broker
2015-08-07 11:28
288 查看
Table of contents
StatementsExternalizing statements
Adding parameters
Using text replacements
Result objects
Nested parameters
Transactions
Stored procedures
Mapping to existing object instances
Appending statements
Inheritance
Dynamic statements
Mapping associations
Lazy instantiation
Circular references
Statements
Let's start with a simple example. The following XML contains an SQL statement that selects the highest employee id. This represents the simplest XML configuration file possible: one statement.<broker name="Test Broker" version="2.0"> <sql-statement id="getMaxEmployeeId"> SELECT MAX(EmployeeId) FROM Employee </sql-statement> </broker>
This is saved in the classpath as
simple.orbroker.xml. The following Java code sets up the Broker and runs the statement.
InputStream is = getClass().getResourceAsStream("/simple.orbroker.xml");
Broker broker = new Broker(is, myDataSource);
Query qry = broker.startQuery();
Integer maxId;
try {
maxId = (Integer) qry.selectOne("getMaxEmployeeId");
} finally {
qry.close();
}
System.out.println("Max employee id: " + maxId);In the query above, because only one column has been selected, the particular column type is returned, in this case
java.lang.Integer. If multiple columns are specifed, a
java.util.Mapwill
be returned, e.g. the following statement (still selecting only one record):
<sql-statement id="getEmployee"> SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee WHERE EmployeeId IN (SELECT MAX(EmployeeId) FROM Employee) </sql-statement>
For the statement above, the Java code would look like this:
Query qry = broker.startQuery();
Map employee;
try {
employee = (Map) qry.selectOne("getEmployee");
} finally {
qry.close();
}We can change the
WHEREclause to include a range of employees, e.g.:
<sql-statement id="getEmployeesByLowSalary"> SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee WHERE Salary BETWEEN 12000 AND 18000 </sql-statement>
This means that instead of using
selectOne, we have to use the
selectManymethod, which returns a
java.util.Listinstead
of an
Object.
Query qry = broker.startQuery();
List employees;
try {
employees = qry.selectMany("getEmployeesByLowSalary");
} finally {
qry.close();
}This then returns a
Listof
Maps.
Externalizing statements
If keeping all the SQL statements within one XML file becomes too disorganized (and it probably does), then it's possible to put each individual statement in its own file and instead reference it using theexternal-sourceattribute,
like this:
<sql-statement id="getEmployees" result-object="Employee" external-source="/getEmployees.sql" />
This is highly recommended and provides better visibility if appropriately named. It also makes it possible for multiple <sql-statement/>s to reuse the same external statement file. This is useful for dynamic statements that return different columns, e.g.
a COUNT(*) vs. the columns, and hence must map to different
Adding parameters
Instead of hardcoding the salary range we can specify parameters instead.<sql-statement id="getEmployeesBySalaryRange"> SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee WHERE Salary BETWEEN :lowSalary AND :highSalary </sql-statement>
Parameters are identified by the preceeding ':' (colon), and are set using the
setParametermethod
Query qry = broker.startQuery();
qry.setParameter("lowSalary", new BigDecimal(12000));
qry.setParameter("highSalary", new BigDecimal(18000));
List employees;
try {
employees = qry.selectMany("getEmployeesBySalaryRange");
} finally {
qry.close();
}Using text replacements
Text replacement values are simple string replacements in the SQL statement. They consist of a key wrapped in '{{' and '}}' (double curly brackets). Example:<sql-statement id="getEmployees">
SELECT
EmployeeId,
EmployeeName,
Salary,
Currency,
SSN
FROM
{{schema}}.Employee
ORDER BY
{{sortColumn}}
</sql-statement>And the Java code could look like this:
broker.setTextReplacement("schema", "HumanResources");
Query qry = broker.startQuery();
qry.setTextReplacement("sortColumn", "Salary");
List employees;
try {
employees = qry.selectMany("getEmployees");
} finally {
qry.close();
}As you can tell, the replacement values can be set on both the Broker and the Query. If a replacement value should be the same for all statements, e.g. a specific database schema as above, it makes sense to set it on the Broker. Any text replacement set
on the Query overrides a replacement of equal name set on the Broker.
