Spring Framework 源码阅读
2015-08-20 11:02
696 查看
Spring Framework(下文简称为Spring)提供了很多功能,使得很多简单的应用开发,尤其是一些政府,小企业应用,变成Action->Service->DAO+一堆Interface(我讨厌很多莫名其妙的接口),just
make skins for dababase.
本文的画图工具:mindmanager原文地址:http://my.oschina.net/geecoodeer/blog/191815
当然,Spring 的框架实现还是很强大的,虽然里面没啥高深算法,但是的确使开发工作简便了不少(Joel曾说,OOP太简单了,不足以分辨出优秀的程序员… )。但是,对一个对未知事物充满好奇心的人来说,理解Spring的内部实现还是很有必要的。
本文主要分为2个章节,分别是IOC实现原理,AOP实现原理
注:本文不会太多涉及Spring Framework 源码内部实现框架细节,细节部分请阅读本文最后的参考章节。
====
引论
为什么需要IOC
对象之间的依赖关系本来应该是直接是通过在代码中,A类直接创建另外一个B类的实例,结果变成是在IOC容器中,通过配置文件来配置对象依赖关系。至于为什么需要IOC,网上的说法是主要是因为复杂对象之间的依赖关系通过IOC管理起来比较简单,不需要手写大量代码。其实,我更喜欢这几个理由,比如说
只要改配置文件,不需要改代码就完成对象依赖修改
提供方便的单例类
结合AOP,能够实现更强大的功能
Spring对很多常用功能,如jdbc,rmi,jms进行了一些封装,方便我们的使用。
由于Java语言的限制,以及Spring可以控制对象的整个生命周期,从而使框架的实现难度大大降低,框架的上手难度也大大降低。
====
如何描述对象的依赖关系
我们需要配置文件来保存对象的依赖关系。既然说到配置文件,那么就必须涉及到配置文件的解析,解析前需要校验文件合法性,解析后的内容再与相应的java类映射。
但是在开始解析文件之前,首先要搞清楚2个问题:
解析的文件在哪里,是指定的绝对路径还是相对路径还是classpath
文件的格式是什么,是xml还是properties,甚至是文本文件还是二进制文件。如果是xml,它相应的dtd或xsd是什么?
搞清楚上述问题后,我们再进行选择解析组件。就XML而言,简单的文件直接通过JAXB/Digester来解决;复杂的一般是使用SAX来解决,例如Spring和Activiti。
====
正文
解析配置文件
回到正题,从spring的单元测试中,找到这段代码: void org.springframework.beans.factory.xml.XmlBeanFactoryTests.testInitMethodIsInvoked() throws Exception
@Test
public void testInitMethodIsInvoked() throws Exception {
DefaultListableBeanFactory xbf = new DefaultListableBeanFactory();
new XmlBeanDefinitionReader(xbf).loadBeanDefinitions(INITIALIZERS_CONTEXT);
DoubleInitializer in = (DoubleInitializer) xbf.getBean("init-method1");
// Initializer should have doubled value
assertEquals(14, in.getNum());
}执行核心时序如下:
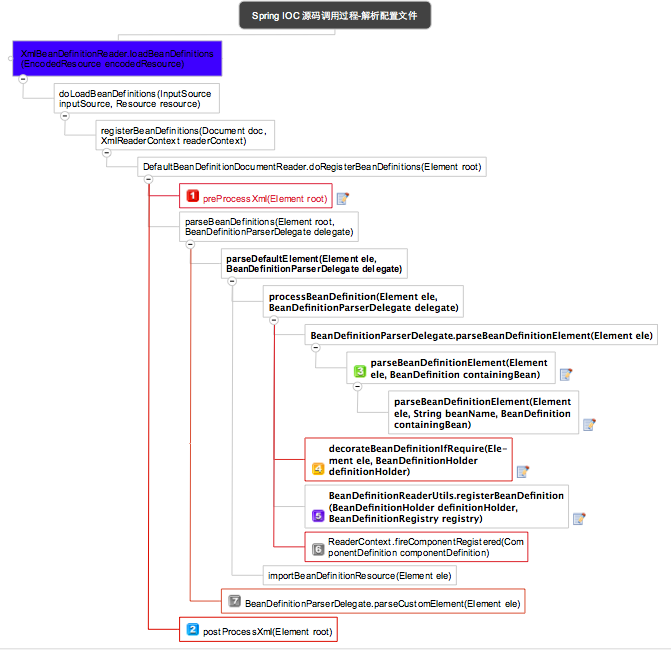
时序解释如下:
标记1,2,4,5,7 都是用于扩展框架功能.标记1,2支持解析bean定义前后前后做些处理;标记4,7主要是用来支持解析自定义标签,详细见 基于Spring可扩展Schema提供自定义配置支持;标记5用来支持当解析完成后,做一些事件触发
标记3主要完成解析bean的xml配置文件id,name以及其他所有属性
标记5主要完成将解析完成的bean放到ConcurrentHashMap中
====
获取bean
在单元测试中void org.springframework.context.support.ClassPathXmlApplicationContextTests.testSingleConfigLocation(),我们找到这段话
