HBase学习总结(5):HBase表设计
2015-08-03 19:10
309 查看
一、如何开始模式设计
当我们说到模式(schema),要考虑以下内容:
(1)这个表应该有多少个列族?
(2)列族使用什么数据?
(3)每个列族应该有多少列?
(4)列名应该是什么?(尽管列名不必在建表时定义,但是读写数据时是需要知道的。)
(5)单元存放什么数据?
(6)每个单元存储多少个时间版本?
(7)行键结构是什么?应该包括什么信息?
1.问题建模
一个特定列族的所有数据在HDFS上会有一个物理存储。这个物理存储可能由多个HFile组成,理想情况下可以通过合并得到一个HFile。一个列族的所有列在硬盘上存放在一起,使用这个特性可以把不同访问模式的列放在不同列族,以便隔离它们。这也是HBase被称为面向列族的存储(column-family-oriented store)的原因。
在模式设计流程中尽早定义访问模式,以便通过它们检验你的设计决定。
为了定义访问模式,第一步最好定义想使用表来回答什么问题。
2.需求定义:提前多做准备工作总是有好处的
列限定符可以按数据处理,就像值。这和关系型系统不同,关系型系统的列名是固定的并且需要在建表时预先定义。
HBase没有跨行事务的概念,要避开在客户端代码里需要事务逻辑的设计,因为这会让你不得不维护复杂的客户端。
3.均衡分布数据和负载的建模方法
HBase的运算速度涉及很多考量因素。具体包括:
(1)表中KeyValue条目数量(包括put的结果和delete留下的墓碑标记)。
(2)HFile里数据块(HFile block)的数量。
(3)平均一个HFile里KeyValue条目的数量。
(4)每行里列的平均数量。
e代表任何指定时间在MemStore里的条目数量,因为MemStore是使用跳表(skip list)实现的,所以查找行的时间复杂度是O(log e)。
宽表(wide table)的一行包括很多列。高表(tall table)是一种新模式,HFile里的KeyValue对象存储列族名字,使用短的列族名字在减少硬盘和网络I/O方面很有帮助。
HBase语境中的热点指的是负载极度集中在一小部分region上。因为负载没有分散在整个集群上,这是不合理的。服务这些region的几台机器承担了绝大部分工作,将成为整体性能的瓶颈。
4.目标数据访问
HBase表里只有键(KeyValue对象的Key部分,包括行键、列限定符和时间戳)可以建立索引。访问一个特定行的唯一办法是通过行键。
在列限定符和时间戳上建立索引,可以让你在一行上不用扫描前面所有的列而直接跳到正确的列。
从表中获取数据有两种方式,即get和scan。如果需要一行,可以使用get调用,这种情况下必须提供行键;如果想执行一次扫描(scan),如果知道起始和停止键,可以选择使用它们来限制扫描器对象扫描的行数。
根据指定的键的某个部分,可以限制读取硬盘的数据量或者网络传输的数据量。指定行键则只返回需要的行,但是服务器返回整行给客户端。指定列族让你进一步限制读取行的什么部分,因为如果行键跨多个列族,可以只读取HFile的一个子集。进一步指定列限定符和时间戳,可以让你减少返回客户端的列数,因此节省了网络I/O。
把数据放入单元值和把它放入列限定符或行键将占用相同的存储空间,但是把数据从单元移到行键将可能得到更好的性能。
一些基础知识:
(1) HBase表很灵活,可以用字符数组形式存储任何东西。
(2) 在同一列族里存储相似访问模式的所有数据。
(3) 索引建立在KeyValue对象的Key部分上,Key由行键、列限定符和时间戳按次序组成。
(4) 高表可能支持你把运算复杂度降到O(1),但是要在原子性上付出代价。
(5) 设计HBase模式时进行反规范化处理是一种可行的办法。
(6) 想想如何能够在单个API调用里而不是多个API调用里完成访问模式。HBase不支持跨行事务,要避免在客户端代码里维护这种复杂的逻辑。
(7) 散列支持定长键和更好的数据分布,但是失去了排序的好处。
(8) 列限定符可以用来存储数据,就像单元一样。