Result objects
Now, all this wouldn't really be any fun, if all we had to deal with was basic Java objects and maps. And this is where result objects come in. Result objects are a definition of the one-way mapping of a JDBC ResultSet row to a Java object. And this is whereO/R Broker differs from other object-relational tools in that it accepts constructors, setter methods, direct field access, as well as JavaBean properties.
Let's define a simple Employee class that can work in a multi currency application:
public class Employee {
private Integer id;
private String name;
private BigDecimal salary;
private String currency;
private int SSN;
public Employee(int id) {
this.id = new Integer(id);
}
public void setName(String name) {
this.name = name;
}
public void setSalary(BigDecimal salary, String currency) {
this.salary = salary;
this.currency = currency;
}
}Getters and other good stuff have been left out. Our Employee class has 6 attributes.
IdThe employee id can only be set through a constructor.NameThe employee name is a JavaBean property.SalaryThe salary is set through the
setSalarymethod, but because a currency is also required in that method, it is not a JavaBean property.CurrencyThe currency is essential to be able to accurately valuate the salary. Since the salary is dependent on the currency, good class design must enforce that one cannot be set without the other.Social security numberThis is a private field without any means of setting. Only use this approach if absolutely necessary, and make sure that the
SecurityManagerhosting the application accepts changing
the field's accessability.
It should be fairly obvious that this type of class design would be off-limits to most other object-relational mappers. Forcing the salary and currency to be set together, ensures that the object does not enter an invalid state. This would be impossible
with the atomic nature of properties in a JavaBean.
A result set definition for the Employee object looks like this:
<result-object id="Employee" class="my.package.Employee"> <!-- Id --> <constructor> <argument> <column name="EmployeeId"/> </argument> </constructor> <!-- Name --> <property name="name"> <column name="Name"/> </property> <!-- Salary and currency --> <method name="setSalary"> <argument> <column name="Salary"/> </argument> <argument> <column name="Currency"/> </argument> </method> <!-- Social security number --> <field name="SSN"> <column name="SSN"/> </field> </result-object>
All this is then needed, is to add a
result-objectattribute to the
sql-statementlike this:
<sql-statement id="getLastEmployee" result-object="Employee"> SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee WHERE EmployeeId IN (SELECT MAX(EmployeeId) FROM Employee) </sql-statement>
And the Java code would look something like this:
Query qry = broker.startQuery();
Employee employee;
try {
employee = (Employee) qry.selectOne("getLastEmployee");
} finally {
qry.close();
}Nested parameters
Complex object structures can also be used as parameters. The following statement uses the id attribute nested inside an Employee object:<sql-statement id="getEmployeeById" result-object="Employee"> SELECT * FROM Employee WHERE EmployeeId = :employee.id </sql-statement>
The Java could look something like this:
Query qry = broker.startQuery();
Employee employee = new Employee(756456);
qry.setParameter("employee", employee);
try {
employee = (Employee) qry.selectOne("getEmployeeById");
} finally {
qry.close();
}This would return a new employee object, provided the Employee class has a
getId()method. The object tree can be as deep as necessary, only requirement is that the object is either
a Map or an object with a getter property or even a plain no-arg method that returns an object. If any part of the tree is null, then null will be returned, i.e. the SQL statement will attempt to find a record with EmployeeId of
NULL.
Transactions
O/R Broker enforces commitment control on all SQLINSERT/UPDATE/DELETEstatements with a transaction isolation level higher than TRANSACTION_NONE. This is done through the Transaction
object. The following SQL statement will update an account with an adjustment amount.
<sql-statement id="updateAccountAmount"> UPDATE Account SET Amount = Amount + :adjustmentAmount WHERE AccountNumber = :account.accountNumber </sql-statement>
If we were to transfer $500 from one account to another, it could look something like this:
Account fromAccount = new Account("3453-2343-5675-4337");
Account toAccount = new Account("7875-7854-3458-9377");
BigDecimal amount = new BigDecimal("500.00");
Transaction txn = broker.startTransaction();
try {
// First deduct from first account
txn.setParameter("account", fromAccount);
txn.setParameter("adjustmentAmount", amount.negate());
int recordsUpdated = txn.execute("updateAccountAmount");
if (recordsUpdated != 1) {
txn.rollback();
throw new ThatsWeirdException();
}
// Then add to second account
txn.setParameter("account", toAccount);
txn.setParameter("adjustmentAmount", amount);
recordsUpdated = txn.execute("updateAccountAmount");
if (recordsUpdated != 1) {
txn.rollback();
throw new ThatsWeirdException();
}
txn.commit();
} finally {
txn.close();
}In this example no exception is caught. This is ok, since an uncommitted transaction is automatically rolled back on call to close().
