数据仓库备份思路
2015-08-13 16:51
218 查看
数据仓库的数据量一般是非常巨大的,我们需要每天都备份吗?这一点我至今还是不懂,只是感觉数据仓库最起码是从生产库流过来的数据没必要做完完全全的备份,但是备份还是需要的,比如我们的ETL流程如下
1:环境了解
环境:SQLServer2008R2
数据仓库的抽取过程如下
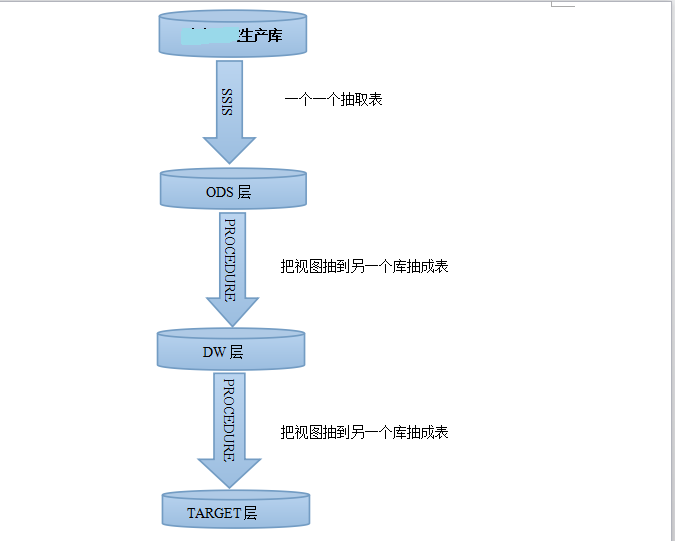
图像分析:
生产库→ods:采用的是SSIS,那么这一步我们只保存SSIS的程序包即可,因为ODS是最大限度的和业务库保持一致的原始数据
ods→dw:采用的是一个存储过程循环抽取视图的办法,原则上ods层有多少个视图,dw层就有多少个表
dw→target :和ods→dw的处理方法一样
2:设计方案
根据我们的DW抽取方案,本人感觉备份了SSIS程序之后ODS层的数据基本上可以保证OK了,大不了重新抽一个全量,可能会很耗时,当然这个地方是可以优化的。我们最简单的
方法就是备份ods和dw层的view创建脚本和procedure创建脚本,那么如何实现呢
2.1:相关脚本
--------------------------------------------------------------------相关技术---------------------------------------------------------------------------------
获取目标数据库中(sqlserver)所有视图和存储的创建脚本
效果如下
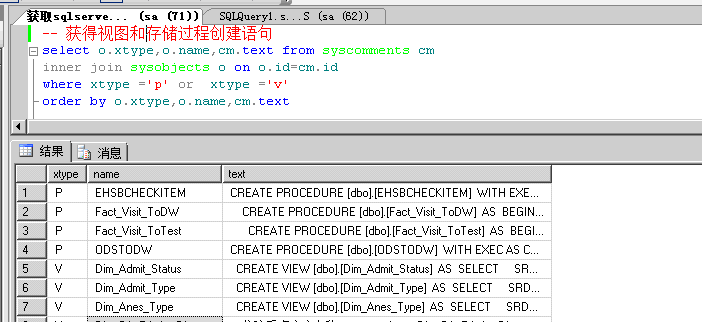
另附:
-- 获得视图和存储过程创建语句
select o.xtype,o.name,cm.text from syscomments cm inner join sysobjects o on o.id=cm.id where xtype ='p' or xtype ='v' order by o.xtype,o.name,cm.text
select * from sysobjects
where xtype='u'
-- 查询所有表名、字段名、类型、长度
select o.name, c.name,t.name,c.length from syscolumns c
inner join systypes t on c.xtype= t.xtype
inner join sysobjects o on c.id= o.id
where o.xtype='u'
order by o.name, c.name,t.name
-- 所有数据都来自于这四张表
--select * from sysobjects
--select * from syscolumns
--select * from syscomments
--select * from systypes
--------------------------------------------------------------------相关技术---------------------------------------------------------------------------------
2.2:操作步骤
通过2.1的脚本和SSIS把结果集放入到一个表中,例如BACK_UP库

这样我们就备份了ods和dw的所有视图和存储的创建脚本,恢复的时候首先恢复视图然后执行存储即可恢复数据,别忘了按层级恢复
实现效果:
我们实现了利用备份对象结构的的小数据量的方法备份了数据仓库的相关结构和抽取方法,恢复的时候就是一个抽取时间的问题了
当然如果条件允许,我们还是建议双机热备的、还有传说中的容灾备份,除了问题切换一下就好的理想方案,这里只说一个小的思
路,而且还是在特定环境下的,一般的如果DW的每一层都是采用KETTLE或者SSIS这些ETL工具抽取而成的话,那么我们就更省
事了,是不是只备份ETL程序就好了呢,事实上情况还是复杂的多了,比如我们有手工创建的一些枚举值表等等,接下来面对数据
仓库庞大的数据量,你感觉有没有必要每天备份呢?有好的想法吗?那么来信告诉我吧,希望和大家在BI这条路上一起进步与共勉
1:环境了解
环境:SQLServer2008R2
数据仓库的抽取过程如下
图像分析:
生产库→ods:采用的是SSIS,那么这一步我们只保存SSIS的程序包即可,因为ODS是最大限度的和业务库保持一致的原始数据
ods→dw:采用的是一个存储过程循环抽取视图的办法,原则上ods层有多少个视图,dw层就有多少个表
USE [SZCH_ODS_HIS] GO /****** Object: StoredProcedure [dbo].[ODSTODW] Script Date: 08/13/2015 16:26:59 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE PROCEDURE [dbo].[ODSTODW] WITH EXEC AS CALLER AS declare viewsfrom cursor for select t.name from sysobjects t where xtype='V'; open viewsfrom; declare @viewname nvarchar(200); declare @sqlstr nvarchar(1000); while @@FETCH_STATUS=0 begin set @sqlstr = 'drop table [DW_HIS].dbo.'