UVALive 3026 Period (KMP算法简介)
2015-09-09 15:57
387 查看
kmp的代码很短,但是不太容易理解,还是先说明一下这个算法过程吧。
朴素的字符串匹配大家都懂,但是效率不高,原因在哪里?
匹配过程没有充分利用已经匹配好的模版的信息,比如说,
i是文本串当前字符的下标,j是要匹配的模版串当前正在匹配的字符的下标。(下标都从零开始,j同时可以表示已经匹配的字符长度)
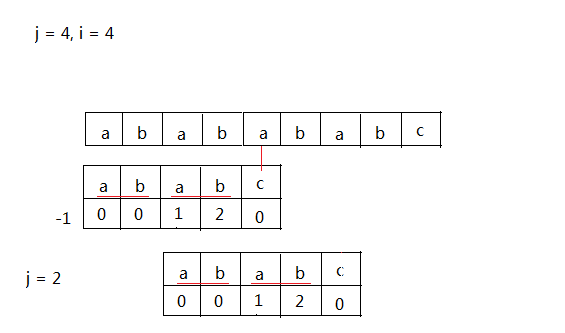
当匹配到i = 4, j = 4的时候失配了,朴素的匹配做法是往右边移一位然后从j开始扫,这样做效率很低。
不难发现前面已经匹配好的串ab是最长公共前缀后缀。把串移动到后缀的第一个位置正好是
朴素的匹配过程中第一次匹配能把这个前缀匹配匹配完的位置!因此令j = f[j-1] = 2。
模版串下面这个f数组又是怎么来的呢?
寻找最长公共前缀后缀过程本质上也是一个匹配。
i表示当前要求f[i]的下标,j表示之前串已经匹配的最大前缀后缀长度。(j = -1表示0号位置也没有匹配上)
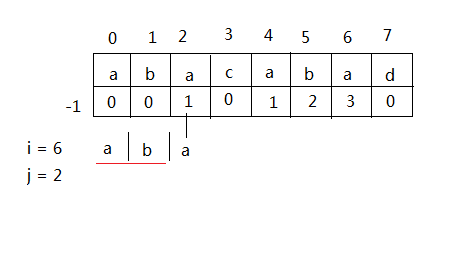
当i = 6时,之前已经匹配了j个,所以只要i只要从j下标位置开始比较就行了。当匹配的时候f[i] = j+1。
如果不匹配,利用前面已经得到的f值进行匹配。
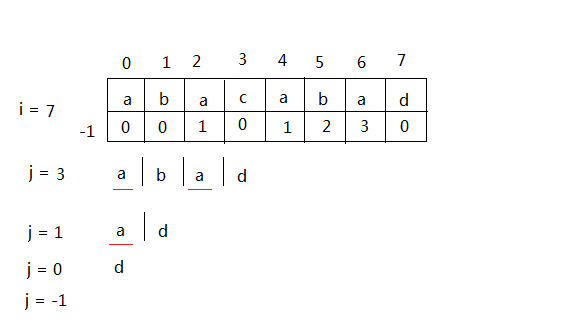
当i = 7, j = 3时,发生失配,利用之前的f值,可以知道a是最长的前缀和后缀,那么只需要从a开始匹配,因此令j = f[j-1],
重复上述过程直到匹配或j = -1的时候为止。当前就等于: f[i] = j+1。(j=-1表示没有匹配也是为了方便统一处理)
在代码中,因为当j = 0的时候,j = f[j-1]不好表示,因此把整个f数组向右边移动一位。此时只需把上述过程的j = f[j-1]替换成j = f[j]。
----------------------------------------------分割线----------------------------------------------------------------
这道题要求前缀的最小循环周期。
先构造一个循环的串,然后进行求失配函数f的过程,当第一次前缀长度等于后缀长度并且各占一半的时候,这个前缀一定是最小的循环节。(从第一个结论开始用归纳法证明)
可以归纳出一个结论:在每个循环节终止的位置 i-f[i] ==最短循环节长度。
反过来i能被(i-f[i])整除可以推出i-f[i]是最短循环节。(同样用归纳法)
kmp之前不太理解,只会套。为学习ac自动机,先把的kmp基础打好。
朴素的字符串匹配大家都懂,但是效率不高,原因在哪里?
