Hadoop YARN 框架 Resource Management 详解
2015-08-18 14:47
507 查看
一、概述
本文将介绍ResourceManager在Yarn中的功能作用,从更细的粒度分析RM内部组成的各个组件功能和他们相互的交互方式。
二、ResourceManager的交互协议与基本职能
1、ResourceManager交互协议
在整个Yarn框架中主要涉及到7个协议,分别是ApplicationClientProtocol、MRClientProtocol、ContainerManagementProtocol、ApplicationMasterProtocol、ResourceTracker、LocalizationProtocol、TaskUmbilicalProtocol,这些协议封装了各个组件交互的信息。ResourceManager现实功能需要和NodeManager以及ApplicationMaster进行信息交互,其中涉及到的RPC协议有ResourceTrackerProtocol、ApplicationMasterProtocol和ResourceTrackerProtocol。
ResourceTracker
NodeManager通过该协议向ResourceManager中注册、汇报节点健康情况以及Container的运行状态,并且领取ResourceManager下达的重新初始化、清理Container等命令。NodeManager和ResourceManager这种RPC通信采用了和MRv1类似的“pull模型”(ResourceManager充当RPC
server角色,NodeManager充当RPC client角色),NodeManager周期性主动地向ResourceManager发起请求,并且领取下达给自己的命令。
ApplicationMasterProtocol
应用程序的ApplicationMaster同过该协议向ResourceManager注册、申请和释放资源。该协议和上面协议同样也是采用了“pull模型”,其中在RPC机制中,ApplicationMaster充当RPC client角色,ResourceManager充当RPC server角色。
ApplicationClientProtocol
客户端通过该协议向ResourceManager提交应用程序、控制应用程序(如杀死job)以及查询应用程序的运行状态等。在该RPC 协议中应用程序客户端充当RPC client角色,ResourceManager充当RPC server角色。
整理一下ResourceManager与NodeManager、ApplicationMaster和客户端RPC协议交互的信息:
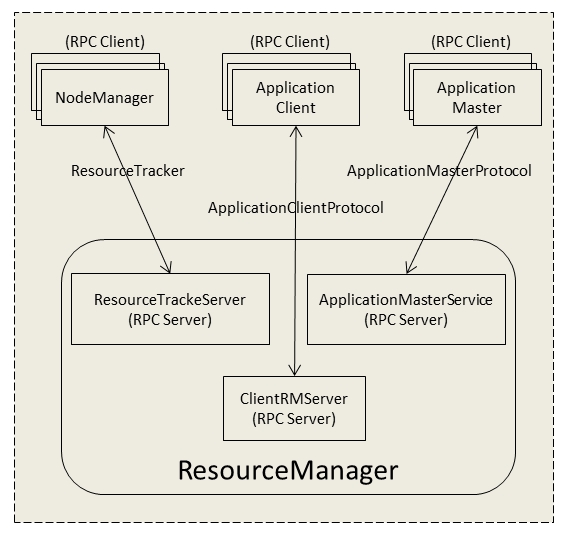
上图中的ResourceTrackeServer、ApplicationMasterService 、ClientRMServer是ResourceManager中处理上述功能的组件。
1、ResourceManager基本职能
ResourceManager基本职能概括起来就以下几方面:
与客户端进行交互,处理来自于客户端的请求,如查询应用的运行情况等。
启动和管理各个应用的ApplicationMaster,并且为ApplicationMaster申请第一个Container用于启动和在它运行失败时将它重新启动。
管理NodeManager,接收来自NodeManager的资源和节点健康情况汇报,并向NodeManager下达管理资源命令,例如kill掉某个container。
资源管理和调度,接收来自ApplicationMaster的资源申请,并且为其进行分配。这个是它的最重要的职能。
三、ResourceManager内部组成架构分析
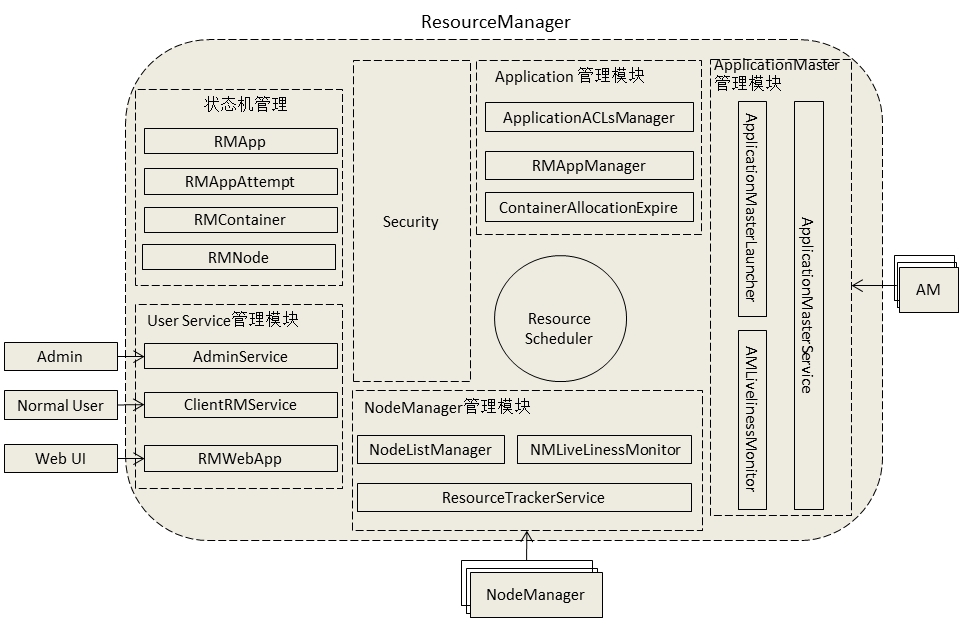
ResourceManager在底层代码实现上将各个功能模块分的比较细,各个模块功能具有很强的独立性。下图所示的是ResourceManager中的大概的功能模块组成:
1、用户交互模块
用户交互模块即上图显示的User Service管理模块。在这里边还可以看到根据不同的用户类型启用了不同的服务进行处理,AdminService处理管理员相关请求,ClientRMService处理普通客户相关请求,这样使得管理员不会因为普通客户请求太多而造成堵塞。下面看看这2个服务的具体实现代码:
ClientRMService
从上面ClientRMService的基本代码架构我们可以看出:
(1)ClientRMService是一个RPC Server,主要为来自于普通客户端的各种RPC请求。从代码实现的角度看,它是ApplicationClientProtocol协议的一个实现。
(2)之前我们已经说了,普通用户可以通过该服务来获得正在运行应用程序的相关信息,如进度情况、应用程序列表等。上面代码中都将ResourceManager运行信息封装在RMContxt接口中了,下面来看看这个接口的一个实现对象RMContext