It is essential that a Transaction is always closed in a
finallyblock to ensure closing and releasing the connection, even when an exception is thrown.
Stored procedures
Stored procedures are generally called like any other statement, but there are differences depending on the type of statement.Modifying
Stored procedures that perform table modifications, such as INSERT, UPDATE, DELETE, must be called through the Transaction (or Executable) object, using eitherexecuteor
executeBatchmethods.
Returning result set
If the stored procedure returns a result set, it can be called using eitherselectOneor
selectManymethods of
either the Query or Transaction object, depending on whether the stored procedure updates data or not.
Output parameters
A stored procedure that has INOUT/OUT parameters, and does not return a result set, can be called throughselectOnein which case the output parameters are mapped to a result-object,
or a
Mapif no result-object has been defined. If a result set is returned, the output parameters are available through the
getParametermethod
of the Query or Transaction object.
Let's say we have stored procedure
GetNewCustomerID(OUT NewID INTEGER)that returns the next available customer id. The call would look something like this:
<sql-statement id="getNewCustomerID">
{ CALL GetNewCustomerID(:newId) }
</sql-statement>Since this call most likely would update some table somewhere, we want to use a Transaction.
Transaction txn = broker.startTransaction();
try {
txn.execute("getNewCustomerID");
Integer newId = (Integer) txn.getParameter("newId");
txn.commit();
} finally {
txn.close();
}Alternatively, since the stored procedure does not return a result set, output parameters can be treated as a single record, which could be coded like this.
Transaction txn = broker.startTransaction();
try {
Integer newId = (Integer) txn.selectOne("getNewCustomerID");
txn.commit();
} finally {
txn.close();
}Since it is only a single parameter, it is returned by itself. If there were multiple output parameters, a
java.util.Mapwould be returned, or an object of the class defined on a result-object.
Mapping to existing object instances
In the example above two new Employee objects were instantiated in three lines of code, which wouldn't make sense. So theselectOne(and
selectMany)
has an option to pass an already created object to be mapped, like this:
Query qry = broker.startQuery();
Employee employee = new Employee(756456);
qry.setParameter("employee", employee);
try {
if (!qry.selectOne("getEmployeeById", employee) {
// Not found
}
} finally {
qry.close();
}Now the result object is passed to the
selectOnemethod, and instead of returning the object, the method returns
true/false.
The
selectManyequivalent takes a
java.util.Collectionand returns the record count.
Appending statements
Several of the SQL statements used have similarities with minor differences. It is possible to append a statement to create different statements from a base statement. Example:<sql-statement id="getEmployees" result-object="Employee"> SELECT * FROM Employee <append-statement id-suffix="ById"> WHERE EmployeeId = :id </append-statement> <append-statement id-suffix="BySalaryRange"> WHERE Salary BETWEEN :lowSalary AND :highSalary </append-statement> </sql-statement>
This will create three unique statements: "getEmployees", "getEmployeesById", "getEmployeesBySalaryRange", and are used just like any other regularly defined statement.
Appended statements can also be used to differentiate columns, like in this example:
<sql-statement id="getEmployee"> SELECT <append-statement id-suffix="Count"> COUNT(*) </append-statement> <append-statement id-suffix="List" result-object="Employee" > * </append-statement> FROM Employee </sql-statement>
This will create three statements:
"getEmployee", which is an invalid SQL statement (no columns defined)
"getEmployeeCount", which returns one column and one row.
"getEmployeeList", which returns all columns and maps to the "Employee" result-object definition.
This makes it possible to reuse the same statement for both counts and lists.