匹配过程没有充分利用已经匹配好的模版的信息,比如说,
i是文本串当前字符的下标,j是要匹配的模版串当前正在匹配的字符的下标。(下标都从零开始,j同时可以表示已经匹配的字符长度)
当匹配到i = 4, j = 4的时候失配了,朴素的匹配做法是往右边移一位然后从j开始扫,这样做效率很低。
不难发现前面已经匹配好的串ab是最长公共前缀后缀。把串移动到后缀的第一个位置正好是
朴素的匹配过程中第一次匹配能把这个前缀匹配匹配完的位置!因此令j = f[j-1] = 2。
模版串下面这个f数组又是怎么来的呢?
寻找最长公共前缀后缀过程本质上也是一个匹配。
i表示当前要求f[i]的下标,j表示之前串已经匹配的最大前缀后缀长度。(j = -1表示0号位置也没有匹配上)
当i = 6时,之前已经匹配了j个,所以只要i只要从j下标位置开始比较就行了。当匹配的时候f[i] = j+1。
如果不匹配,利用前面已经得到的f值进行匹配。
当i = 7, j = 3时,发生失配,利用之前的f值,可以知道a是最长的前缀和后缀,那么只需要从a开始匹配,因此令j = f[j-1],
重复上述过程直到匹配或j = -1的时候为止。当前就等于: f[i] = j+1。(j=-1表示没有匹配也是为了方便统一处理)
在代码中,因为当j = 0的时候,j = f[j-1]不好表示,因此把整个f数组向右边移动一位。此时只需把上述过程的j = f[j-1]替换成j = f[j]。
----------------------------------------------分割线----------------------------------------------------------------
这道题要求前缀的最小循环周期。
先构造一个循环的串,然后进行求失配函数f的过程,当第一次前缀长度等于后缀长度并且各占一半的时候,这个前缀一定是最小的循环节。(从第一个结论开始用归纳法证明)
可以归纳出一个结论:在每个循环节终止的位置 i-f[i] ==最短循环节长度。
反过来i能被(i-f[i])整除可以推出i-f[i]是最短循环节。(同样用归纳法)
kmp之前不太理解,只会套。为学习ac自动机,先把的kmp基础打好。
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1e6+5;
int f[maxn];
char str[maxn];
void getF(char *s)
{
f[0] = -1;
for(int i = 0, j = -1; s[i]; ){
while(~j && s[i] != s[j]) j = f[j];
f[++i] = ++j;
}
}
int main()
{
//freopen("in.txt","r",stdin);
int n,kas = 0;
while(scanf("%d\n",&n),n){
gets(str);
getF(str);
printf("Test case #%d\n",++kas);
for(int i = 2; i <= n; i++){
if(f[i] && i%(i-f[i]) == 0)
printf("%d %d\n",i,i/(i-f[i]));
}
putchar('\n');
}
return 0;
}

相关文章推荐
- iOS-Quart2D 进度条
- Unity 游戏开发技巧集锦之使用忍者飞镖创建粒子效果
- 三次握手各字符含义以及四次挥手
- 学习笔记 程序包管理
- lucene高亮器——lucene-highlighter-2.4.0.jar下载
- waitbar
- sphinx setOverride 思考
- HDU 5033 Building
- jQuery基础
- busybox 安装方法
- Eclipse中Java项目打包——外部jar包位置 ,生成jar包位置,mf文件书写等问题
- 多线程下载
- express 框架之session (cookie和session介绍)
- jvm 学习
- iOS手势学习
- 修改easyui日期控件只显示年月,并且只能选择年月
- 人件札记:聚餐活动
- LeetCode:Reverse Integer
- TabHost 选项卡
- Win10电脑装机必备的5款软件