+@viewname; print '删除表'+@viewname exec(@sqlstr); begin try set @sqlstr = 'select * into [DW_HIS].dbo.'+ @viewname+' from [ODS_HIS].[dbo].['+@viewname+']'; print '抽取表'+@viewname exec(@sqlstr); print '完成处理'+@viewname end try begin catch insert into ETLConfiguration.dbo.ODSToDWErrMsg select @viewname,ERROR_MESSAGE(),GETDATE() end catch fetch next from viewsfrom into @viewname; end close viewsfrom; deallocate viewsfrom; GO
dw→target :和ods→dw的处理方法一样
2:设计方案
根据我们的DW抽取方案,本人感觉备份了SSIS程序之后ODS层的数据基本上可以保证OK了,大不了重新抽一个全量,可能会很耗时,当然这个地方是可以优化的。我们最简单的
方法就是备份ods和dw层的view创建脚本和procedure创建脚本,那么如何实现呢
2.1:相关脚本
--------------------------------------------------------------------相关技术---------------------------------------------------------------------------------
获取目标数据库中(sqlserver)所有视图和存储的创建脚本
select o.xtype,o.name,cm.text from syscomments cm inner join sysobjects o on o.id=cm.id where xtype ='p' or xtype ='v' order by o.xtype,o.name,cm.text
效果如下
另附:
-- 获得视图和存储过程创建语句
select o.xtype,o.name,cm.text from syscomments cm inner join sysobjects o on o.id=cm.id where xtype ='p' or xtype ='v' order by o.xtype,o.name,cm.text
select * from sysobjects
where xtype='u'
-- 查询所有表名、字段名、类型、长度
select o.name, c.name,t.name,c.length from syscolumns c
inner join systypes t on c.xtype= t.xtype
inner join sysobjects o on c.id= o.id
where o.xtype='u'
order by o.name, c.name,t.name
-- 所有数据都来自于这四张表
--select * from sysobjects
--select * from syscolumns
--select * from syscomments
--select * from systypes
--------------------------------------------------------------------相关技术---------------------------------------------------------------------------------
2.2:操作步骤
通过2.1的脚本和SSIS把结果集放入到一个表中,例如BACK_UP库
这样我们就备份了ods和dw的所有视图和存储的创建脚本,恢复的时候首先恢复视图然后执行存储即可恢复数据,别忘了按层级恢复
实现效果:
我们实现了利用备份对象结构的的小数据量的方法备份了数据仓库的相关结构和抽取方法,恢复的时候就是一个抽取时间的问题了
当然如果条件允许,我们还是建议双机热备的、还有传说中的容灾备份,除了问题切换一下就好的理想方案,这里只说一个小的思
路,而且还是在特定环境下的,一般的如果DW的每一层都是采用KETTLE或者SSIS这些ETL工具抽取而成的话,那么我们就更省
事了,是不是只备份ETL程序就好了呢,事实上情况还是复杂的多了,比如我们有手工创建的一些枚举值表等等,接下来面对数据
仓库庞大的数据量,你感觉有没有必要每天备份呢?有好的想法吗?那么来信告诉我吧,希望和大家在BI这条路上一起进步与共勉

相关文章推荐
- Scala学习笔记(二):运行脚本文件
- 第五章 编码/加密——《跟我学Shiro》
- 基于TCP/IP协议的网络编程
- hdu-2553 N皇后问题
- hdu 4630 No Pain No Game【线段树 离线操作】
- HDU-1698 Just a Hook(区间更新)
- Tab Bar Controller 的二级页面
- 剑指offer第41题 和为s的两个数
- --wrong answer
- OpenGL中shader读取实现
- javaWeb项目命名规范
- c++ 预处理的应用
- Android(java)学习笔记150:为什么局部内部类只能访问外部类中的 final型的常量
- nagios服务的搭建
- HDU4407 Sum【容斥原理】
- [LeetCode] Best Time to Buy and Sell Stock
- 【华为OJ平台练习题】求最后一个单词长度
- android textview html font标签不好用
- HDU 1286 找新朋友 (欧拉函数)
- bootm命令解析