NoSQL and Data Scalability 2.0
2015-08-02 17:21
579 查看
NoSQL and Data Scalability 2.0
Keeping Up With the World of Non-Relational Databases
byEugene Ciurana
Provides an introduction to basic NoSQL and Data Scalability terminology and techniques and exhibits in-depth examples of popular NoSQL technologies.
Introduction
This Refcard provides an introduction to basic NoSQL and Data Scalability terminology and techniques and exhibits in-depth examples of popular NoSQL technologies, including architectures, common uses, & more.NoSQL and Data Scalability 2.0 demystifies the latest techniques in high-volume data storage, search, and management by explaining how they work and when to apply them.
Section 2
Scalable Data Architectures
Scalable data architectures have evolved to improve overall system efficiency and reduce operational costs. Specific NoSQL databases may have different topological requirements, but the general architecture is the same.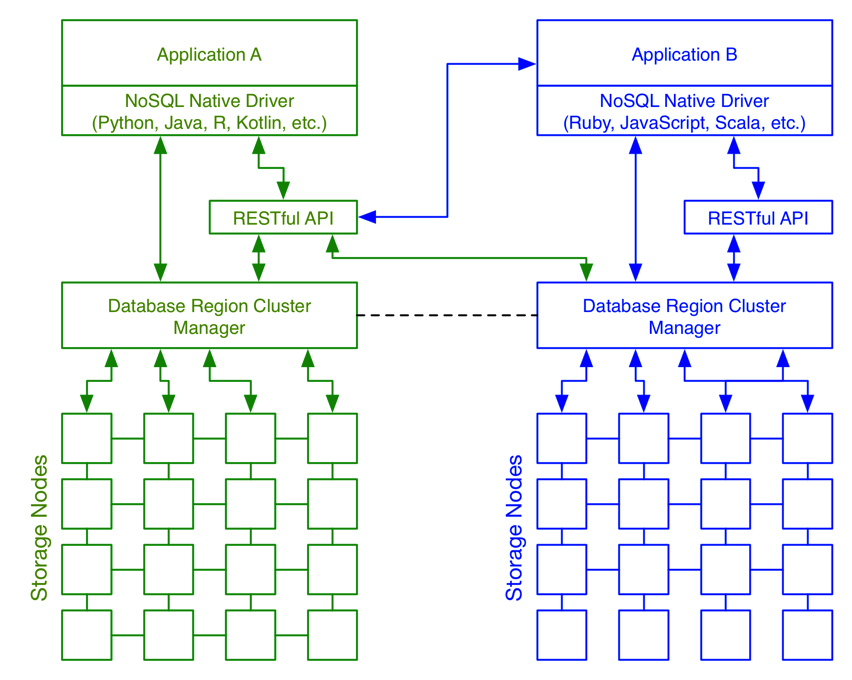
In general, NoSQL architectures offer:
Eventual consistency
High availability with partition tolerance
Horizontal scalability (optimized for large volume of reads and queries)
Cloud readiness
Distributed, structured data storage
Cloud readiness describes the database being used as a service and the ability to deploy the storage grid and cluster manager to a cloud provider.
Section 3
NoSQL
NoSQL describes a horizontally scalable, non-relational database with built-in replication support. Applications interact with the database through a simple API, and the data is stored in a schema-free repository as large filesor data blocks. The repository is often a custom file system designed to support NoSQL operations with high replication.
NoSQL Databases Classification
Database TypesUsesDocumentDocuments, semi-structured dataColumnRead/write raw time series dataGraphNamed entities, semantic queries, associative data setsKey-ValueKey-value pair, where the values can be complex and mixed datastructures (e.g. a document)Multi-modelTwo or more database types, including relational databases and the types listed above, with a common database manager for all
While all database types are in common use, document stores are most often associated with NoSQL systems due to their pervasiveness in web and mobile content handling applications.
Is NoSQL For You?
Does your app design...Require high-speed throughput?
Need to handle high volumes of data?
Work well with weak data consistency?
Benefit from direct object-database entity mapping?
Have to be Always On?