Inheritance
Class inheritance
Class inheritance can be handled by adding the attributeextendsto a
result-objectdefinition, referencing the
id of the result-object inheriting from. The classes don't actually have to implement Java inheritance, but that's probably the most common scenario. Let's extend the
my.package.Employeeclass
with a
my.package.Managerclass. The manager has an additional "team" attribute. In this example, the manager object will be populated with the TEAM column, as well as all the columns
defined for for the Employee.
<result-object id="Manager" class="my.package.Manager" extends="Employee"> <property name="team"> <column name="TEAM"/> </property> </result-object>
This reuses the Employee definition we made earlier.
Entity categorization
On the other side there's entity categorization or subtyping of entities. Take this example of a simple model of an order with rebate and item order lines.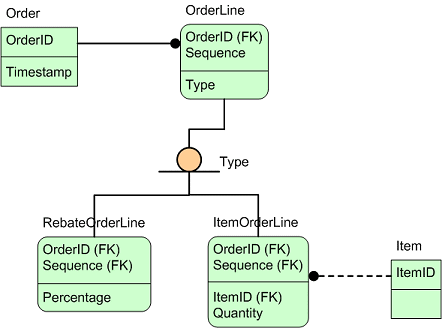
The subcategories are physically implemented as one-to-one relationships, with the TYPE column being the discriminator. A class model could be implemented like this:
public abstract class OrderLine {
private Order order;
private int sequence;
public abstract BigDecimal calculateSomething();
}
public final class RebateOrderLine extends OrderLine {
private Short percentage;
public BigDecimal calculateSomething() {
// Code calculating something
}
}
public final class ItemOrderLine extends OrderLine {
private Item item;
private Integer quantity;
public BigDecimal calculateSomething() {
// Code calculating something
}
}Notice the
OrderLinebeing abstract with the abstract method
calculateSomething().
Let's assume that the discriminator values in the TYPE column, is
'RBT'and
'ITM'; then the result object mapping
would look like this:
<result-object id="OrderLine" class="my.package.OrderLine"> <delegate-mapping use-column="TYPE"> <delegate-to result-object="RebateLine" on-value="RBT"/> <delegate-to result-object="ItemLine" on-value="ITM"/> </delegate-mapping> <!-- setters left out --> </result-object> <result-object id="RebateOrderLine" class="my.package.RebateOrderLine" extends="OrderLine"> <!-- setters left out --> </result-object> <result-object id="ItemOrderLine" class="my.package.ItemOrderLine" extends="OrderLine"> <!-- setters left out --> </result-object>
The delegated result objects do not have to extend the
result-objectfrom where they are dynamically selected, but again, it's probably the most common use case. The
result-objectcontaining
the
delegate-mappingdefinition is the default result object in case a discriminator value is not listed.
It is now possible to write the following code using a predefined
sql-statementwith a
result-objectattribute
of "OrderLine".
Query qry = broker.startQuery();
// set parameters here
OrderLine orderLine;
try {
orderLine = (OrderLine) qry.selectOne("getOrderLine");
} finally {
qry.close();
}
BigDecimal calculation = orderLine.calculateSomething();The correct subclass implementation is selected automatically based on the discriminator type.
Dynamic statements
So far, all we've seen is static hard-coded SQL. O/R Broker supports dynamic SQL through either Velocity or FreeMarker,two of the most popular template engines. Any parameter set will be part of the context for either template. The following Velocity example will select all employees, unless the
employeeparameter
has been set and it has a non-null property
id.
<sql-statement id="getEmployee" result-object="Employee" > SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee #if ($employee.id) WHERE EmployeeId = :employee.id #end </sql-statement>
Notice that the
$employee.idparameter is only used for testing its presence and then the O/R Broker-style parameter name is inserted (
:employee.id,
not
$employee.id). This is because the statement must be evaluated as a prepared statement, where values are referenced instead of coded directly into the SQL. If they were coded directly,
the programmer would have to take care of character escaping and quotes, and it could leave the SQL vulnerable to hacking if used in a web application.
