彻底弄懂计算机中的大端小端
2015-08-01 10:12
393 查看
大端与小端这个问题在做和其他设备交换原始字节数据的时候是非常重要的概念,也是必须要掌握的内容,但是很多人就是仅仅是稍微有些了解,但每次真正去做东西的时候,还是要花半天去想,博主就是这样的人,出现这样问题的真正原因是还没有完全弄清楚大端小端。今天就让我们一起彻底的弄懂这两个东西吧!
我希望这篇文章的读者起码要知道大端小端是干什么的,不然看了效果也不会很好
一个句话解释什么是大端,什么是小端
在用英文属于解释就是,most significant (最高有效位)在低地址位就是大端,(least significat) 在高地址位就是小端,看完这句话,你是不是清楚了什么是大端,什么是小端了呢? 正常人的反应会是,哎呀,我操,这都是些啥啊?不但没有更清楚,反而更晕了,我开始看到这样的解释也是这样的反应。
再来一个问题,彻底搞晕你(放心,我会把你搞清醒的^__^)
示例用C来描述
请问上面的代码中 例1 是大端还是小端 , 例2 是大端还是小端,例3 是大端还是小端 ,我希望到这里我已经成功的将你 搞晕 了。
我们先来看例1 ,我们都知道在C中short 占用两个字节,我们这里给这两个字节赋值为0x12 和0xFF,在计算机中内存是一个个的字节单元。
好了问题又来了,这两个字节在内存中是如果放的呢,假如 num1的 起始地址是 0x0056A100, 那么存放num1内容的应该是 0x0056A100和0x0056A101,但是哪个是0x12 ,哪个是0xFF呢? 我们写一段代码来看一下
程序很简单,就是分别打印两个字节的内容,低字节是address,高字节是address+1 , 我们来看一下 运行结果
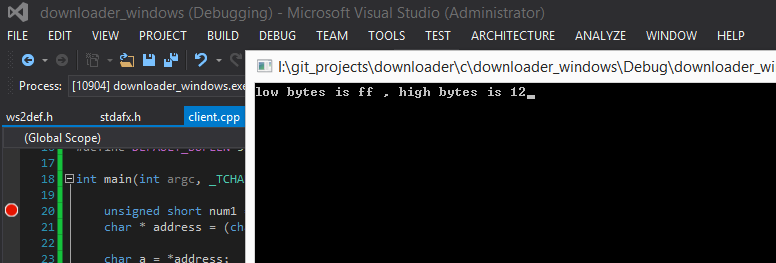
可以看到低位地址是0xFF高位是0x12,num1 这个数的高位12 存在了内存的低地址处,低位FF存在高地址处, 所以我们的机器 是小端的机器,其实只要确定内存的低地址存放的是高位还是低位就行了,这里低地址是0xFF(低位),所以是小端。代表我们的机器是小端机器,严格的说是CPU处理数据的方式采用的是小端法。
大端小端和字符串没有任何关系
-了解网络是怎样发送数据的?
我们使用的网络协议很多都是基于socket的,所以我们基于socket来讲,在socket规范中发送数据是 这个方法
send(Socket soc, char * buf, len , 0);
第一个参数是对方的socket,也就是地址
第二个参数是 一个字符指针,也就是要发送的内容存放的地址
第三个是发送数据的长度
第四个是和选择协议相关的,一般设为0
所以这里我们看到在底层发送数据的方法里面根本没有和什么大端小端有关系的东西,发送的函数只关心你要老子发送的东西在哪儿,发多少,其他一概不管,好,现在用一个场景说明一下。程序员A把一个金额发给程序员B,这个金额是B欠A钱的金额。
接收和发送的函数方法参数是一样的
recv(Socket soc, char * buf, len , 0);
好,这个数目发完了,B接收的时候用下面的代码
好了,数据发送和接受都完成了,到这里为止,和大小端半毛钱关系都没有,接下来就有了。这B想看看到底欠了A多少钱了,用下面的代码接收。
一看吓了一跳 56325,这就出大问题了,B心想,A是我铁哥们儿,肯定不会骗我,肯定是那个地方数据出错了,于是有了下面的对话
B:兄弟你电脑CPU是什么的?
A:是intel的啊
B:发送数据的时候有做什么处理吗?
A:没有做任何处理
B:额,我明白了
刚好B的机器也是Intel的CPU,B找到原因之后背了一遍我编写的口诀,低地址是低位是小端,低低地址是高位为大端。
B分析了一下数据的发送流程,A发送两个字节的short型数据,因为A是小端所以,先发送过来的是低位数据,后发送的是高位,我先接收的也是低位,后接收的是高位。
B修改程序后
一看,额,1500,心里松了一口气,这就对了。我们来看看出现刚刚这个问题的原因。
A是 Intel CPU (小端机器), 0x05DC这个数,低地址存放的是DC,高地址是05, B接受了放在 字符数组中, 因为B也是小端机器,B还原数据的时候是在低地址放在了高位,也就是0xDC,这是 不对的。
那总不能每次发送数据都问一下别人是什么CPU吧?