If you checked off four or more items from the list, then NoSQL is a good fit for you.
Always On just means that users will have access to complete app functionality at all times. In mobile app and gaming contexts, it can mean access to data that is "a bit behind" the effective system state (i.e. eventual consistency
is acceptable).
NoSQL Performance and TCO Comparison
Total cost of ownership (TCO) depends on functionality and complexity. A higher TCO may be acceptable when performance (throughput or scalability) is a primary concern.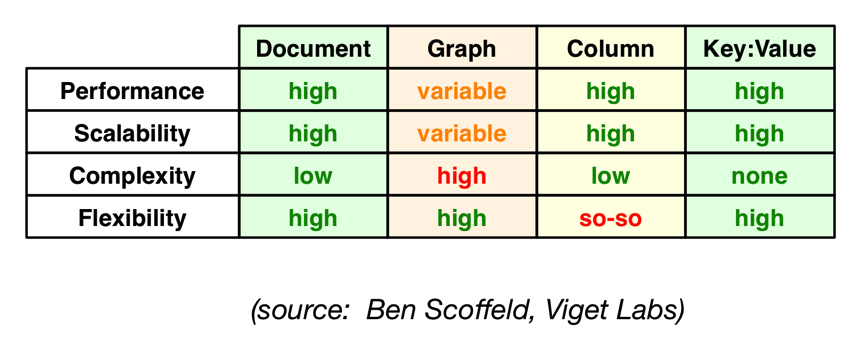
Document and key-value stores are most popular because of their ease of use, flexibility, and applicability across many problem domains—at a reasonable TCO.
Tip: Graph databases are excellent replacements for complex relational models because relationships between entities (or graph edges) are more efficient and better suited for high-performance applications than using explicit
joins and foreign-keys.
Which Data Store Model to Use?
The flowchart in Figure 3 describes how to choose the most appropriate database or store for the application.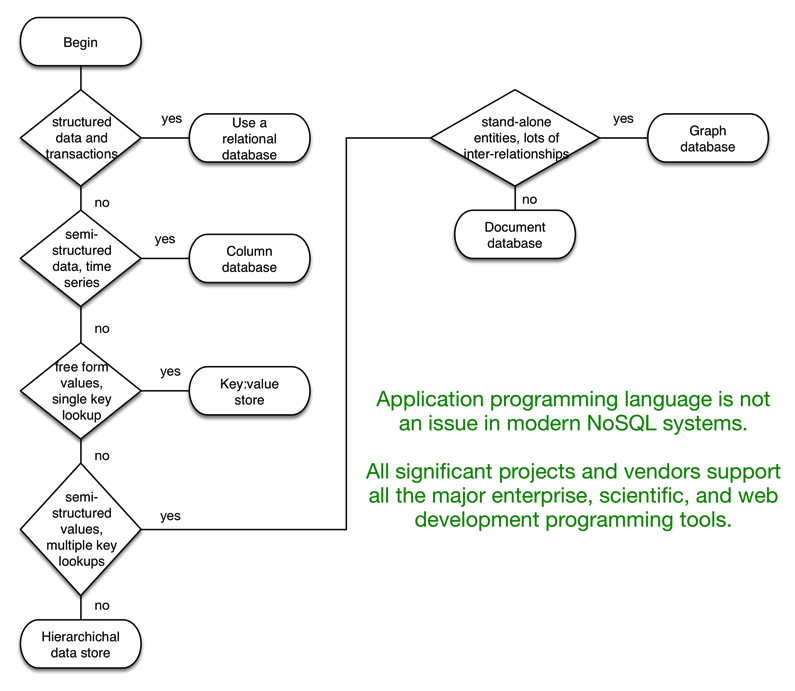
Section 4
Cloud Databases
Demand-based scaling is an attractive proposition for running NoSQL systems on the cloud; it maximizes the advantages of running the application on cloud-based providers like AWS, Azure, or Google Cloud Computing.Database-as-a-Service (DBaaS) offers turnkey managed functionality, which delegates all operational responsibilities to the provider.