@Test
public void testSingleConfigLocation() {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(FQ_SIMPLE_CONTEXT);
assertTrue(ctx.containsBean("someMessageSource"));
ctx.close();
}执行核心时序如下:
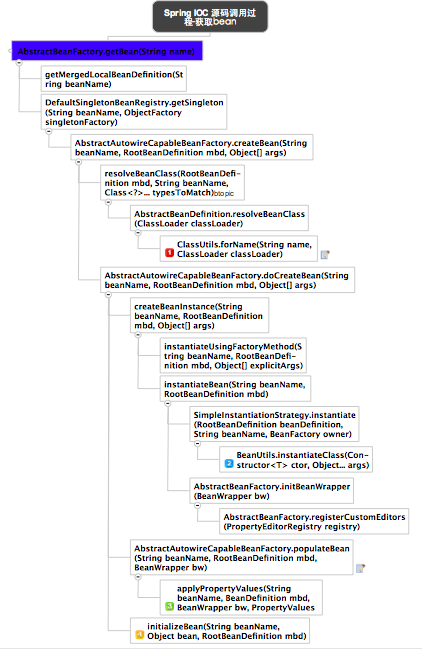
时序解释如下:
标记1获取bean的Class对象
标记2获取bean的实例
标记3对bean的属性进行赋值
====
AOP实现原理
引论
AOP完成了初学者一些看起来很神奇的功能,其实底层都是通过字节码增强的方式来透明地完成了一些Magic.AOP过于强大,以至于常有一些不适合的场景,比如用AOP进行打日志阅读本章之前需要了解一下几个概念:静态代理,JDK动态代理,字节码增强动态代理
====
获得代理类实例
配置文件如下:<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN 2.0//EN" "http://www.springframework.org/dtd/spring-beans-2.0.dtd"> <beans> <bean id="human" class="com.vavi.proxy.Person"> </bean> <bean id="sleepHelper" class="com.vavi.spring.aop.jdk.SleepAdvice"> </bean> <bean id="sleepPointcut" class="org.springframework.aop.support.JdkRegexpMethodPointcut"> <property name="pattern" value=".*sleep" /> </bean> <bean id="sleepHelperAdvisor" class="org.springframework.aop.support.DefaultPointcutAdvisor"> <property name="advice" ref="sleepHelper" /> <property name="pointcut" ref="sleepPointcut" /> </bean> <bean id="humanProxy" class="org.springframework.aop.framework.ProxyFactoryBean"> <property name="target" ref="human" /> <property name="interceptorNames" value="sleepHelperAdvisor" /> <property name="proxyInterfaces" value="com.vavi.proxy.Sleepable" /> </bean> </beans>
测试类代码如下:
public class SpringProxyTest {
public static void main(String[] args) {
ApplicationContext appCtx = new ClassPathXmlApplicationContext(
"applicationContext.xml");
Sleepable sleeper = (Sleepable) appCtx.getBean("humanProxy");
sleeper.sleep();
}
}核心时序如下:
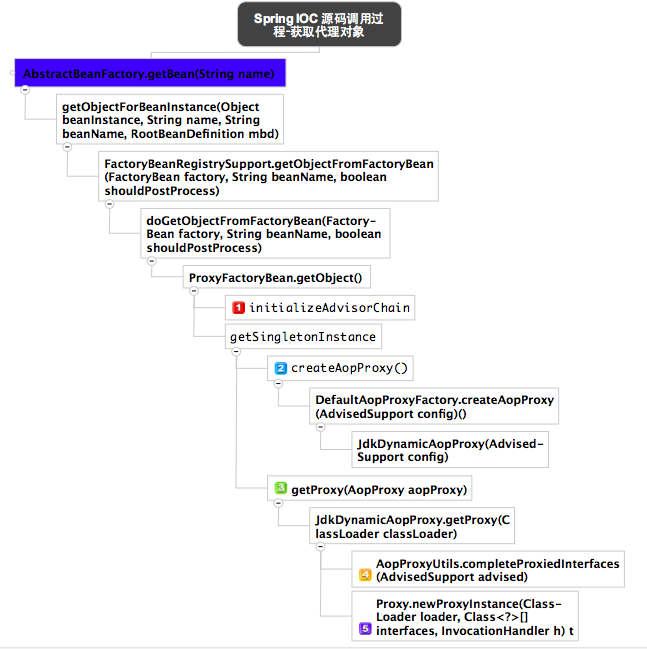
时序解释如下:
标记1表示初始化advisor链
标记2表示获取默认的JDK动态代理
标记4表示通过AopProxyUtils对代理类的接口的个数进行了增加,interface org.springframework.aop.SpringProxy, interface org.springframework.aop.framework.Advised
标记5表示通过JDK API完成代理类实例的创建
====
完成代理方法执行
核心时序如下: 
时序解释如下:
获得拦截器链,依次执行
里面有个比较好玩的计数器,用来实现拦截器调用;感兴趣的读者请自行翻源码吧.