Same example in FreeMarker (notice the CDATA markup necessary due to the FreeMarker syntax):
<sql-statement id="getEmployee" result-object="Employee" > <![CDATA[ SELECT EmployeeId, EmployeeName, Salary, Currency, SSN FROM Employee <#if employee.id?exists > WHERE EmployeeId = :employee.id </#if> ]]> </sql-statement>
For either type, the Java code looks exactly the same as it would with static statements:
Query qry = broker.startQuery();
Employee employee = new Employee(756456);
qry.setParameter("employee", employee);
try {
if (!qry.selectOne("getEmployee", employee)) {
// Does not exist
}
} finally {
qry.close();
}Mapping associations
Joins
For a one-to-one association, use a SQL JOIN to join the tables, and then use the<map-with>element, which uses another
result-objectfor
mapping. Let's assume we have an organization with one manager.
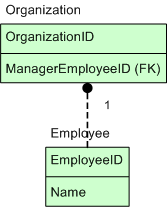
public class Organization {
private Integer id;
private Employee manager;
// constructors, getters and setters implied.
}
public class Employee {
private Integer id;
private String name;
// constructors, getters and setters implied.
}That would be mapped something like this:
<sql-statement id="selectOrganization" result-object="Organization"> SELECT * FROM Organization O JOIN Employee E ON O.ManagerEmployeeID = E.EmployeeID WHERE O.OrganizationID = :organizationId </sql-statement> <result-object id="Employee" class="my.package.Employee"> <property name="id"> <column name="EmployeeID"/> </property> <property name="name"> <column name="Name"/> </property> </result-object> <result-object id="Organization" class="my.package.Organization"> <property name="id"> <column name="OrganizationID"/> </property> <property name="manager"> <map-with result-object="Employee"/> </property> </result-object>
Sub queries
We can also use a<sub-query>for mapping other result-objects, which is necessary when there are a one-to-many relationship. Let's use the same example as before, but assume that Employee
also belongs to an Organization.
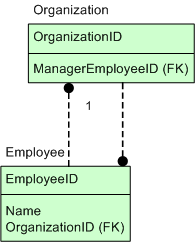
Employee class remains the same, but our Organization class would instead have a Set of employees. Something like this:
public class Organization {
private Integer id;
private Employee manager;
private Set employees;
// constructors, getters and setters implied.
}Now, our mapping would look like this:
<result-object id="Organization" class="my.package.Organization"> <property name="id"> <column name="OrganizationID"/> </property> <property name="manager"> <map-with result-object="Employee"/> </property> <property name="employees"> <sub-query sql-statement="selectEmployeesByOrganization"> <set-parameter name="organizationId" from-column="OrganizationID"/> </sub-query> </property> </result-object> <sql-statement id="selectEmployees" result-object="Customer"> SELECT * FROM Employee E <append-statement id-suffix="ByOrganization"> WHERE E.OrganizationID = :organizationId </append-statement> </sql-statement>
Another
sql-statementis invoked and the required parameters are set with column values from the current SELECT.
Lazy instantiation
If we take the previous example, we can specify lazy instantiation ofsub-queryCollections.
<result-object id="Customer" class="my.package.Customer"> <property name="shippingAddress"> <sub-query sql-statement="selectAddresses" lazy-load="true"> <set-parameter name="customer.id" from-column="CustomerID"> </sub-query> </property> <!-- Additional mapping goes here --> </result-object>
Notice the
lazy-loadattribute, which delays the execution of the SQL statement until the Collection object is accessed. This will only work on Collection interfaces, not actual classes.
The
brokerroot element has a
lazy-loadattribute that sets lazy instantiation for all
sub-querymappings.
The default is
true. Setting
lazy-loadon a
sub-queryelement
overrides the
brokersetting.
Circular references
Circular references are quite common in domain object modeling, so that should not be a limitation imposed by the persistence tool. Let's take an example of a Customer/ShippingAddress/Orders relationship.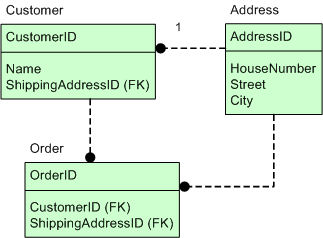
Using only public fields, the classes could look roughly like this:
public class Address {
public Integer id;
public Integer houseNumber;
public String street;
public String city;
public Customer customer;
}
public class Customer {
public Integer id;
public String customerName;
public Address shippingAddress;
public Set orderHistory;
}
public class Order {
public Integer id;
public Customer customer;
public Address shippingAddress;
}The associations between these classes are heavily circular, with Customer having multiple Orders, and a current shipping Address. The Address having a Customer reference and the Order having both a Customer reference and an a shipping Address reference.