(9) 因为可以把数据放入列限定符,所以它的长度影响存储空间。当访问数据时,它也影响了硬盘和网络I/O的开销,所以尽量简练。
(10) 列族名字的长度影响了通过网络传回客户端的数据大小(在KeyValue对象里),所以尽量简练。
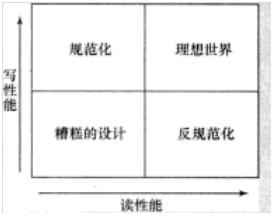
二、反规范化
规范化是关系型数据库世界的一种技术,其中每种重复信息都会放进一个自己的表。这有两个好处:当发生更新或删除时,不用担心更新指定数据所有副本的复杂性;通过保存单一副本而不是多个副本,减少了占用的存储空间。需要查询时,在SQL语句里使用JOIN子句重新联结这个数据。
反规范化是一个相反概念。数据是重复的,存在多个地方。因为你不再需要开销很大的JOIN子句,这使得查询数据变得更容易、更快。
从性能观点看,规范化为写做优化,而反规范化为读做优化。
三、相同表里的混杂数据
尽可能分离不同的访问模式。
四、行键设计原则
在设计HBase表时,行键是唯一重要的事情,应该基于预期的访问模式来为行键建模。
行键决定了访问HBase表时可以得到的性能。这个结论根植于两个事实:region基于行键为一个区间的行提供服务,并且负责区间内每一行;HFile在硬盘上存储有序的行。当region刷写留在内存里的行时生成了HFile。这些行已经排过序,也会有序地刷写到硬盘上。HBase表的有序特性和底层存储格式可以让你根据如何设计行键以及把什么放入列限定符来推理其性能表现。
关系型数据库可以在多个列上建立索引,但HBase只能在键上建立索引,访问数据的唯一办法是使用行键。如果不知道想访问的数据的行键,就必须扫描相当多的行。
五、I/O考虑
以下技巧针对访问模式对设计行键进行优化。
1.为写优化
应该如何把数据分散在多个region上呢?
(1)散列
如果你愿意在行键里放弃时间戳信息,使用原始数据的散列值作为行键是一种可能的解决方案。
散列算法有一个非零碰撞概率。使用散列函数的方式也很重要。
(2)salting
在思考行键的构成时,salting是一种技巧。
2.为读优化
尽量把较少的HFile数据块读入内存,来获得要寻找的数据集。因为数据存储在一起,每次读取HFile数据块时可以比数据分散存储时得到更多的信息。
这里行键的结构对于读性能很重要。
3.基数和行键结构
有效的行键设计不仅要考虑把什么放入行键中,而且要考虑它们在行键里的位置。
信息在行键里的位置和选择放入什么信息同等重要。
六、从关系型到非关系型
从关系型数据库知识映射到HBase没有捷径,它们是不同的思考方式。
关系型数据库和HBase是不同的系统,它们拥有不同的设计特性,可以影响到应用系统的设计。
1.一些基本概念
关系型数据库建模包括3个主要概念:
a.实体(entity)—映射到表(table)。
b.属性(attribute)—映射到列(column)。
c.联系(relationship)—映射到外键(foreign-key)。
(1)实体
在关系型数据库和HBase中,实体的容器(container)是表,表中每行代表实体的一个实例。用户表中每行代表一个用户。
(2)属性
为了把属性映射到HBase,必须区分至少两种属性类型:
a.识别属性(identifying attribute):这种属性可以唯一地精确识别出实体的一个实例(也就是一行)。关系型表里,这种属性构成表的主键(primary key)。在HBase中,这种属性成为行键(rowkey)的一部分。
一个实体经常是由多个属性识别出来的,这一点正好映射到关系型数据库里的复合键(compound keys)概念。
b.非识别属性(non-identifying attribute):在HBase中,它们基本映射到列限定符。
(3)联系
逻辑关系模型使用两种主要联系:一对多和多对多。在关系型数据库中,把前者直接建模为外键(foreign key),把后者建模为连接表(junction table)。
HBase没有内建的联结(join)或约束(constrain),几乎不使用显示联系。
2.嵌套实体
HBase的列(也叫做列限定符)不需要在设计时预先定义。它们可以是任何东西。HBase具有在一个父实体或主实体的行里嵌套另一个实体的能力,但这远远不是一个灵活的模式行(flexible schema row)。
