机器学习(吴恩达授课)课堂笔记(1)- Intro
2015-08-02 12:40
281 查看
Intro
机器学习在日常生活中很常见,例如社交网络可以自动圈出你的好友,邮箱可以自动过滤垃圾邮件。机器学习源于AI(人工智能)。它赋予计算机一种新的能力:自我学习,而非依靠程序。更多的例子:
数据挖掘
例如网页点击数据,医疗数据
不能靠人工编写代码的应用
例如识别手写,大部分的NLP(自然语言处理Natural Language Processing), 计算机视觉识别
<
4000
li>个性化自定义的程序
例如像亚马逊还有很多电商的产品自动推荐
理解人如何进行学习
涉及到人脑的模拟,真正的人工智能
Definition of Machine Learning
“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.”- Tom Mitchell (1998)如果计算机程序执行某项任务(Task T)的绩效(Performance P)随着经验(Experience E)增长而提高,则该计算机程序是通过学习经验来完成任务的。
根据这个定义,我们可以对应比较邮件处理系统通过机器学习来过滤垃圾邮件
任务(T)
邮件分类为垃圾邮件和非垃圾邮件
经验(E)
观察你如何标记垃圾邮件或非垃圾邮件
绩效(P)
正确被归类到垃圾邮件/非垃圾邮件的数量(或比例)
邮件系统通过观察学习,能更好地过滤垃圾邮件
Machine Learning Algorithms
1 监督学习(Supervised Learning)
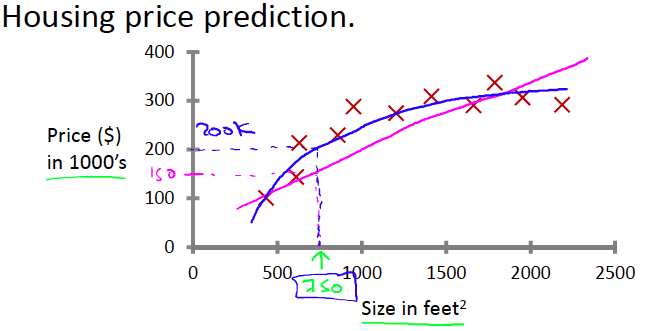
数据集(DataSet)里的每个样本(可以理解为输入数据)都有相应的“正确答案”(可以理解为实际的输出数据),再根据这些样本做预测。(1) 回归预测(Regression)
预测连续的结果值 Predict continuous valued output例子: 房屋售价预测
| 面积(样本) | 价格(“正确答案”) |
|---|---|
| 500 | $100 |
| 1000 | $300 |
| 2000 | $300 |
| … | … |
(2) 分类预测(Classification)
预测离散的结果值Predict discret valued output(0 or 1)例子: 乳腺癌预测
| 肿瘤大小 | 良性 | 恶性 |
|---|---|---|
| size1 | 0 | |
| size2 | 0 | |
| size3 | 1 | |
| … |
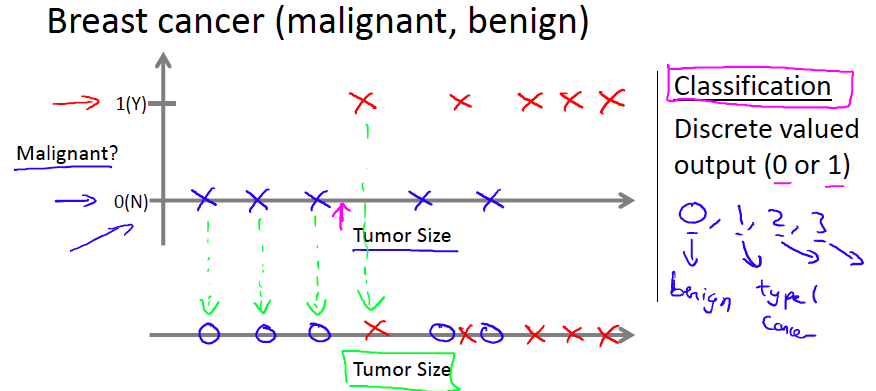
*在讲分类预测时,提到了一种算法叫做支持向量机(Support Vector Machine) 不明白是什么,等后续课程再了解。
2 无监督学习(Unsupervised Learning)
是一种自动聚类算法(Cluster Algorithm)给出一堆数据(并不像监督学习里的数据集,每个样本已经有自己的“正确答案”),无监督学习算法需要自动找到数据的结构,然后自动聚类。常见的例子:
google News
自动进行新闻分类
Organize Computing Cluster
哪些计算机可以协同工作
Social Network Analysis
自动给出朋友的分组
Market Segmentation
给出客户信息,自动归类到细分市场
练习题


参考目录
Intro
Definition of Machine Learning
Machine Learning Algorithms
监督学习Supervised Learning
1 回归预测Regression
2 分类预测Classification
无监督学习Unsupervised Learning
练习题

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- 也谈 机器学习到底有没有用 ?
- 量子计算机编程原理简介 和 机器学习
- 一个游戏程序员的学习资料
- D-Wave量子计算机有可能引爆人工智能革命吗?
- 50年后人工智能将成为人类最大的威胁
- 人工智能与智能系统的先驱人物
- 人工智能与智能系统的先驱人物
- 人工智能与智能系统的先驱人物
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 支持向量机(SVM)算法概述
- 神经网络初步学习手记
- 开始spark之旅
- spark的几点备忘
- 关于机器学习的学习笔记(一):机器学习概念
- 人工智能冲击下,IT人员如何提前避免被淘汰?