宽带离网用户分析(4) 特征选择
2015-08-03 15:06
309 查看
宽带离网用户分析之特征选择
前面我们介绍过一些特征抽取的方法(Feature Extraction),现在我们来谈谈特征选择(Feature Selection)。1. 特征选择的重要性
特征其实是机器学习问题里面一个很重要的问题,做图像的人知道,其实图像圈子里面很多人就是做特征的。当今“大数据”的概念各种泛滥,但是“以数据为中心”的观点的确有其道理。当数据特别多并且不断变化和增长的时候,对数据深入的理解往往可能比高端的模型知识更为有用。
如果原始数据是土,那么我们做数据预处理和特征抽取则相当于用土来烧砖块,而我们的建模就是起大厦,这中间有关键的一部——用砖块累大厦。但是用什么砖来累呢?劣质甚至不合格的砖也拿过去用吗?
不错,我们需要对砖块进行选择——特征选择。
从机器学习的角度来讲,特征选择可以减少建模的时空代价,并且好的特征可以增加模型的精度和泛化性能。从我们分类的需求来看,就是让正负样本更加可分。
说白了,特征选择可以剔除冗余的信息、无用的信息,从而使机器学习的性能更优。
2. 特征选择形式化表示
我们有特征集合{F1,F2,...,Fn},假设最优的特征集合是{Fa,Fb,Fc},其他的特征不是最优特征集合的冗余信息就是完全和训练不相关的无用信息。3. 特征选择方法介绍
这里我们介绍几种常用的特征选择方法的思想,大家如果感兴趣可以去Google特征选择方法的Review,那里有更加详尽的介绍。3.1. 搜索
从形式化表示中我们不难发现,特征选择就是搜索一个子集的问题,说白了就是一个搜索问题,如果我们不知道最优特征集合的元素个数,很明显这是一个搜索空间为2N的搜索问题,N为原始特征集合的元素个数,搜索的方法就是用这些特征组合来建模,验证模型性能。指数级的搜索空间,可以用启发式搜索的方法进行优化,也就是在目前特征集合的基础上剔除最差的特征,然后加入“加入以后效果最好”的特征,反复直至收敛。
这个方法最大局限性就在于需要建模,如果模型的复杂度较高,那么过程代价太大。
3.2. Filter方法
该方法的精髓在于直接通过特征的某些指标对特征进行筛选,这样代价就很小。对于某些指标,我们可以设立阈值,仅选取阈值一侧的指标,或者取Top N的指标。这里介绍衡量指标好坏的四个标准:
3.2.1. 距离度量
其实很简单,在某个特征维度上看样本的距离,如果不同样本的距离更大,说明这个特征可以更好的将样本分开,是更好的特征。3.2.2. 信息度量
机器学习中最经常用到的就是信息论中的相关内容,因为机器学习和统计、分布式密切相关,有本书就叫做《统计机器学习》。我们举个小例子来看这个问题,比如我看看抽烟是不是判断人是否得癌症的好的特征,我们来看分布:
| 是否抽烟\是否得癌症 | 是 | 否 |
|---|---|---|
| 是 | 9 | 1 |
| 否 | 1 | 8 |
再比如:
| 是否开车\是否得癌症 | 是 | 否 |
|---|---|---|
| 是 | 5 | 4 |
| 否 | 4 | 5 |
3.2.3. 依赖性度量
其实依赖性度量和信息度量都是考察指标的“相关程度”,不过依赖性度量面向的是同时出现的n个对应的数值特征,比如{x1,x2,...,xn}和{y1,y2,...,yn}其中Xi和Yi一一对应,并且是变化的数值。这里并不是说对于连续变化的数值特征就不能用信息度量的方法,不难想到,离散化以后一样可以计数求分布的,所以同样可以使用。
这里介绍一个最为典型的计算相关性的方法,Pearson相关系数,其衡量的是线性相关性:
r=N∑xiyi√−∑xi∑yi∑x2i−(∑xi)2√∑y2i−(∑yi)2√
利用依赖性度量,我们可以筛选出和目标值相关程度高的特征,同时如果两个特征相关程度很高,那么说明这两种特征具有很高的冗余性。
3.2.4. 一致性度量
用一句话概括,就是不断删减特征,但是使样本维持这样一种性质:给定两个样本, 若他们特征值均相同,则类别也相同。试想,每删除一个属性,那么样本就少了一种划分,那么剩下的相同特征的样本群体必然扩大,要保持一致性,那么就必须找那些“无关紧要”的特征加以删除。
4. 特征选择一般流程
其实用分类器性能直接进行筛选的效果肯定是比Filter要好的,因为有些信息可能需要特征之间相结合才能得到,比如下图最简单的例子: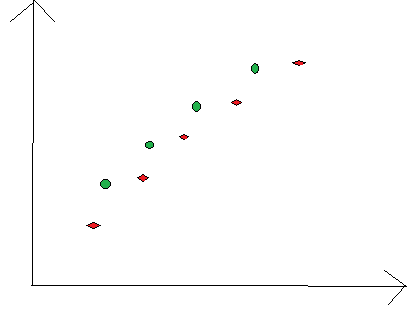
可以看出不管是从哪一位特征上看,样本的区分度都很差,但是这两位维“很差的”特征在间隔分类器中却可以将样本完全分开。
所以一般,我们先用Filter方法进行大规模的筛选,然后用分类器进行实验,进一步选取特征,正如上面所说的,Filter也完全有可能筛掉非常好的特征,这是值得注意和思考的。
下一篇我们将介绍本任务用的特征选择方法。

相关文章推荐
- jQuery plugin items filter
- 全国哀悼日网站页面变成灰色的filter方法
- 用css filter做鼠标滑过图片效果
- ASP 使用Filter函数来检索数组的实现代码
- ASP.NET MVC:Filter和Action的执行介绍
- JSP Filter的应用方法
- PHP中实现Bloom Filter算法
- Jquery find与filter函数区别 说明
- PHP内置过滤器FILTER使用实例
- PHP中filter函数校验数据的方法详解
- javascipt:filter过滤介绍及使用
- 5个数组Array方法: indexOf、filter、forEach、map、reduce使用实例
- 跟老齐学Python之大话题小函数(2)
- Python中的特殊语法:filter、map、reduce、lambda介绍
- Python过滤函数filter()使用自定义函数过滤序列实例
- Python中的map、reduce和filter浅析
- Android解析Intent Filter的方法
- Python内置函数之filter map reduce介绍
- Filter的好处以及用途
- 使用PHP自带的filter函数进行数据校验