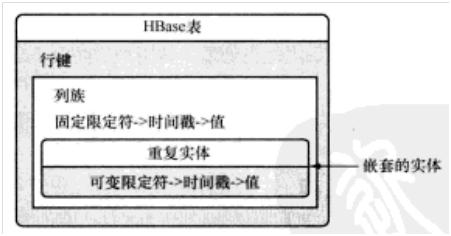
嵌套的实体是从关系型映射到非关系型的又一个工具。
如果你得到子实体的唯一方法是通过父实体,并且你希望在一个父实体的所有子实体上有事务级保护,这种技术是最正确的选择。
七、列族高级配置
1.可配置的数据块大小
HFile数据块大小可以在列族层次设置。数据块索引存储每个HFile数据块的起始键。数据块大小配置会影响数据块索引的大小。数据块越小,索引越大,因而占用的内存空间越大。同时,因为加载进内存的数据块更小,随机查找性能更好。
2.数据块缓存
把数据放进读缓存,但工作负载却经常不能从中获得性能提升。
3.激进缓存
可以选择一些列族,赋予它们在数据块缓存里有更高的优先级(LRU缓存)。
4.布隆过滤器
布隆过滤器允许对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器,看看该行是否不在这个数据块中。
5.生存时间(TTL)
HBase可以让你在数秒内在列族级设置一个TTL,早于指定TTL值的数据在下一次大合并时会被删除。如果你在同一单元上有多个时间版本,早于设定TTL的版本会被删除。
6.压缩
HFile可以被压缩并存放在HDFS上,HBase可以使用多种压缩编码,包括LZO、Snappy和GZIP。
注意,数据只在硬盘上是压缩的,在内存里或通过网络传输时是没有压缩的。
7.单元时间版本
在默认情况下,HBase每个单元维护3个时间版本,这个属性是可以设置的。
同时也可以指定列族存储的最少时间版本数。
八、过滤数据
过滤器也被称为下推判断器,支持你把数据过滤标准从客户端下推到服务器。
较为常用的过滤器包括:
1.行过滤器
这是一种预装的比较过滤器,支持基于行键过滤数据。
2.前缀过滤器
这是行过滤器的一种特例,它基于行键的前缀值进行过滤。
3.限定符过滤器
它是一种类似于行过滤器的比较过滤器,不同之处是它用来匹配列限定符而不是行键。它使用与行过滤器相同的比较运算符和比较器类型。
4.值过滤器
它提供了与行过滤器或限定符过滤器一样的功能,只是针对的是单元值。
5.时间戳过滤器
它允许针对返回给客户端的时间版本进行更细粒度的控制。
6.过滤器列表
组合使用多个过滤器经常是很有用的。
九、小结
模式设计的出发点是问题,而不是关系。
模式设计永远不会结束。
数据规模是第一本质性的因素。
每个维度都是一个提升性能的机会。
本人微信公众号:zhouzxi,请扫描以下二维码:

当我们说到模式(schema),要考虑以下内容:
(1)这个表应该有多少个列族?
(2)列族使用什么数据?
(3)每个列族应该有多少列?
(4)列名应该是什么?(尽管列名不必在建表时定义,但是读写数据时是需要知道的。)
(5)单元存放什么数据?
(6)每个单元存储多少个时间版本?
(7)行键结构是什么?应该包括什么信息?
1.问题建模
一个特定列族的所有数据在HDFS上会有一个物理存储。这个物理存储可能由多个HFile组成,理想情况下可以通过合并得到一个HFile。一个列族的所有列在硬盘上存放在一起,使用这个特性可以把不同访问模式的列放在不同列族,以便隔离它们。这也是HBase被称为面向列族的存储(column-family-oriented store)的原因。
在模式设计流程中尽早定义访问模式,以便通过它们检验你的设计决定。
为了定义访问模式,第一步最好定义想使用表来回答什么问题。
2.需求定义:提前多做准备工作总是有好处的
列限定符可以按数据处理,就像值。这和关系型系统不同,关系型系统的列名是固定的并且需要在建表时预先定义。
HBase没有跨行事务的概念,要避开在客户端代码里需要事务逻辑的设计,因为这会让你不得不维护复杂的客户端。
3.均衡分布数据和负载的建模方法
HBase的运算速度涉及很多考量因素。具体包括:
(1)表中KeyValue条目数量(包括put的结果和delete留下的墓碑标记)。
(2)HFile里数据块(HFile block)的数量。