Hosted VM databases are provisioned on virtual images, much like they would be on premises, and all operational responsibility belongs to the user.
Tip: Billing overruns are very easy when using a Database-as-a-service. Engage a usage/cost monitoring system to help manage expenses and to avoid nasty surprises.
Section 5
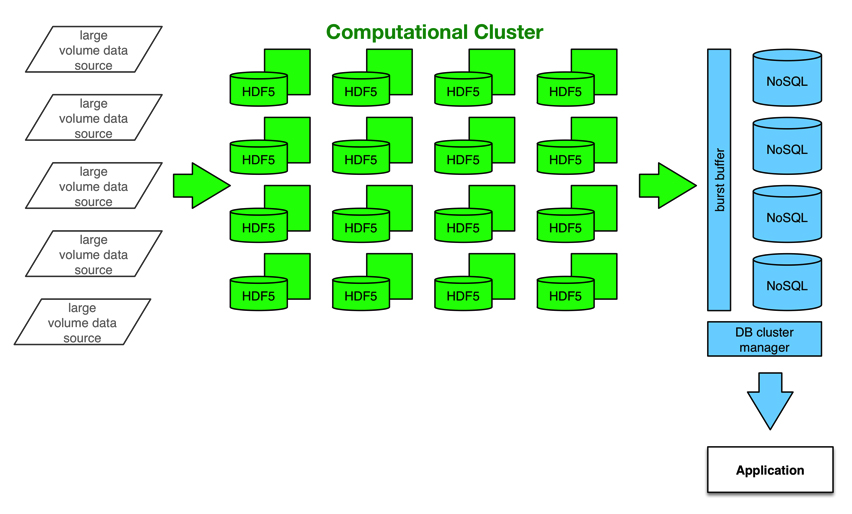
Very High-Volume Data Stores
Many applications require the storage of very large binary data sets. Traditional data stores can't handle them because their size makes it impractical. Enter the High-Volume Data Store (HVDS).Most very high-volume data applications are used in scientific or financial problem domains. These applications rely on dedicated, optimized binary data formats that allow quick access, manipulation, and data format description
within a single scope.
High-Volume Data Characteristics
Very large data setsMultidimensional distribution
Most data is numerical
Batch processing (including Hadoop) is optimal
Strong typing
HVDS Characteristics
Provided data structures (atoms, groups, arrays)Persistence management
Self-describing mechanisms to store the data, obviating versioning issues
ACID (Atomicity, Consistency, Isolation, Durability) properties
Language independence
No query language—access to structures is application and language/API dependent
No security model
Application or access APIs must provide concurrency
Rule of Thumb: High-Volume Data Stores handle very few I/O operations, but each consists of very large amounts of data; NoSQL handles lots of I/O operations on small amounts of data.
Data is stored in HVDS prior to initial processing, where the HVDS API provides more efficient access than the file system or a database system. The intermediate or final results move to NoSQL or relational stores for end-user
reporting and manipulation.
HVDS maps onto local files, like Hadoop's HDFS, allowing volumes to move between files systems (e.g. HFS+ to NTFS) without issues. Most HVDS originates in scientific research organizations, and portability is a primary design
concern.
HVDS Workflow
Section 6
Document Database: Couchbase Server
Couchbase Server is a document-based database that bridges the gaps between scalable key-value stores, relational database querying, and robustness capabilities. Its characteristics include:Document-oriented storage – data is manipulated as JSON documents
Querying – uses a robust query language with document handling semantics, N1QL
Multi-dimensional scalability (MDS) – different components may scale up or out, depending on load and performance required
MapReduce – built-in, indispensable for querying on non- indexed document attributes
Caching – integrated across all database services
Replication – transparent replication across multiple data centers
Spatial views – handles geometric, geospatial data definitions and allows mapping of attributes to multidimensional indices (e.g. table-like)
Couchbase Server provides datacenter consistency and partition tolerance. The database is based on the independent scaling and replication model shown in Figure 5. Data is handled across 3 different service zones: indexing, querying,
and data.
The service zones have different scalability requirements according to their function.
