可视化自编码器训练结果
2015-09-04 12:00
218 查看
navigation,
search
训练完(稀疏)自编码器,我们还想把这自编码器学到的函数可视化出来,好弄明白它到底学到了什么。我们以在10×10图像(即n=100)上训练自编码器为例。在该自编码器中,每个隐藏单元i对如下关于输入的函数进行计算:
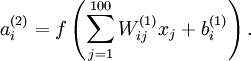
我们将要可视化的函数,就是上面这个以2D图像为输入、并由隐藏单元i计算出来的函数。它是依赖于参数
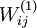
的(暂时忽略偏置项bi)。需要注意的是,
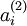
可看作输入

的非线性特征。不过还有个问题:什么样的输入图像
可让
得到最大程度的激励?(通俗一点说,隐藏单元

要找个什么样的特征?)。这里我们必须给
加约束,否则会得到平凡解。若假设输入有范数约束
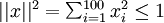
,则可证(请读者自行推导)令隐藏单元
得到最大激励的输入应由下面公式计算的像素
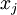
给出(共需计算100个像素,j=1,…,100):
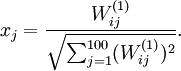
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们面前之时,隐藏单元
所追寻特征的真正含义也渐渐明朗起来。
假如我们训练的自编码器有100个隐藏单元,可视化结果就会包含100幅这样的图像——每个隐藏单元都对应一幅图像。审视这100幅图像,我们可以试着体会这些隐藏单元学出来的整体效果是什么样的。
当我们对稀疏自编码器(100个隐藏单元,在10X10像素的输入上训练 )进行上述可视化处理之后,结果如下所示:


上图的每个小方块都给出了一个(带有有界范数 的)输入图像
,它可使这100个隐藏单元中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。
显而易见,这些特征对物体识别等计算机视觉任务是十分有用的。若将其用于其他输入域(如音频),该算法也可学到对这些输入域有用的表示或特征。
可视化自编码器训练结果
From Ufldl
Jump to:navigation,
search
训练完(稀疏)自编码器,我们还想把这自编码器学到的函数可视化出来,好弄明白它到底学到了什么。我们以在10×10图像(即n=100)上训练自编码器为例。在该自编码器中,每个隐藏单元i对如下关于输入的函数进行计算:
我们将要可视化的函数,就是上面这个以2D图像为输入、并由隐藏单元i计算出来的函数。它是依赖于参数
的(暂时忽略偏置项bi)。需要注意的是,
可看作输入
的非线性特征。不过还有个问题:什么样的输入图像
可让
得到最大程度的激励?(通俗一点说,隐藏单元
要找个什么样的特征?)。这里我们必须给
加约束,否则会得到平凡解。若假设输入有范数约束
,则可证(请读者自行推导)令隐藏单元
得到最大激励的输入应由下面公式计算的像素
给出(共需计算100个像素,j=1,…,100):
当我们用上式算出各像素的值、把它们组成一幅图像、并将图像呈现在我们面前之时,隐藏单元
所追寻特征的真正含义也渐渐明朗起来。
假如我们训练的自编码器有100个隐藏单元,可视化结果就会包含100幅这样的图像——每个隐藏单元都对应一幅图像。审视这100幅图像,我们可以试着体会这些隐藏单元学出来的整体效果是什么样的。
当我们对稀疏自编码器(100个隐藏单元,在10X10像素的输入上训练 )进行上述可视化处理之后,结果如下所示:

上图的每个小方块都给出了一个(带有有界范数 的)输入图像
,它可使这100个隐藏单元中的某一个获得最大激励。我们可以看到,不同的隐藏单元学会了在图像的不同位置和方向进行边缘检测。
显而易见,这些特征对物体识别等计算机视觉任务是十分有用的。若将其用于其他输入域(如音频),该算法也可学到对这些输入域有用的表示或特征。

相关文章推荐
- 瑶瑶带你玩激光坦克(暴力)
- char* 和char[]的区别
- C++模板学习之栈的实现
- 自编码算法与稀疏性
- UIday0801:UINavigationController视图控制器的属性和用法
- Java Excel API简介
- c++模版元编程
- css经验总结
- window下php5.6-x64-ts可用php_redis.dll文件
- 关于ArcGIS的疑惑--只支持ArcGIS Desktop的接口
- 2087 剪花布条【kmp】
- JSP-- cookies
- java IO流 ObjectStream PipedStream 随机访问文件 字符编码--21
- 数值运算
- c语言指针与数组
- CentOS 7 挂载本地光盘作为镜像源
- 学习日志---非递归二叉树游标遍历(前中后层序)
- 1043. Is It a Binary Search Tree (25)
- 截取字符串
- hadoop学习之路——12、win7下eclipse连接hadoop测试环境