排序算法系列——希尔排序
2015-08-13 10:55
459 查看
希尔排序同之前介绍的直接插入排序一起属于插入排序的一种。希尔排序算法是按其设计者希尔(Donald Shell)的名字命名,该算法由1959年公布,是插入排序的一种更高效的改进版本。它的作法不是每次一个元素挨一个元素的比较。而是初期选用大跨步(增量较大)间隔比较,使记录跳跃式接近它的排序位置;然后增量缩小;最后增量为 1 ,这样记录移动次数大大减少,提高了排序效率。希尔排序对增量序列的选择没有严格规定。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
基本思想:先将整个待排序序列按固定步长(增量)划分成多个子序列,对每个子序列使用直接插入排序进行排序,然后依次缩减步长(增量)再进行排序,直至步长(增量)为1时,即对全部序列进行一次直接插入排序,保证整个序列被排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
实例分析:(摘自一篇博客)
假设有数组 array = [80, 93, 60, 12, 42, 30, 68, 85, 10],首先取 d1 = 4,将数组分为 4 组,如下图中相同颜色代表一组:
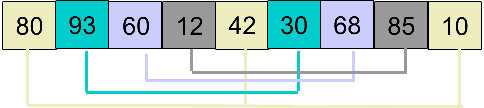
然后分别对 4 个小组进行插入排序,排序后的结果为:
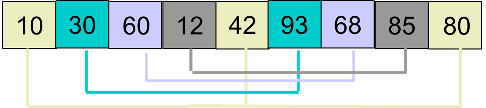
然后,取 d2 = 2,将原数组分为 2 小组,如下图:
然后分别对 2 个小组进行插入排序,排序后的结果为:
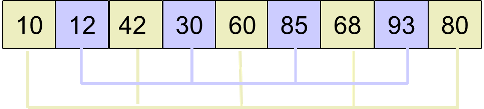
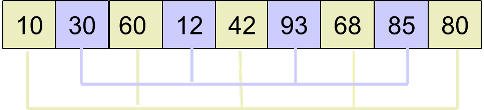
最后,取 d3 = 1,进行插入排序后得到最终结果:
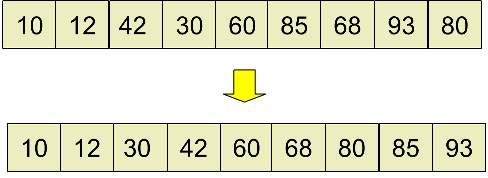
实现要点:首先需要合理选择一个起始步长(增量)d,一般选择d=n/2(n为序列长度),以后每次d=d/2,直至d=1。当选择了一个步长(增量)之后,整个序列被划分成d个子序列,每个子序列的元素为i,i+d,i+2d,…,然后对每个子序列使用直接插入排序进行排序,这里需要注意子序列的元素的间隔是d。当d=1时再进行最后一次直接插入排序,完成之后整个序列也就完成了排序。
Java实现:
代码使用了泛型,同时附带一个测试。可以将希尔排序的性能与直接插入排序进行对比,当数据量超过1000时,希尔排序的性能明显比直接插入排序快很多倍。
效率分析:
(1)时间复杂度:希尔排序是直接插入排序的一种改进,故其最优情况下的时间复杂度为O(n)。最坏情况下的时间复杂度根据步长(增量)的选择而不同。下面是摘自维基百科对希尔排序步长选择的介绍:
Donald Shell最初建议步长选择为n/2并且对步长取半直到步长达到1,虽然这样取可以比O(n^2)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…),该序列的项来自9 * 4^i - 9 * 2^i + 1和2^{i+2} * (2^{i+2} - 3) + 1这两个算式[1]。这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
(2)空间复杂度
首先从空间来看,它只需要一个元素的辅助空间,用于元素的位置交换O(1)
(3)稳定性:
不稳定。 根据步长的不同,相同元素的位置会有变化,所以希尔排序不是稳定排序。
参考文章:
常见排序算法 - 希尔排序 (Shell Sort)
希尔排序
[演算法] 希爾排序法(Shell Sort)
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
基本思想:先将整个待排序序列按固定步长(增量)划分成多个子序列,对每个子序列使用直接插入排序进行排序,然后依次缩减步长(增量)再进行排序,直至步长(增量)为1时,即对全部序列进行一次直接插入排序,保证整个序列被排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率上比前两种方法有较大提高。
实例分析:(摘自一篇博客)
假设有数组 array = [80, 93, 60, 12, 42, 30, 68, 85, 10],首先取 d1 = 4,将数组分为 4 组,如下图中相同颜色代表一组:
然后分别对 4 个小组进行插入排序,排序后的结果为:
然后,取 d2 = 2,将原数组分为 2 小组,如下图:
然后分别对 2 个小组进行插入排序,排序后的结果为:
最后,取 d3 = 1,进行插入排序后得到最终结果:
实现要点:首先需要合理选择一个起始步长(增量)d,一般选择d=n/2(n为序列长度),以后每次d=d/2,直至d=1。当选择了一个步长(增量)之后,整个序列被划分成d个子序列,每个子序列的元素为i,i+d,i+2d,…,然后对每个子序列使用直接插入排序进行排序,这里需要注意子序列的元素的间隔是d。当d=1时再进行最后一次直接插入排序,完成之后整个序列也就完成了排序。
Java实现:
package com.vicky.sort;
import java.util.Arrays;
import java.util.Random;
/**
* <p>
* 希尔排序
*
* 基本思想:
* 先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(
* 增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,
* 因此希尔排序在时间效率上比前两种方法有较大提高。
*
* 时间复杂度:根据增量(步长)的不同,最坏情况下的时间复杂度不同。
* 步长序列 Best Worst
* n/2(i) O(n) O(n(2))
* 2(k)-1 O(n) O(n(3/2))
* 2(i)3(j) O(n) O(nlog(2)n)
* 来源:https://zh.wikipedia.org/wiki/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F(维基百科)
*
* 空间复杂度:θ(1)
*
* 稳定性:不稳定
* </p>
*
* @author Vicky
* @date 2015-8-12
*/
public class ShellSort {
/**
* 排序
*
* @param data
* 待排序的数组
*/
public static <T extends Comparable<T>> void sort(T[] data) {
long start = System.nanoTime();
if (null == data) {
throw new NullPointerException("data");
}
if (data.length == 1) {
return;
}
int d = data.length / 2;// 增量
while (d >= 1) {
for (int i = 0; i < d; i++) {
// 对同一组元素进行直接插入排序data[i], data[i+d],..., data[i+nd]
int st = i + d;// 取第二个元素作为分界点
for (; st < data.length; st += d) {
T temp = data[st];
int j = st - d;
while (j >= 0 && temp.compareTo(data[j]) < 0) {
data[j + d] = data[j];
j -= d;
}
data[j + d] = temp;
}
}
d = d / 2;
}
System.out.println("use time:" + (System.nanoTime() - start) / 1000000);
}
public static void main(String[] args) {
Random ran = new Random();
Integer[] data = new Integer[1000];
for (int i = 0; i < data.length; i++) {
data[i] = ran.nextInt(10000);
}
ShellSort.sort(data);
System.out.println(Arrays.toString(data));
}
}代码使用了泛型,同时附带一个测试。可以将希尔排序的性能与直接插入排序进行对比,当数据量超过1000时,希尔排序的性能明显比直接插入排序快很多倍。
效率分析:
(1)时间复杂度:希尔排序是直接插入排序的一种改进,故其最优情况下的时间复杂度为O(n)。最坏情况下的时间复杂度根据步长(增量)的选择而不同。下面是摘自维基百科对希尔排序步长选择的介绍:
Donald Shell最初建议步长选择为n/2并且对步长取半直到步长达到1,虽然这样取可以比O(n^2)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…),该序列的项来自9 * 4^i - 9 * 2^i + 1和2^{i+2} * (2^{i+2} - 3) + 1这两个算式[1]。这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
| 步长序列 | Best复杂度 | Worst复杂度 |
|---|---|---|
| n/2^i | O(n) | O(n^2) |
| 2^k-1 | O(n) | O(n^{3/2}) |
| 2^i3^j | O(n) | O(nlog^{2}n) |
首先从空间来看,它只需要一个元素的辅助空间,用于元素的位置交换O(1)
(3)稳定性:
不稳定。 根据步长的不同,相同元素的位置会有变化,所以希尔排序不是稳定排序。
参考文章:
常见排序算法 - 希尔排序 (Shell Sort)
希尔排序
[演算法] 希爾排序法(Shell Sort)

相关文章推荐
- java对世界各个时区(TimeZone)的通用转换处理方法(转载)
- java-注解annotation
- java-模拟tomcat服务器
- java-用HttpURLConnection发送Http请求.
- java-WEB中的监听器Lisener
- Android IPC进程间通讯机制
- Android Native 绘图方法
- Android java 与 javascript互访(相互调用)的方法例子
- 介绍一款信息管理系统的开源框架---jeecg
- 聚类算法之kmeans算法java版本
- java实现 PageRank算法
- PropertyChangeListener简单理解
- JavaScript演示排序算法
- 插入排序
- 冒泡排序
- 堆排序
- 快速排序