The Couchbase Server software and general documentation is athttp://docs.couchbase.com/admin/admin/Couchbase-intro.html.
Each database service node can replicate data to its peer, and each cluster can replicate to other clusters. Couchbase Server provides facilities for cross datacenter replication (XDCR), simplifying disaster recovery, high availability,
and data locality scenarios.
In-Memory Cache == Higher Performance
Couchbase Server performs very well during writes because it uses a memory-first mechanism. Data is written to the in- memory cache with a fast response to the caller. Couchbase Server asynchronously replicates the data to othernodes or clusters, updates the indices, and persists the data to disk. Database clients may override any of these operations to make them synchronous.
A read request is guaranteed to always get the most recent result at the time of the beginning of the request.
Document Format
Couchbase Server handles JSON documents. Being a schemaless database, any valid document can be committed to the database. Couchbase Server assigns two additional attributes to each document upon creation for tracking the document’sunique ID (_id) and revision number (_rev). These attributes are required for all operations other than creation. A typical document and its cross-language representation could be:
{"type" : "Person",
"name" : "Tom",
"age" : 42
}
Dynamic languages offer a closer object mapping to JSON than compiled languages.
Tip: "type" is just a JSON attribute in this example. It's good practice to define a document type to simplify queries, but it isn't required.
Views
Views are the primary query and reporting tool in Couchbase Server. A view is just a JavaScript function that maps view keys to values. Views are stored on the server and used when needed. They are only updated upon request (queryor report), not upon document creation or updates. For example, in a database that contains Person and Animal objects, a view for listing all the instances of “Person” could be:
function (d) { // d ::= documentif (d.type == "Person")
emit(d.name, { d.name, d.age });}
The output will be something like this:
{ "total_rows": 1,"offset": 0, "rows":[ { "id": "6921", "key": "Tom","value": {"name": "Tom",
"age": 42 } } ] }
View operations are defined in terms of MapReduce techniques.
Stream-Based Views
Couchbase Server also introduced stream-based views based on the Data Change Protocol (DCP). A stream-based view submits the query to the managed cache. The managed cache asynchronously updates the disk queue, the actual disk,or replicates the query to another node.
View queries may include the stale data freshness flag with one of these settings:
false – waits for the indexer to commit changes corresponding to the current key-value document set before returning the latest entries from the view index
responses may include up-to-date latest results that haven’t been committed to disk
update_after – returns the current index entries, then initiate an index update
ok – returns the current entries from the index
A configurable, automatic process updates the indices at configurable intervals based on whether changes within a threshold have occurred.
Spatial Views
Couchbase Server enables the creation of multi-dimensional spatial indices containing geometry data that can express information based on geometries within a multidimensional range. Some examples include:Geographical data for mobile, map, or other geo-location applications
Geometrical data for statistical analysis and data science applications
Arbitrary multidimensional collections for handling tables in a manner similar to how relational and column databases map structured and semi-structured data to schemas
The spatial views reference covering geospatial and arbitrary data collections information is available from http://docs. couchbase.com/4.0/admin/Views/spatial-views.html
N1QL – A SQL-Like Language for Documents
While views are powerful, they are somewhat cumbersome to manage. Couchbase Server introduced N1QL (pronounced “nickel”) to ease integration with legacy reporting systems and to assist programmers in unleashing more efficient,maintainable, and robust queries. Its main features include:
JSON attributes string concatenation and matching in SELECT statements
Ability to remove duplicate but valid results through the DISTINCT keyword (e.g. COUNT (DISTINCT someID))
Semantics for handling document missing values—a valid NoSQL construct—to test conditions similar to IS NULL in SQL
Dot-notation and ARRAY semantics for addressing JSON document attributes in query results
JOIN, NEST, and UNNEST capabilities specific to handling variable column JSON result sets
The N1QL example in Figure 6 shows the language’s flexibility in dealing with schemaless documents: Download the full Refcard for more info, and check out a Couchbase Server N1QL quick reference at http://query.couchbase.com
Couchbase Server Common Applications
Caching - more robust capabilities, indexing, and persistence with built-in replication and HAReal-time analytics - RDBMS may be too expensive or slow to run in comparison
Content management systems - JSON objects can represent any kind of document, including those with a binary representation
Named entity index – for scalable semantic search and machine learning applications
Couchbase Server Drawbacks
Complex queries - some complex queries and indices that require pivot tables are better suited for SQL or graph databases than for N1QL or ViewsNo full text search
No built-in collections or tables – ad hoc attribute definitions are used for logical groupings; spatial views and new N1QL features help in table creation but are harder than native collection/table support in other database
technologies
Section 7
Graph Database: Neo4j
Neo4j is an embeddable database with transactional capabilities that stores data in graphs. Entities are stored as graph nodes, and relationships between nodes are stored as edges connecting them. Its main features include:Relationships and nodes have the same priority during searches
Relationships are first class objects, not compound constructs like joins, and look up tables in other databases
High performance through memory mapping of entities and indices
ACID and transactional integrity
Cypher, an expressive and efficient declarative language for querying the database
The Neo4j downloads and documentation are available from:http://neo4j.com .