4000
Impl:
AdminService
AdminService和ClientRMService一样都是作为RPC的服务端,它针对的处理管理员RPC请求,负责访问权限的控制,中Yarn中管理员权限的设定可以在yarn-site.xml中yarn.admi.acl项进行设置,该项的默认值是*,也就是说如果不进行设置的话就当所有的用户都是管理员。从代码上看,它是ResourceManagerAdministrationProtocol协议的一个实现:
AdminService代码和ClientRMService比较相似,它各类功能对象也差不多。
2、NodeManager管理
NodeManager主要是通过NMLivelinessMonitor、ResourceTrackerService和NodeListManager这3大组件来对NodeManager的生命周期、心跳处理以及黑名单处理。
(1)ResourceTrackerService
ResourceTrackerService是RPC协议ResourceTracker的一个实现,它作为一个RPC Server端接收NodeManager的RPC请求,请求主要包含2种信息,注册NodeManager和处理心跳信息。NodeManger启动时第一件事就是像ResourceManager注册,注册时NodeManager发给ResourceTrackerService的RPC包主要包含NodeManager所在节点的可用资源总量、对外开放的htpp端口、节点的host和port等信息,具体代码看ResourceTrackerService#registerNodeManager方法:
ResourceTrackerService另外一种功能就是处理心跳信息了,当NodeManager启动后,它会周期性地调用RPC函数ResourceTracker#nodeHeartbeat汇报心跳,心跳信息主要包含该节点的各个Container的运行状态、正在运行的Application列表、节点的健康状况等,随后ResourceManager为该NodeManager返回需要释放的Container列表、Application列表等信息。其中心跳信息处理的流程:首先,从NodeManager发来的心跳包中获得节点的状态状态信息,然后检测该节点是否已经注册过,然后检测该节点的host名称是否合法,例如是否在excluded列表中,然后再检测该次心跳是不是第一次心跳信息,这点非常重要,因为关系到心跳的重复发送与应答的相关问题。其实ResourceTrackerService和NodeManager的心跳处理机制和之前Hadoop1.x中的JobTracker与TaskTacker之间的心跳处理很想象,具体请看我之前写的一篇blog:http://zengzhaozheng.blog.51cto.com/8219051/1359887 ,再然后,为NodeManager返回心跳应答信息,最后,想RMNode发送该NodeManager的状态信息并且保存最近一次心跳应答信息。再具体看看ResourceTracker#nodeHeart方法:
(2)NodeListManager
NodeListManager主要分管黑名单(include列表)和白名单(exlude列表)管理功能,分别有yarnresouecemanager.nodes.include-path和yarnresourcemanager.nodes.exclude-path指定。黑名单列表中的nodes不能够和RM直接通信(直接抛出RPC异常),管理员可以对这两个列表进行编辑,然后使用$HADOOP_HOME/bin/yarn
rmadmin-refreshNodes动态加载修改后的列表,使之生效。
(3)NMLivelinessMonitor
NMLivelinessMonitor主要是分管心跳异常请求。该服务会周期性地遍历集群中的所有NodeManager,如果某个NodeManager在一定时间内(默认10min,可以有参数yarn.nm.liveness-monitor.expiry-interval-ms配置)没有进行心跳汇报,那么则认为它已经死掉,同时在该节点上运行的Container也会被置为运行失败释放资源。那么这些被置为失败的Container是不会直接被RM分配执行的,RM只是负责将这些被置为失败的Container信息告诉它们所对应的ApplicationMaster,需不需要重新运行它说的算,如果需要从新运行的话,该ApplicationMaster要从新向RM申请资源,然后由ApplicationMaster与对应的NodeManager通信以从新运行之前失败的Container。
2、ApplicationMaster管理模块
2、ApplicationMaster管理模块
ApplicationMaster的管理主要是用过ResouceManager内部的3个组件来完成:ApplicationMasterLauncher、AMLivelinessMonitor、ApplicationMasterService。
