samoa简单介绍
2015-08-18 15:29
447 查看
其实内容都是从官网来的,不过官网是英文的,想看的大家可以看下,希望可以帮到大家。
论文名称:SAMOA: Scalable Advanced Massive Online Analysis
来自于:IEEE journal of machine learning research
背景知识:
流数据:
1.数据实时达到。
2.数据到达依次独立,处理系统无法处理数据的到达顺序。
3.数据量巨大,不能预知大小
4.单次扫描,被处理后就被抛弃或存档,以后想再获取使用这些数据很困难。
数据来源:
用户点击,搜索查询,新闻,微博,金融股票,信用卡交易,日志等等。
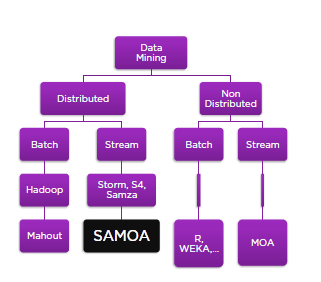
常用平台:S4,Storm,Samza.
1.samoa (Scalable Advanced Massive Online Analysis)is a platform for mining big data streams (De Francisci Morales, 2013). Written in java.
2.It’s also a library. Provide classify,cluster,regression(回归)。
Classify :VHT --Vertical Hoeffding Tree --流信息决策树的一个分布式版本。
Clustering:一种基于ClusterStream的算法.
meta-algorithms(集成学习算法): such as bagging and boosting
集成学习:所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升分类方法效果。
Bagging:将原始数据随机采样,形成N个子数据集,分布训练得到N个弱分类器,然后将结果合并,例如用得到的N个弱分类器,投票决定分类结果。
例如(1,1,0),结果为1.
Boosting: 像Bagging的加强版,区别是每次弱分类是一个不断迭代的过程,将上次分错的数据迭代进下一次分类,使得下次分类尽可能将错误数据分对,这样就可以使得最后综合时,尽可能的将错误数据分对。这种迭代将使结果无限接近最优分类,但是因为更加倾向于处理分错的样本,使得离群的错误样本会影响分类效果。此外,相对于Bagging,在最后的融合时,对于各个分类器的分类结果是有权重的,而bagging中,每个分类器权重相同。
论文名称:SAMOA: Scalable Advanced Massive Online Analysis
来自于:IEEE journal of machine learning research
背景知识:
流数据:
1.数据实时达到。
2.数据到达依次独立,处理系统无法处理数据的到达顺序。
3.数据量巨大,不能预知大小
4.单次扫描,被处理后就被抛弃或存档,以后想再获取使用这些数据很困难。
数据来源:
用户点击,搜索查询,新闻,微博,金融股票,信用卡交易,日志等等。
常用平台:S4,Storm,Samza.
Apache SAMOA is a distributed streaming machine learning (ML) framework that contains a programing abstraction for distributed streaming ML algorithms
一个可用于开发分布式流机器学习算法的框架,包含最先进的分布式流机器学习算法库。1.samoa (Scalable Advanced Massive Online Analysis)is a platform for mining big data streams (De Francisci Morales, 2013). Written in java.
2.It’s also a library. Provide classify,cluster,regression(回归)。
Classify :VHT --Vertical Hoeffding Tree --流信息决策树的一个分布式版本。
Clustering:一种基于ClusterStream的算法.
meta-algorithms(集成学习算法): such as bagging and boosting
集成学习:所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升分类方法效果。
Bagging:将原始数据随机采样,形成N个子数据集,分布训练得到N个弱分类器,然后将结果合并,例如用得到的N个弱分类器,投票决定分类结果。
例如(1,1,0),结果为1.
Boosting: 像Bagging的加强版,区别是每次弱分类是一个不断迭代的过程,将上次分错的数据迭代进下一次分类,使得下次分类尽可能将错误数据分对,这样就可以使得最后综合时,尽可能的将错误数据分对。这种迭代将使结果无限接近最优分类,但是因为更加倾向于处理分错的样本,使得离群的错误样本会影响分类效果。此外,相对于Bagging,在最后的融合时,对于各个分类器的分类结果是有权重的,而bagging中,每个分类器权重相同。

相关文章推荐
- Til the Cows Come Home
- 怎样尊重一个程序员
- CSS链接样式设置
- CFileDialog类应用详解
- 数学B - Ant on a Chessboard
- IP网际协议
- 调试Bug的神兵利器:通过WinDbg条件断点收集Log
- HDU 4305 Lightning (判断点在线段上,生成树计数)
- 如何将VirtualBox和VMware虚拟机相互转换
- linux 多个源文件在编译时会产生一个目标文件
- 根据访问IP获取所在城市并绑定下拉列表
- Object-C 和 Swift 混编 之一 Object-C 中调用 Swift
- Mysql-cluster集群
- jquery实现选项在两个下拉列表之间选择性移动的功能
- 【Mockplus教程】安装Mockplus
- 数学1A - Power of Cryptography
- unsafe与fixed
- 输入用法
- bootstrap3 char.js 使用
- ns3 dce 2层报文发送流程