====
总结
刚开始看源码时,其实不明白ApplicationContext和DefaultListableBeanFactory的区别,从源码的实现细节来看,ApplicationContext的内部实现是调用了DefaultListableBeanFactory的方法的,其他还做了一些增强;具体增强了哪些,目前还没有时间去一探究竟.sax解析,这个是体力活,但是xml解析命名实在比较操蛋;针对xml,有些必须知道的知识:namespace,xsd,dtd
Spring对象继承,接口实现层次较深,并不是很好。对于一般学习者来讲,尤其有些类的命名还不是很讲究,其实很难记住. 所以,不需要记住这些类的主要职责,还是记住它主要做些什么,对我们的日常开发有什么作用,如何扩展。
代码里面存在大量的不鼓励的instanceof,比如针对FactoryBean的特殊处理
BeanDefinition –> AbstractBeanDefinition ->GenericBeanDefinition 接口,抽象类,实现类,模板模式也经常看到
之所以不贴代码,主要是现在网页代码显示不好看,没有IDE看起来舒服,二是给出重点关注的地方,真正需要理解的话还是自己去看代码去.自己debug
需要了解核心实现思想,关键算法以及 关注扩展点 ,需要调试bug或进行代码修改时再进一步理解里面的繁杂细节。
AOP那几个拦截点的拦截的确不错,但是解释成英文就是有点不好理解. pointcut,表示拦截哪些类,哪些方法,强调where;joinPoint,表示在方法调用前,调用后,返回值或抛出异常时进行拦截,强调when;advice,强调在拦截时做什么,强调what.
初步看了编译原理 , 以及何登成上次的 mysql 源码调用微博(代码本质上是一棵树), 我觉得用树应该可以很清晰描述代码调用关系 ; 现在结合思维导图工具 , 我觉得可以很好地描述代码调用关系.因为复杂代码情况下,时序图横向较长, 很容易看错 ; 并且要来回拖动 ; 所以我个人感觉这种表达方式 , 我还是蛮喜欢的 .
=====
参考
Why need IOC :http://stackoverflow.com/questions/871405/why-do-i-need-an-ioc-container-as-opposed-to-straightforward-di-codeSpring 框架的设计理念与设计模式分析
Spring 技术内幕

相关文章推荐
- [error handle][java] 有错误信息时,getErrorStream()返回null
- Java基础笔记(三)
- SpringMVC Service 注解及简单配置文件讲解
- 关于Java特种兵下册
- 【java开发系列】—— 自定义注解(转)
- java正则表达式
- Java栈与堆
- 使用JAVA执行SAS带有参数的存储过程
- spring简介-----阿冬专栏
- Java replace 和 replaceAll
- Java虚拟机详解04----GC算法和种类【重要】
- Java虚拟机JVM学习07 类的卸载机制
- 好炫的Lambda表达式,Java党用起来!(最简易Lambda教程)
- struts第一讲为什么有struts和工作原理i
- Java Calendar详解 - 获取近一周日期与星期
- java的垃圾回收
- java的垃圾回收
- 关于java的初始化顺序的问题
- 去掉Eclipse打开后定期弹出Usage Data Upload对话框
- (翻译)什么是Java的永久代(PermGen)内存泄漏