(1)先说说ApplicationMaster和ResourceManager整个的交互流程:
步骤一:
当ResourceManager接收到客户端提交应用程序请求时就会立马向资源管理器申请一个资源用于启动该应用程序所对应的ApplicationMaster,申请到资源后由ApplicationMasterLaucher与对应的NodeManager进行通信,要求该NodemManager在其所在节点启动该ApplicationMaster。
步骤二:
ApplicationMaster启动完毕后,ApplicationMasterLuacher通过事件的形式将刚刚启动的ApplicationMaster注册到AMLivelinessMonitor,以启动心跳监控。
步骤三:
ApplicationMaster启动后主动向ApplicationMasterService注册,并将自己所在host、端口等信息向其汇报。
步骤四:
ApplicationMaster在运行的过程中不断向ApplicationMasterService发送心跳。
步骤五:
ApplicationMasterService每次收到ApplicationMaster的心跳信息后,会同时AMLivelinessMonitor更新其最近一次发送心跳的时间。
步骤六:
当应用程序运行完毕后,ApplicationMaster向ApplicationMasterService请求注销自己。
步骤七:
ApplicationMasterService收到注销请求后,会将该应用程序的运行状态标注为完成,并且同时AMLivelinessMonitor移除对该ApplicationMaster的心跳监控。
(2)内置管理组件的详细说明
这里展开说说这3个组件的一些运行机理。
ApplicationMasterLaucher
ApplicationMasterLaucher是以线程池方式实现的一个事件处理器,其主要处理AMLaucherEvent类型的事件,包括启动(LAUNCH)和清除(CLEANUP)一个ApplicationMaster的事件。
当接收到LAUNCH类型的事件,ApplicationMasterLaucher立马会和对应的NodeManager进行通信,并且带上启动该ApplicationMaster所需要的各种信息,包括:启动命令、JAR包、环境变量等信息。NodeManager接收到来自ApplicationMasterLaucher的启动命令就会启动ApplicationMaster。
当接收到CLEANUP类型事件,ApplicationMasterLaucher立马会和对应的NodeManager进行通信,要求NodeManager杀死该ApplicationMaster,并释放掉资源。
AMLivelinessMonitor
AMLivelinessMonitor的功能和NMLivelinessMonitor的功能几乎一样,只不过AMLivelinessMonitor监控的是ApplicationMaster,而NMLivelinessMonitor监控的是NodeManager。
AMLivelinessMonitor会周期性地遍历集群中的所有ApplicationMaster,如果某个ApplicationMaster在一定时间内(默认10min,可以有参数yarn.am.liveness-monitor.expiry-interval-ms配置)没有进行心跳汇报,那么则认为它已经死掉,同时该ApplicationMaster关联运行的Container也会被置为运行失败释放资源。如果Application运行失败,则有RresourceManager重新为它申请资源,并且在另外的节点上启动它(AM启动尝试次数由参数yarn.resourcemanager.am.max-attempts控制,默认2)。那么这些被置为失败的Container是不会直接被RM分配执行的,RM只是负责将这些被置为失败的Container信息告诉它们所对应的ApplicationMaster,需不需要重新运行它说的算,如果需要从新运行的话,该ApplicationMaster要从新向RM申请资源,然后由ApplicationMaster与对应的NodeManager通信以从新运行之前失败的Container。
ApplicationMasterService
ApplicationMasterService的主要职能是处理来自ApplicationMaster的心跳请求,另外也还处理Application的注册和清理请求。注册是Application启动完成后发生的,它向ApplicationMasterService发送注册请求包,包含:ApplicationMaster所在的节点、RPC端口、tracking
url等信息。
处理心跳信息是周期型行为,只要ApplicationMaster还在运行此类请求都会发生。ApplicationMaster向ApplicationMasterService发送的心跳请求包,包含信息:请求资源类型的描述、待释放的container列表等。ApplicationMasterService返回的心跳应答信息包含:ApplicationMasterService为之分配的Container、失败的Container等信息。