(3)平均一个HFile里KeyValue条目的数量。
(4)每行里列的平均数量。
e代表任何指定时间在MemStore里的条目数量,因为MemStore是使用跳表(skip list)实现的,所以查找行的时间复杂度是O(log e)。
宽表(wide table)的一行包括很多列。高表(tall table)是一种新模式,HFile里的KeyValue对象存储列族名字,使用短的列族名字在减少硬盘和网络I/O方面很有帮助。
HBase语境中的热点指的是负载极度集中在一小部分region上。因为负载没有分散在整个集群上,这是不合理的。服务这些region的几台机器承担了绝大部分工作,将成为整体性能的瓶颈。
4.目标数据访问
HBase表里只有键(KeyValue对象的Key部分,包括行键、列限定符和时间戳)可以建立索引。访问一个特定行的唯一办法是通过行键。
在列限定符和时间戳上建立索引,可以让你在一行上不用扫描前面所有的列而直接跳到正确的列。
从表中获取数据有两种方式,即get和scan。如果需要一行,可以使用get调用,这种情况下必须提供行键;如果想执行一次扫描(scan),如果知道起始和停止键,可以选择使用它们来限制扫描器对象扫描的行数。
根据指定的键的某个部分,可以限制读取硬盘的数据量或者网络传输的数据量。指定行键则只返回需要的行,但是服务器返回整行给客户端。指定列族让你进一步限制读取行的什么部分,因为如果行键跨多个列族,可以只读取HFile的一个子集。进一步指定列限定符和时间戳,可以让你减少返回客户端的列数,因此节省了网络I/O。
把数据放入单元值和把它放入列限定符或行键将占用相同的存储空间,但是把数据从单元移到行键将可能得到更好的性能。
一些基础知识:
(1) HBase表很灵活,可以用字符数组形式存储任何东西。
(2) 在同一列族里存储相似访问模式的所有数据。
(3) 索引建立在KeyValue对象的Key部分上,Key由行键、列限定符和时间戳按次序组成。
(4) 高表可能支持你把运算复杂度降到O(1),但是要在原子性上付出代价。
(5) 设计HBase模式时进行反规范化处理是一种可行的办法。
(6) 想想如何能够在单个API调用里而不是多个API调用里完成访问模式。HBase不支持跨行事务,要避免在客户端代码里维护这种复杂的逻辑。
(7) 散列支持定长键和更好的数据分布,但是失去了排序的好处。
(8) 列限定符可以用来存储数据,就像单元一样。
(9) 因为可以把数据放入列限定符,所以它的长度影响存储空间。当访问数据时,它也影响了硬盘和网络I/O的开销,所以尽量简练。
(10) 列族名字的长度影响了通过网络传回客户端的数据大小(在KeyValue对象里),所以尽量简练。
二、反规范化
规范化是关系型数据库世界的一种技术,其中每种重复信息都会放进一个自己的表。这有两个好处:当发生更新或删除时,不用担心更新指定数据所有副本的复杂性;通过保存单一副本而不是多个副本,减少了占用的存储空间。需要查询时,在SQL语句里使用JOIN子句重新联结这个数据。
反规范化是一个相反概念。数据是重复的,存在多个地方。因为你不再需要开销很大的JOIN子句,这使得查询数据变得更容易、更快。
从性能观点看,规范化为写做优化,而反规范化为读做优化。
三、相同表里的混杂数据
尽可能分离不同的访问模式。
四、行键设计原则
在设计HBase表时,行键是唯一重要的事情,应该基于预期的访问模式来为行键建模。
行键决定了访问HBase表时可以得到的性能。这个结论根植于两个事实:region基于行键为一个区间的行提供服务,并且负责区间内每一行;HFile在硬盘上存储有序的行。当region刷写留在内存里的行时生成了HFile。这些行已经排过序,也会有序地刷写到硬盘上。HBase表的有序特性和底层存储格式可以让你根据如何设计行键以及把什么放入列限定符来推理其性能表现。
关系型数据库可以在多个列上建立索引,但HBase只能在键上建立索引,访问数据的唯一办法是使用行键。如果不知道想访问的数据的行键,就必须扫描相当多的行。
五、I/O考虑
以下技巧针对访问模式对设计行键进行优化。
1.为写优化
应该如何把数据分散在多个region上呢?