Figure 7 shows how Neo4j may be embedded in a JVM-based application, where Neo4j exposes a set of Java packages to make direct calls to the database.
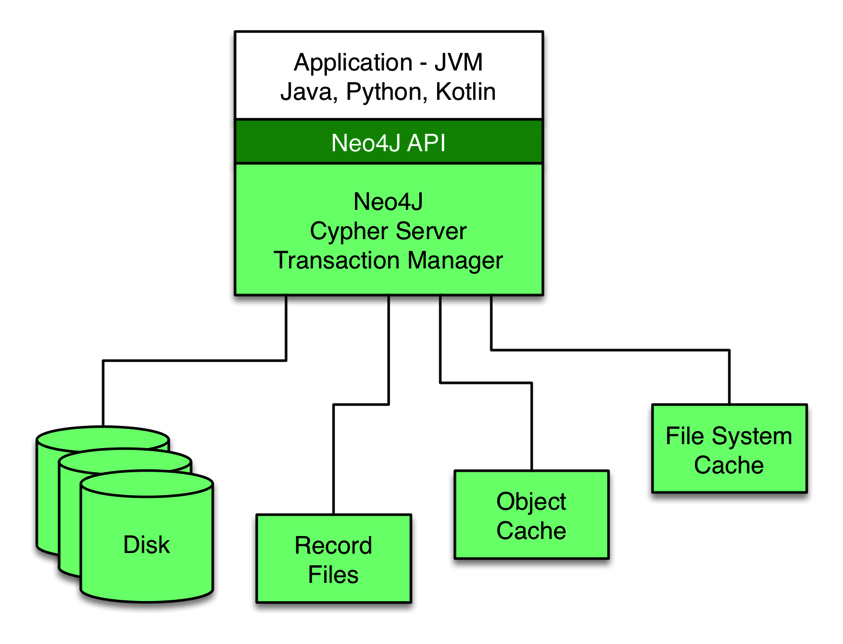
The Neo4j stand-alone configuration in Figure 8 exposes a RESTful API and runs on dedicated servers to optimize memory usage since objects and indices are memory-mapped.