清理请求是在ApplicationMaster运行完毕后,向ApplicationMasterService发送的,主要是叫其回收释放资源。
本文将介绍ResourceManager在Yarn中的功能作用,从更细的粒度分析RM内部组成的各个组件功能和他们相互的交互方式。
二、ResourceManager的交互协议与基本职能
1、ResourceManager交互协议
在整个Yarn框架中主要涉及到7个协议,分别是ApplicationClientProtocol、MRClientProtocol、ContainerManagementProtocol、ApplicationMasterProtocol、ResourceTracker、LocalizationProtocol、TaskUmbilicalProtocol,这些协议封装了各个组件交互的信息。ResourceManager现实功能需要和NodeManager以及ApplicationMaster进行信息交互,其中涉及到的RPC协议有ResourceTrackerProtocol、ApplicationMasterProtocol和ResourceTrackerProtocol。
ResourceTracker
NodeManager通过该协议向ResourceManager中注册、汇报节点健康情况以及Container的运行状态,并且领取ResourceManager下达的重新初始化、清理Container等命令。NodeManager和ResourceManager这种RPC通信采用了和MRv1类似的“pull模型”(ResourceManager充当RPC
server角色,NodeManager充当RPC client角色),NodeManager周期性主动地向ResourceManager发起请求,并且领取下达给自己的命令。
ApplicationMasterProtocol
应用程序的ApplicationMaster同过该协议向ResourceManager注册、申请和释放资源。该协议和上面协议同样也是采用了“pull模型”,其中在RPC机制中,ApplicationMaster充当RPC client角色,ResourceManager充当RPC server角色。
ApplicationClientProtocol
客户端通过该协议向ResourceManager提交应用程序、控制应用程序(如杀死job)以及查询应用程序的运行状态等。在该RPC 协议中应用程序客户端充当RPC client角色,ResourceManager充当RPC server角色。
整理一下ResourceManager与NodeManager、ApplicationMaster和客户端RPC协议交互的信息:
上图中的ResourceTrackeServer、ApplicationMasterService 、ClientRMServer是ResourceManager中处理上述功能的组件。
1、ResourceManager基本职能
ResourceManager基本职能概括起来就以下几方面:
与客户端进行交互,处理来自于客户端的请求,如查询应用的运行情况等。
启动和管理各个应用的ApplicationMaster,并且为ApplicationMaster申请第一个Container用于启动和在它运行失败时将它重新启动。
管理NodeManager,接收来自NodeManager的资源和节点健康情况汇报,并向NodeManager下达管理资源命令,例如kill掉某个container。
资源管理和调度,接收来自ApplicationMaster的资源申请,并且为其进行分配。这个是它的最重要的职能。
三、ResourceManager内部组成架构分析
ResourceManager在底层代码实现上将各个功能模块分的比较细,各个模块功能具有很强的独立性。下图所示的是ResourceManager中的大概的功能模块组成:
1、用户交互模块
用户交互模块即上图显示的User Service管理模块。在这里边还可以看到根据不同的用户类型启用了不同的服务进行处理,AdminService处理管理员相关请求,ClientRMService处理普通客户相关请求,这样使得管理员不会因为普通客户请求太多而造成堵塞。下面看看这2个服务的具体实现代码:
ClientRMService
(1)ClientRMService是一个RPC Server,主要为来自于普通客户端的各种RPC请求。从代码实现的角度看,它是ApplicationClientProtocol协议的一个实现。
(2)之前我们已经说了,普通用户可以通过该服务来获得正在运行应用程序的相关信息,如进度情况、应用程序列表等。上面代码中都将ResourceManager运行信息封装在RMContxt接口中了,下面来看看这个接口的一个实现对象RMContext
