常见排序算法整理
2015-09-04 16:44
375 查看
一 堆排序
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆。
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R
交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R
;
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到

然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:



20和16交换后导致16不满足堆的性质,因此需重新调整

这样就得到了初始堆。
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。

此时3位于堆顶不满堆的性质,则需调整继续调整










这样整个区间便已经有序了。
从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
二 归并排序:
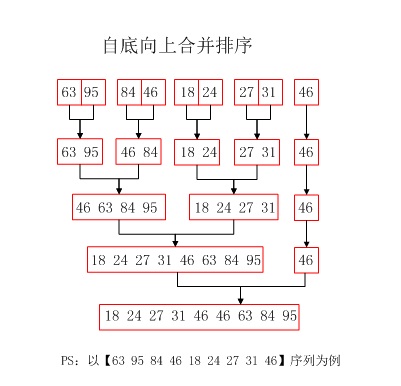
自底向上的归并排序:归并排序主要是完成将若干个有序子序列合并成一个完整的有序子序列;自底向上的排序是归并排序的一种实现方式,将一个无序的N长数组切个成N个有序子序列,然后再两两合并,然后再将合并后的N/2(或者N/2 + 1)个子序列继续进行两两合并,以此类推得到一个完整的有序数组。下图详细的分解了自底向上的合并算法的实现过程:
平均时间复杂度:O(nlog2n)
空间复杂度:O(n) (用于存储有序子序列合并后有序序列)
稳定性:稳定
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆。
1.堆
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2]
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
2.堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R
交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R
;
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
操作过程如下:
1)初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
20和16交换后导致16不满足堆的性质,因此需重新调整
这样就得到了初始堆。
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。
此时3位于堆顶不满堆的性质,则需调整继续调整
这样整个区间便已经有序了。
从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
/*堆排序(大顶堆) 2011.9.14*/
#include <iostream>
#include<algorithm>
using namespace std;
void HeapAdjust(int *a,int i,int size) //调整堆
{
int lchild=2*i; //i的左孩子节点序号
int rchild=2*i+1; //i的右孩子节点序号
int max=i; //临时变量
if(i<=size/2) //如果i是叶节点就不用进行调整
{
if(lchild<=size&&a[lchild]>a[max])
{
max=lchild;
}
if(rchild<=size&&a[rchild]>a[max])
{
max=rchild;
}
if(max!=i)
{
swap(a[i],a[max]);
HeapAdjust(a,max,size); //避免调整之后以max为父节点的子树不是堆
}
}
}
void BuildHeap(int *a,int size) //建立堆
{
int i;
for(i=size/2;i>=1;i--) //非叶节点最大序号值为size/2
{
HeapAdjust(a,i,size);
}
}
void HeapSort(int *a,int size) //堆排序
{
int i;
BuildHeap(a,size);
for(i=size;i>=1;i--)
{
//cout<<a[1]<<" ";
swap(a[1],a[i]); //交换堆顶和最后一个元素,即每次将剩余元素中的最大者放到最后面
//BuildHeap(a,i-1); //将余下元素重新建立为大顶堆
HeapAdjust(a,1,i-1); //重新调整堆顶节点成为大顶堆
}
}
int main(int argc, char *argv[])
{
//int a[]={0,16,20,3,11,17,8};
int a[100];
int size;
while(scanf("%d",&size)==1&&size>0)
{
int i;
for(i=1;i<=size;i++)
cin>>a[i];
HeapSort(a,size);
for(i=1;i<=size;i++)
cout<<a[i]<<"";
cout<<endl;
}
return 0;
}转自:堆排序二 归并排序:
一. 算法描述
自底向上的归并排序:归并排序主要是完成将若干个有序子序列合并成一个完整的有序子序列;自底向上的排序是归并排序的一种实现方式,将一个无序的N长数组切个成N个有序子序列,然后再两两合并,然后再将合并后的N/2(或者N/2 + 1)个子序列继续进行两两合并,以此类推得到一个完整的有序数组。下图详细的分解了自底向上的合并算法的实现过程:
二. 算法分析
平均时间复杂度:O(nlog2n)空间复杂度:O(n) (用于存储有序子序列合并后有序序列)
稳定性:稳定
/********************************************************
*函数名称:Merge
*参数说明:pDataArray 无序数组;
* int *pTempArray 临时存储合并后的序列
* bIndex 需要合并的序列1的起始位置
* mIndex 需要合并的序列1的结束位置
并且作为序列2的起始位置
* eIndex 需要合并的序列2的结束位置
*说明: 将数组中连续的两个子序列合并为一个有序序列
*********************************************************/
void Merge(int* pDataArray, int *pTempArray, int bIndex, int mIndex, int eIndex)
{
int mLength = eIndex - bIndex; //合并后的序列长度
int i = 0; //记录合并后序列插入数据的偏移
int j = bIndex; //记录子序列1插入数据的偏移
int k = mIndex; //记录子序列2掺入数据的偏移
while (j < mIndex && k < eIndex)
{
if (pDataArray[j] <= pDataArray[k])
{
pTempArray[i++] = pDataArray[j];
j++;
}
else
{
pTempArray[i++] = pDataArray[k];
k++;
}
}
if (j == mIndex) //说明序列1已经插入完毕
while (k < eIndex)
pTempArray[i++] = pDataArray[k++];
else //说明序列2已经插入完毕
while (j < mIndex)
pTempArray[i++] = pDataArray[j++];
for (i = 0; i < mLength; i++) //将合并后序列重新放入pDataArray
pDataArray[bIndex + i] = pTempArray[i];
}
/********************************************************
*函数名称:BottomUpMergeSort
*参数说明:pDataArray 无序数组;
* iDataNum为无序数据个数
*说明: 自底向上的归并排序
*********************************************************/
void BottomUpMergeSort(int* pDataArray, int iDataNum)
{
int *pTempArray = (int *)malloc(sizeof(int) * iDataNum); //临时存放合并后的序列
int length = 1; //初始有序子序列长度为1
while (length < iDataNum)
{
int i = 0;
for (; i + 2*length < iDataNum; i += 2*length)
Merge(pDataArray, pTempArray, i, i + length, i + 2*length);
if (i + length < iDataNum)
Merge(pDataArray, pTempArray, i, i + length, iDataNum);
length *= 2; //有序子序列长度*2
}
free(pTempArray);
}

相关文章推荐
- Zigbee协议栈内核分析 – 串口分析
- Mayor's posters(线段树+离散化POJ2528)
- win8右下角的输入法宽度变化的问题
- 合并多个DataTable及将DataTable添加到DataSet的方法
- 【英语】Bingo口语笔记(65) - 我也是系列
- 安装wget
- Mayor's posters(线段树+离散化POJ2528)
- [HDOJ5360]Hiking
- Struts2 part6:数据校验
- Linux之grub的运行机制及grub修复
- C++基础---无返回值函数(void函数)
- 家里接双线方法,带宽和网速都提高
- 网线接错,也可以上网,老断线
- 我是懒人
- usaco Longest Prefix
- Wget下载终极用法和15个详细的例子
- Largest Number —— Leetcode(sort的妙用)
- [网络流24题] 21 最长k可重区间集(最大权不相交路径 ,最小费用最大流)
- 28. 原型
- VMware CentOS Device eth0 does not seem to be present