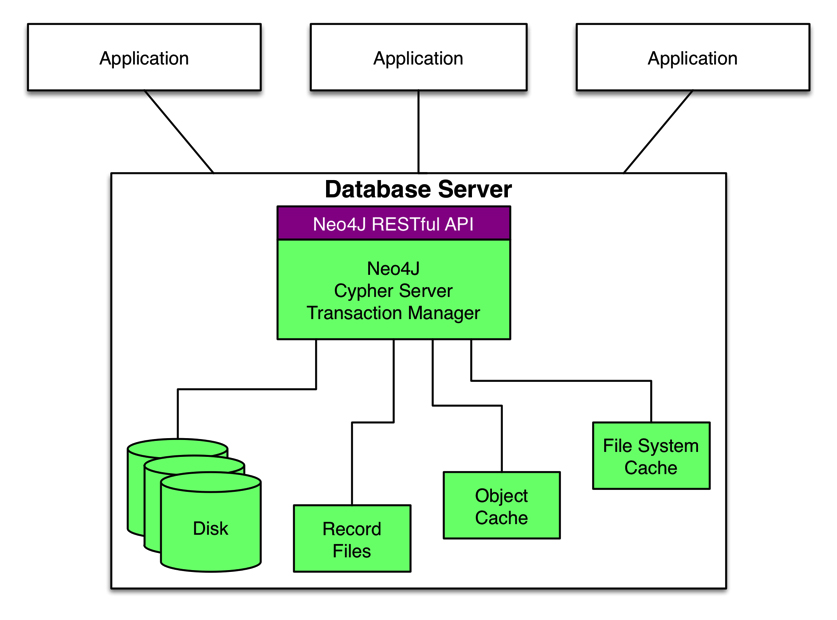
Tip: Neo4j is available under commercial and open-source licenses. Commercial options include a high availability cluster configuration.
Caching
Neo4j excels at content delivery and query speed because it offers two different caches:Low-level – file system cache for data stored in the actual medium; it's configured to assume that the database runs in a dedicated server
Objects – cache of individual nodes and relationships optimized for quick graph traversal
Both caches have a number of configuration options; consult the Neo4j web documentation for details.
Core: Property Graph
The property graph is made up of nodes, relationships, and properties. A graph database manages all the storage and searching aspects of property graph traversal.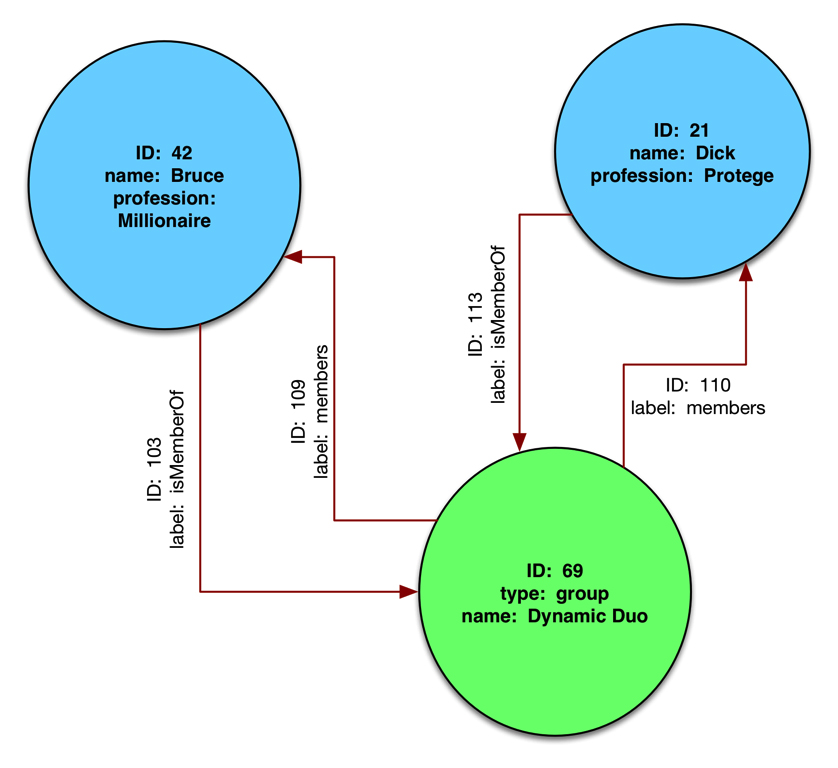
Nodes are aggregations of properties
Properties are arbitrary key-value pairs
Keys must be strings
Relationships connect nodes in a directed graph with a start and an end node:
No dangling relationships allowed!