4000
Impl:
AdminService和ClientRMService一样都是作为RPC的服务端,它针对的处理管理员RPC请求,负责访问权限的控制,中Yarn中管理员权限的设定可以在yarn-site.xml中yarn.admi.acl项进行设置,该项的默认值是*,也就是说如果不进行设置的话就当所有的用户都是管理员。从代码上看,它是ResourceManagerAdministrationProtocol协议的一个实现:
2、NodeManager管理
NodeManager主要是通过NMLivelinessMonitor、ResourceTrackerService和NodeListManager这3大组件来对NodeManager的生命周期、心跳处理以及黑名单处理。
(1)ResourceTrackerService
ResourceTrackerService是RPC协议ResourceTracker的一个实现,它作为一个RPC Server端接收NodeManager的RPC请求,请求主要包含2种信息,注册NodeManager和处理心跳信息。NodeManger启动时第一件事就是像ResourceManager注册,注册时NodeManager发给ResourceTrackerService的RPC包主要包含NodeManager所在节点的可用资源总量、对外开放的htpp端口、节点的host和port等信息,具体代码看ResourceTrackerService#registerNodeManager方法:
NodeListManager主要分管黑名单(include列表)和白名单(exlude列表)管理功能,分别有yarnresouecemanager.nodes.include-path和yarnresourcemanager.nodes.exclude-path指定。黑名单列表中的nodes不能够和RM直接通信(直接抛出RPC异常),管理员可以对这两个列表进行编辑,然后使用$HADOOP_HOME/bin/yarn
rmadmin-refreshNodes动态加载修改后的列表,使之生效。
(3)NMLivelinessMonitor
NMLivelinessMonitor主要是分管心跳异常请求。该服务会周期性地遍历集群中的所有NodeManager,如果某个NodeManager在一定时间内(默认10min,可以有参数yarn.nm.liveness-monitor.expiry-interval-ms配置)没有进行心跳汇报,那么则认为它已经死掉,同时在该节点上运行的Container也会被置为运行失败释放资源。那么这些被置为失败的Container是不会直接被RM分配执行的,RM只是负责将这些被置为失败的Container信息告诉它们所对应的ApplicationMaster,需不需要重新运行它说的算,如果需要从新运行的话,该ApplicationMaster要从新向RM申请资源,然后由ApplicationMaster与对应的NodeManager通信以从新运行之前失败的Container。
2、ApplicationMaster管理模块
2、ApplicationMaster管理模块
ApplicationMaster的管理主要是用过ResouceManager内部的3个组件来完成:ApplicationMasterLauncher、AMLivelinessMonitor、ApplicationMasterService。
(1)先说说ApplicationMaster和ResourceManager整个的交互流程:
步骤一:
当ResourceManager接收到客户端提交应用程序请求时就会立马向资源管理器申请一个资源用于启动该应用程序所对应的ApplicationMaster,申请到资源后由ApplicationMasterLaucher与对应的NodeManager进行通信,要求该NodemManager在其所在节点启动该ApplicationMaster。
步骤二:
ApplicationMaster启动完毕后,ApplicationMasterLuacher通过事件的形式将刚刚启动的ApplicationMaster注册到AMLivelinessMonitor,以启动心跳监控。
步骤三:
ApplicationMaster启动后主动向ApplicationMasterService注册,并将自己所在host、端口等信息向其汇报。
步骤四:
ApplicationMaster在运行的过程中不断向ApplicationMasterService发送心跳。
步骤五:
ApplicationMasterService每次收到ApplicationMaster的心跳信息后,会同时AMLivelinessMonitor更新其最近一次发送心跳的时间。
步骤六:
当应用程序运行完毕后,ApplicationMaster向ApplicationMasterService请求注销自己。
步骤七:
ApplicationMasterService收到注销请求后,会将该应用程序的运行状态标注为完成,并且同时AMLivelinessMonitor移除对该ApplicationMaster的心跳监控。