(1)散列
如果你愿意在行键里放弃时间戳信息,使用原始数据的散列值作为行键是一种可能的解决方案。
散列算法有一个非零碰撞概率。使用散列函数的方式也很重要。
(2)salting
在思考行键的构成时,salting是一种技巧。
2.为读优化
尽量把较少的HFile数据块读入内存,来获得要寻找的数据集。因为数据存储在一起,每次读取HFile数据块时可以比数据分散存储时得到更多的信息。
这里行键的结构对于读性能很重要。
3.基数和行键结构
有效的行键设计不仅要考虑把什么放入行键中,而且要考虑它们在行键里的位置。
信息在行键里的位置和选择放入什么信息同等重要。
六、从关系型到非关系型
从关系型数据库知识映射到HBase没有捷径,它们是不同的思考方式。
关系型数据库和HBase是不同的系统,它们拥有不同的设计特性,可以影响到应用系统的设计。
1.一些基本概念
关系型数据库建模包括3个主要概念:
a.实体(entity)—映射到表(table)。
b.属性(attribute)—映射到列(column)。
c.联系(relationship)—映射到外键(foreign-key)。
(1)实体
在关系型数据库和HBase中,实体的容器(container)是表,表中每行代表实体的一个实例。用户表中每行代表一个用户。
(2)属性
为了把属性映射到HBase,必须区分至少两种属性类型:
a.识别属性(identifying attribute):这种属性可以唯一地精确识别出实体的一个实例(也就是一行)。关系型表里,这种属性构成表的主键(primary key)。在HBase中,这种属性成为行键(rowkey)的一部分。
一个实体经常是由多个属性识别出来的,这一点正好映射到关系型数据库里的复合键(compound keys)概念。
b.非识别属性(non-identifying attribute):在HBase中,它们基本映射到列限定符。
(3)联系
逻辑关系模型使用两种主要联系:一对多和多对多。在关系型数据库中,把前者直接建模为外键(foreign key),把后者建模为连接表(junction table)。
HBase没有内建的联结(join)或约束(constrain),几乎不使用显示联系。
2.嵌套实体
HBase的列(也叫做列限定符)不需要在设计时预先定义。它们可以是任何东西。HBase具有在一个父实体或主实体的行里嵌套另一个实体的能力,但这远远不是一个灵活的模式行(flexible schema row)。
嵌套的实体是从关系型映射到非关系型的又一个工具。
如果你得到子实体的唯一方法是通过父实体,并且你希望在一个父实体的所有子实体上有事务级保护,这种技术是最正确的选择。
七、列族高级配置
1.可配置的数据块大小
HFile数据块大小可以在列族层次设置。数据块索引存储每个HFile数据块的起始键。数据块大小配置会影响数据块索引的大小。数据块越小,索引越大,因而占用的内存空间越大。同时,因为加载进内存的数据块更小,随机查找性能更好。
2.数据块缓存
把数据放进读缓存,但工作负载却经常不能从中获得性能提升。
3.激进缓存
可以选择一些列族,赋予它们在数据块缓存里有更高的优先级(LRU缓存)。
4.布隆过滤器
布隆过滤器允许对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器,看看该行是否不在这个数据块中。
5.生存时间(TTL)
HBase可以让你在数秒内在列族级设置一个TTL,早于指定TTL值的数据在下一次大合并时会被删除。如果你在同一单元上有多个时间版本,早于设定TTL的版本会被删除。
6.压缩
HFile可以被压缩并存放在HDFS上,HBase可以使用多种压缩编码,包括LZO、Snappy和GZIP。
注意,数据只在硬盘上是压缩的,在内存里或通过网络传输时是没有压缩的。
7.单元时间版本
在默认情况下,HBase每个单元维护3个时间版本,这个属性是可以设置的。
同时也可以指定列族存储的最少时间版本数。
八、过滤数据
过滤器也被称为下推判断器,支持你把数据过滤标准从客户端下推到服务器。
较为常用的过滤器包括:
1.行过滤器
这是一种预装的比较过滤器,支持基于行键过滤数据。
2.前缀过滤器
这是行过滤器的一种特例,它基于行键的前缀值进行过滤。
3.限定符过滤器
它是一种类似于行过滤器的比较过滤器,不同之处是它用来匹配列限定符而不是行键。它使用与行过滤器相同的比较运算符和比较器类型。
4.值过滤器
它提供了与行过滤器或限定符过滤器一样的功能,只是针对的是单元值。
5.时间戳过滤器
它允许针对返回给客户端的时间版本进行更细粒度的控制。
6.过滤器列表
组合使用多个过滤器经常是很有用的。
九、小结
模式设计的出发点是问题,而不是关系。
模式设计永远不会结束。
数据规模是第一本质性的因素。
每个维度都是一个提升性能的机会。
本人微信公众号:zhouzxi,请扫描以下二维码:

相关文章推荐
- 数据库连接
- hud 1012 u Calculate e (acm)
- Linux进程间通信——使用共享内存
- 黑马程序员 c语言的基础
- final,finally,finalize的区别?
- Mac下安装nginx
- Illegal spices (URAL 1995 YY构造)
- Codeforces Round #273 (Div. 2) C - Table Decorations dp
- FpmBizSubModuleCond
- java环境搭建
- 2015暑假训练赛团体赛(8.3)
- FpmBizSubModuleVo
- 第二周第一天上课
- HDU 1556
- mysql ERROR 1045 (28000): Access denied for user
- IOS终极20问
- [Q]无法卸载怎么办
- 51nod 算法马拉松4
- java 实现线程同步的方式有哪些
- 剑指Offer面试题21(Java版):包含min函数的栈