看一下,往前看一下,再往后,再往前,确实要比线下查找分布均匀一些,但计算依旧比较复杂。
随机探测法,就是说这的d序列,是一个随机序列,虽说是随机序列,但这随机序列的种子我们是知道的,所以可以确定好这个hash表中所使用的序列是什么,这种方法就是随机探测。
链地址法
这也是最简单的方法之一,也很常用,如果有冲突,那么就在这个位置挂一个链表,一直顺着节点往下找。当然,这个链表查找时的复杂度就是线性的了。注意一点,链表中节点的头存放的都是原来的key值,用来判断是否为同一元素用的。这样做的好处,其实显而易见,相比开地址法,这种挂链表的方式虽然更加繁琐,需要添加链表的操作,但也更加稳妥,效率较为稳定,各个地址间不会相互干扰,删除也十分方便。
hash桶
链表最大的问题可能在于随机访问速度较慢,如果想优化一下,那么可以使用类似块状链表的思路来实现。块状链表我们第一节就有提到,块状链表能大大提升随机访问速度,是链表和线性表的混合产物,hash桶就是这种块状实现,用一个节点中放入几条记录的方式,就能处理有限条冲突,如果冲突实在太多,再想后面挂链表节点,再开空间。
由于hash表设计的好时,冲突本身就不多,那么hash桶实际上是一种高效优雅的解决方案。
可扩展hash表
一般情况,hash表的大小要开最大数据量的两倍左右,这样才能尽量避免冲突。但由于有些情况,我们不知道hash表要存储的数据最大量,所以我们需要一种更灵活的方式来处理。
当我们发现hash表空间不够时,那么我们就将hash表增大一倍,方法同线性表,然后新进入的元素映射到新的空间,如果再不够,再将表扩大一倍,然后将元素映射到新空间。
查找时,先找最新的空间有没有,如果没找到,再递归往左半边找,期间不断变化对应的hash函数即可。
注意一点,插入时,不能直接插入,需要先向左半边查找,确认元素不存在时,再插入右半边。

相关文章推荐
- c语言实现hashmap(转载)
- Lua教程(七):数据结构详解
- Ruby中Hash的11个问题解答
- 解析从源码分析常见的基于Array的数据结构动态扩容机制的详解
- C#数据结构揭秘一
- Ruby简明教程之数组和Hash介绍
- 数据结构之Treap详解
- 在C#中生成与PHP一样的MD5 Hash Code的方法
- js中hash和ico的关联分析
- JavaScript数据结构和算法之图和图算法
- Javascript SHA-1:Secure Hash Algorithm
- Java数据结构及算法实例:冒泡排序 Bubble Sort
- 理解php Hash函数,增强密码安全
- Java数据结构及算法实例:插入排序 Insertion Sort
- Java数据结构及算法实例:考拉兹猜想 Collatz Conjecture
- java数据结构之java实现栈
- java数据结构之实现双向链表的示例
- Java数据结构及算法实例:选择排序 Selection Sort
- Java数据结构及算法实例:朴素字符匹配 Brute Force
- Java数据结构及算法实例:汉诺塔问题 Hanoi