(2)内置管理组件的详细说明
这里展开说说这3个组件的一些运行机理。
ApplicationMasterLaucher
ApplicationMasterLaucher是以线程池方式实现的一个事件处理器,其主要处理AMLaucherEvent类型的事件,包括启动(LAUNCH)和清除(CLEANUP)一个ApplicationMaster的事件。
当接收到LAUNCH类型的事件,ApplicationMasterLaucher立马会和对应的NodeManager进行通信,并且带上启动该ApplicationMaster所需要的各种信息,包括:启动命令、JAR包、环境变量等信息。NodeManager接收到来自ApplicationMasterLaucher的启动命令就会启动ApplicationMaster。
当接收到CLEANUP类型事件,ApplicationMasterLaucher立马会和对应的NodeManager进行通信,要求NodeManager杀死该ApplicationMaster,并释放掉资源。
AMLivelinessMonitor
AMLivelinessMonitor的功能和NMLivelinessMonitor的功能几乎一样,只不过AMLivelinessMonitor监控的是ApplicationMaster,而NMLivelinessMonitor监控的是NodeManager。
AMLivelinessMonitor会周期性地遍历集群中的所有ApplicationMaster,如果某个ApplicationMaster在一定时间内(默认10min,可以有参数yarn.am.liveness-monitor.expiry-interval-ms配置)没有进行心跳汇报,那么则认为它已经死掉,同时该ApplicationMaster关联运行的Container也会被置为运行失败释放资源。如果Application运行失败,则有RresourceManager重新为它申请资源,并且在另外的节点上启动它(AM启动尝试次数由参数yarn.resourcemanager.am.max-attempts控制,默认2)。那么这些被置为失败的Container是不会直接被RM分配执行的,RM只是负责将这些被置为失败的Container信息告诉它们所对应的ApplicationMaster,需不需要重新运行它说的算,如果需要从新运行的话,该ApplicationMaster要从新向RM申请资源,然后由ApplicationMaster与对应的NodeManager通信以从新运行之前失败的Container。
ApplicationMasterService
ApplicationMasterService的主要职能是处理来自ApplicationMaster的心跳请求,另外也还处理Application的注册和清理请求。注册是Application启动完成后发生的,它向ApplicationMasterService发送注册请求包,包含:ApplicationMaster所在的节点、RPC端口、tracking
url等信息。
处理心跳信息是周期型行为,只要ApplicationMaster还在运行此类请求都会发生。ApplicationMaster向ApplicationMasterService发送的心跳请求包,包含信息:请求资源类型的描述、待释放的container列表等。ApplicationMasterService返回的心跳应答信息包含:ApplicationMasterService为之分配的Container、失败的Container等信息。
清理请求是在ApplicationMaster运行完毕后,向ApplicationMasterService发送的,主要是叫其回收释放资源。

相关文章推荐
- 关于 tomcat 集群中 session 共享的三种方法
- CentOS系统基于网络的PXE+Kickstart无人值守批量安装操作系统(一)
- 通过Minimal版的iso安装CentOS7之后升级Desktop
- 监控服务篇---zabbix安装部署步骤
- adb shell [你的命令]在设备上执行成功,在pc上调用却失败原因分析
- JDK及tomcat配置
- linux caffe 64bit
- Hadoop YARN 框架 一
- WANem的使用方法,linux和windows的操作说明
- visual studio设置为使用IIS运行网站时加载项目遇到权限问题的解决方法
- linux awk命令详解
- shell脚本中变量$$、$0等的含义
- linux新建用户和用户组
- 公告:C币兑换平台系统停站维护公告
- Chapter 8 Optimization
- linux 监控网卡流量
- 部署nginx前端优化模块ngx_pagespeed
- DShow + OpenGL播放视屏
- hp-ux使用bash报:Unable to find library ‘libtermcap.so’
- 整个网站网页变黑白的效果