The XML definition would look something like this:
<!-- This statement selects a customer by id and JOINs on the one-to-one relationship to shipping address. --> <sql-statement id="selectCustomerById" result-object="Customer"> SELECT * FROM Customer C JOIN Address A ON C.ShippingAddress = A.ShippingAddress WHERE C.CustomerID = :customerId </sql-statement> <!-- This statement selects customer orders and JOINs on the one-to-one relationship to customer and shipping address. --> <sql-statement id="selectOrdersByCustomer" result-object="Order"> SELECT * FROM Orders O JOIN Customer C ON O.CustomerID = C.CustomerID JOIN Address A ON O.ShippingAddressID = A.AddressID WHERE O.CustomerID = :customerId </sql-statement> <!-- This result object maps some columns directly, but reuses the Customer result-object (defined below). --> <result-object id="Address" class="my.package.Address" key-columns="AddressID"> <field name="id"> <column name="AddressID"/> </field> <field name="houseNumber"> <column name="HouseNumber"/> </field> <field name="street"> <column name="Street"/> </field> <field name="city"> <column name="City"/> </field> <field name="customer"> <map-with result-object="Customer"/> </field> </result-object> <!-- This result object maps some columns directly, but reuses both the Customer result-object and Address result-object. --> <result-object id="Order" class="my.package.Order" key-columns="OrderID"> <field name="id"> <column name="OrderID"/> </field> <field name="customer"> <map-with result-object="Customer"/> </field> <field name="shippingAddress"> <map-with result-object="Address"/> </field> </result-object> <!-- This result object maps some columns directly, but reuses the Address result-object, and uses the previously defined SQL to map a Collection of Orders. --> <result-object id="Customer" class="test.org.orbroker.Customer" key-columns="CustomerID"> <field name="id"> <column name="CUSTOMERID"/> </field> <field name="name"> <column name="NAME"/> </field> <field name="shippingAddress"> <map-with result-object="Address"/> </field> <field name="orderHistory"> <sub-query sql-statement="selectOrdersByCustomer"> <set-parameter name="customerId" from-column="CUSTOMERID"/> </sub-query> </field> </result-object>
Notice that all
result-objects have the primary keys defined in the
key-columnsattribute. A table does not have
to have a primary key defined, but the columns entered should be unique.
The above definition now allows the following code:
Integer customerId = new Integer(6573);
Query qry = broker.startQuery();
qry.setParameter("customerId", customerId);
Customer customer;
try {
customer = (Customer) qry.selectOne("selectCustomerById");
} finally {
qry.close();
}
Iterator orders = customer.orderHistory.iterator();
while (order.hasNext()) {
Order order = (Order) orders.next();
boolean circularRef =
(customer == order.customer) &&
(customer == customer.shippingAddress.customer);
System.out.println("Circular references? " + circularRef);
}The code above should result in
"Circular references? true"being printed for as many times as there are customer orders.

相关文章推荐
- Linux 数据库学习的准备工作---win通过ssh访问ubuntu
- sql之left join、right join、inner join的区别
- Vagrant is attempting to interface with the UI in a way that requires a TTY
- 北大POJ_1079_Ratio
- RAND函数和SRAND函数
- nologin
- codeforces#314C&567C Geometric Progression
- hibernate缓存机制原理
- UML建模学习(一)
- 由家里网络故障谈起
- listview复用 数据重复 id错乱问题已解决
- js代码,qq空间秒赞,2015/8/7号实测
- java UrlRewrite技术简单介绍
- Dinic邻接矩阵版本
- eclipse中常用快捷键
- oracle转Mysql中,varchar2(10)和number应该转换为什么类型?
- git笔记 常规使用
- Sort函数的相关知识
- 【暑假】[实用数据结构]UVAlive 3135 Argus
- 双缓冲解决VC++绘图时屏幕闪烁