Relationships also have properties, often in the form of metadata that aids in graph manipulation and defining run-time query constraints
Source: Graph Databases, Robinson, Webber, & Eifrem, O'Reilly, 2014
Querying Neo4j With Cypher
Cypher is a declarative query language specific to Neo4j that describes database operation patterns. It's loosely based on SQL, though it features ASCII text constructs to represent patterns and directionality.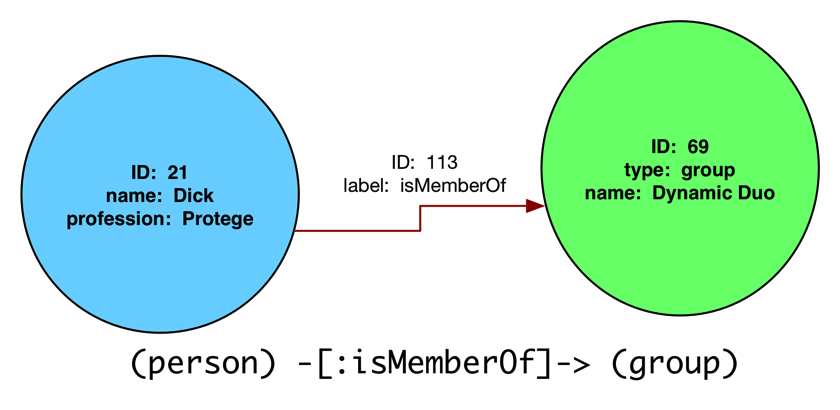
Cypher enables users to describe what to create, update, delete, or select from the graph without requiring an explicit description of how to do it. It describes the nodes, attributes, and relationships in the property graph.
Parentheses encapsulate a node
Operators show directionality arrows and attributes
SQL-like statements describe database operations
Check out the DZone Refcard Querying Graphs with Neo4j for more details on writing queries with Cypher, available athttp://refcardz.dzone.com/refcardz/querying-graphs-neo4j.
Cypher and Java
Cypher queries can be executed as payloads in RESTful calls or through the various native language wrappersDatabase operations are made more efficient if Neo4j is embedded mode if the program make direct calls the Neo4j Java API, bypassing the RESTful API and Cypher; all Cypher operations have counterparts in the Java API
Common Use Cases
Recommendations – e-commerce, social media, entertainmentRoute optimization – actual geographical routes or operations research algorithms
Logistics – B2B, disaster management
Authorization and access control– better capabilities than traditional LDAP and other ACL
Finance – stock analysis, historical performance analysis
Named entity analysis – semantic web, fraud detection, natural language processing
Neo4j Drawbacks
Poor horizontal scalability for load distributionCypher lacks end-user exact traversal patterns definition
Lack of support for composite keys
No auto-sharding – users must model the property graphs, databases, and server allocations manually
Section 8
Staying Current
Do you want to know about specific projects and use cases where NoSQL and data scalability are the hot topics? Follow the author's data science and scalability feed:http://twitter.com/ciuranaSection 9
PUBLICATIONS
By Eugene CiuranaDZone Refcard #105: NoSQL and Data Scalability
DZone Refcard #43: Scalability and High Availability
DZone Refcard #128: Apache Hadoop Deployment
DZone Refcard #117: Getting Started with Apache Hadoop
Developing with Google App Engine, Apress
DZone Refcard #38: SOA Patterns
The Tesla Testament: A Thriller, CIMEntertainment
From:https://dzone.com/refcardz/nosql-and-data-scalability-20

相关文章推荐
- MySQL查询优化之COUNT()
- sqlite数据下载链接地址
- mysql之DCL(GRANT、REVOKE)和mysql用户密码相关
- LabVIEW中查询数据库的数值,或读取excel表格中的数值时,不显示小数点前面0的解决办法
- Oracle优化器
- mysql常用操作
- oracle 取左表不在右表记录的3种方法-引申到db2-开发系列(五)
- mybatis性能优化之减少数据库连接
- 作业配置规范文档[MS SQL]
- 数据库的最简单实现
- oracle 11g下载详述
- mysql一个超级简单的事务
- html mysql special character
- oracle 11g下载详述
- Mysql执行计划
- 理解MySQL——索引与优化
- Oracle查看对象空间使用情况show_space
- 小贝_redis list类型学习
- MySQL的用户和权限介绍
- mysql cursor 游标