HMM学习最佳范例四:隐马尔科夫模型
2015-09-01 16:12
288 查看
HMM学习最佳范例四:隐马尔科夫模型
发表于 2009年06月23号 由 52nlp四、隐马尔科夫模型(Hidden Markov Models)
1、定义(Definition of a hidden Markov model)
一个隐马尔科夫模型是一个三元组(pi, A, B)。
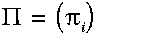
:初始化概率向量;
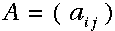
:状态转移矩阵;
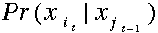
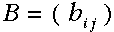
:混淆矩阵;
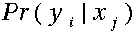
在状态转移矩阵及混淆矩阵中的每一个概率都是时间无关的——也就是说,当系统演化时这些矩阵并不随时间改变。实际上,这是马尔科夫模型关于真实世界最不现实的一个假设。
2、应用(Uses associated with HMMs)
一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态序列(解码)。第三个问题是给定观察序列生成一个HMM(学习)。
a) 评估(Evaluation)
考虑这样的问题,我们有一些描述不同系统的隐马尔科夫模型(也就是一些( pi,A,B)三元组的集合)及一个观察序列。我们想知道哪一个HMM最有可能产生了这个给定的观察序列。例如,对于海藻来说,我们也许会有一个“夏季”模型和一个“冬季”模型,因为不同季节之间的情况是不同的——我们也许想根据海藻湿度的观察序列来确定当前的季节。
我们使用前向算法(forward algorithm)来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率,并因此选择最合适的隐马尔科夫模型(HMM)。
在语音识别中这种类型的问题发生在当一大堆数目的马尔科夫模型被使用,并且每一个模型都对一个特殊的单词进行建模时。一个观察序列从一个发音单词中形成,并且通过寻找对于此观察序列最有可能的隐马尔科夫模型(HMM)识别这个单词。
b) 解码( Decoding)
给定观察序列搜索最可能的隐藏状态序列。
另一个相关问题,也是最感兴趣的一个,就是搜索生成输出序列的隐藏状态序列。在许多情况下我们对于模型中的隐藏状态更感兴趣,因为它们代表了一些更有价值的东西,而这些东西通常不能直接观察到。
考虑海藻和天气这个例子,一个盲人隐士只能感觉到海藻的状态,但是他更想知道天气的情况,天气状态在这里就是隐藏状态。
我们使用Viterbi 算法(Viterbi algorithm)确定(搜索)已知观察序列及HMM下最可能的隐藏状态序列。
Viterbi算法(Viterbi algorithm)的另一广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标注。
C)学习(Learning)
根据观察序列生成隐马尔科夫模型。
第三个问题,也是与HMM相关的问题中最难的,根据一个观察序列(来自于已知的集合),以及与其有关的一个隐藏状态集,估计一个最合适的隐马尔科夫模型(HMM),也就是确定对已知序列描述的最合适的(pi,A,B)三元组。
当矩阵A和B不能够直接被(估计)测量时,前向-后向算法(forward-backward algorithm)被用来进行学习(参数估计),这也是实际应用中常见的情况。
3、总结(Summary)
由一个向量和两个矩阵(pi,A,B)描述的隐马尔科夫模型对于实际系统有着巨大的价值,虽然经常只是一种近似,但它们却是经得起分析的。隐马尔科夫模型通常解决的问题包括:
1. 对于一个观察序列匹配最可能的系统——评估,使用前向算法(forward algorithm)解决;
2. 对于已生成的一个观察序列,确定最可能的隐藏状态序列——解码,使用Viterbi 算法(Viterbi algorithm)解决;
3. 对于已生成的观察序列,决定最可能的模型参数——学习,使用前向-后向算法(forward-backward algorithm)解决。
未完待续:前向算法1
本文翻译自:http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/html_dev/main.html
部分翻译参考:隐马尔科夫模型HMM自学
转载请注明出处“我爱自然语言处理”:www.52nlp.cn
本文链接地址:http://www.52nlp.cn/hmm-learn-best-practices-four-hidden-markov-models
相关文章:
HMM学习最佳范例七:前向-后向算法2
HMM学习最佳范例七:前向-后向算法1
HMM学习最佳范例七:前向-后向算法4
HMM学习最佳范例六:维特比算法5
几种不同程序语言的HMM版本
HMM学习最佳范例七:前向-后向算法3
HMM学习最佳范例七:前向-后向算法5
HMM学习最佳范例六:维特比算法4
HMM在自然语言处理中的应用一:词性标注2
HMM学习最佳范例六:维特比算法2
此条目发表在 隐马尔科夫模型 分类目录,贴了 forward
algorithm, forward-backward algorithm, hmm, HMM学习, Viterbi
algorithm, 自然语言处理, 词性标注, 隐马尔科夫模型 标签。将固定链接加入收藏夹。

相关文章推荐
- MFC友好信息提示类
- DataView 对日期的筛选
- 从Office到Cortana,微软巨头在想什么?
- mysql错误: waiting for table metadata lock
- putty配置
- cocos2dx Auto-batching的使用
- LeetCode Distinct Subsequences DP
- 大四之前的最后思考
- 广播 注册和xml形式
- 汇编推荐书籍
- Ing_Redis
- 使用nginx-http-concat优化网站响应
- Ugly Number I 和 II LeetCode
- Android入门:广播发送者与广播接收者(同步广播和有序广播)
- UILabel圆角、边框、宽度自适应
- Linux RHCS 基础维护命令
- Windows批处理:自动开关程序
- iOS-Quartz2D绘图的基础用法总结
- 《播客》项目总结——项目管理方面
- phpStorm for mac 7.1.4注册码