于是人们就约定将数据的低地址处放数据的高位(也叫大端法),于是A就遵循了这个约定, 发送之前将数据位置改了一下,因为之前低地址放的是低位。之前A的数据是这样放的
因为约定采用大端法发送数据,所以要改成下面这样
如果遵守约定,B就不用问A你的机器是什么类型了,但是还有一个问题,因为B的机器类型可能是大端也可能是小端,那接受数据的时候还要去判断机器类型,这也太麻烦了,对,没错,底层的网络处理就是这么麻烦。
还有从网络字节序转成本机字节序的方法
先就将到这里,如有错误,请大家批评
先讲讲关于这两个东西的传说吧(也是抄来的^_^)
“大端”和“小端”可以追溯到1726年的Jonathan Swift的《格列佛游记》,其中一篇讲到有两个国家因为吃鸡蛋究竟是先打破较大的一端还是先打破较小的一端而争执不休,甚至爆发了战争。1981年10月,Danny Cohen的文章《论圣战以及对和平的祈祷》(On holy wars and a plea for peace)将这一对词语引入了计算机界。这么看来,所谓大端和小端,也就是big-endian和little-endian,其实是从描述鸡蛋的部位而引申到计算机地址的描述,也可以说,是从一个俚语衍化来的计算机术语。稍有些英语常识的人都会知道,如果单靠字面意思来理解俚语,那是很难猜到它的正确含义的。在计算机里,对于地址的描述,很少用“大”和“小”来形容;对应地,用的更多的是“高”和“低”;很不幸地,这对术语直接按字面翻译过来就成了“大端”和“小端”,让人产生迷惑也不是很奇怪的事了。我希望这篇文章的读者起码要知道大端小端是干什么的,不然看了效果也不会很好
一个句话解释什么是大端,什么是小端
在用英文属于解释就是,most significant (最高有效位)在低地址位就是大端,(least significat) 在高地址位就是小端,看完这句话,你是不是清楚了什么是大端,什么是小端了呢? 正常人的反应会是,哎呀,我操,这都是些啥啊?不但没有更清楚,反而更晕了,我开始看到这样的解释也是这样的反应。
再来一个问题,彻底搞晕你(放心,我会把你搞清醒的^__^)
示例用C来描述
例1 :short num1 = 0x12FF; 例2 :char * str1 = "abcde"; 例3 :数字32的 short 十六进制: 00 20
请问上面的代码中 例1 是大端还是小端 , 例2 是大端还是小端,例3 是大端还是小端 ,我希望到这里我已经成功的将你 搞晕 了。
根本原则,大端小端是针对于存储而言的,和字面的表达方式没关系
所以之前我提的问题全是些伪命题,而计算机中大端小端真正的含义要在存储中讲才能讲明白。我们先来看例1 ,我们都知道在C中short 占用两个字节,我们这里给这两个字节赋值为0x12 和0xFF,在计算机中内存是一个个的字节单元。
好了问题又来了,这两个字节在内存中是如果放的呢,假如 num1的 起始地址是 0x0056A100, 那么存放num1内容的应该是 0x0056A100和0x0056A101,但是哪个是0x12 ,哪个是0xFF呢? 我们写一段代码来看一下
int main(int argc, _TCHAR* argv[]){
unsigned short num1 = 0x12FF;
char * address = (char *)&num1;
printf("low bytes is %x , high bytes is %x",*address & 0xFF, *(address + 1) & 0xFF );
}程序很简单,就是分别打印两个字节的内容,低字节是address,高字节是address+1 , 我们来看一下 运行结果
可以看到低位地址是0xFF高位是0x12,num1 这个数的高位12 存在了内存的低地址处,低位FF存在高地址处, 所以我们的机器 是小端的机器,其实只要确定内存的低地址存放的是高位还是低位就行了,这里低地址是0xFF(低位),所以是小端。代表我们的机器是小端机器,严格的说是CPU处理数据的方式采用的是小端法。
字符串中又是怎样的情况呢?
char * a = “abcd”;#
其实在程序中字符串并没有大端小端并之说,只有在涉及到数据的传输时,字符串的大端小端才值的注意,我们后面会探讨这一问题,但很多教材或者是博客都直接把整型和字符串的大小端放在一起讲,就容易更让人搞不清楚。这里的d肯定是存放在高地址,a肯定是存放在低地址。大端小端和字符串没有任何关系
网络中的大端与小端
可能上面的内容你已经搞清楚了,但是当你看一些关于网络或者的资料时发现又有什么网络字节序神马的,然后又糊涂了,让我们一起来破除关于网络字节序列这些神马的浮云。-了解网络是怎样发送数据的?
我们使用的网络协议很多都是基于socket的,所以我们基于socket来讲,在socket规范中发送数据是 这个方法
send(Socket soc, char * buf, len , 0);
第一个参数是对方的socket,也就是地址
第二个参数是 一个字符指针,也就是要发送的内容存放的地址
第三个是发送数据的长度
第四个是和选择协议相关的,一般设为0
所以这里我们看到在底层发送数据的方法里面根本没有和什么大端小端有关系的东西,发送的函数只关心你要老子发送的东西在哪儿,发多少,其他一概不管,好,现在用一个场景说明一下。程序员A把一个金额发给程序员B,这个金额是B欠A钱的金额。
//A发给B,这是B欠我A的数目 ,是1500元,下面是十六进制写法 short a = 0x05DC; //于是A就 send(sock, (char *)&a,2,0);
接收和发送的函数方法参数是一样的
recv(Socket soc, char * buf, len , 0);
好,这个数目发完了,B接收的时候用下面的代码
char ownMoney [2]; recv(Socket soc,ownMoney, 2 , 0);
好了,数据发送和接受都完成了,到这里为止,和大小端半毛钱关系都没有,接下来就有了。这B想看看到底欠了A多少钱了,用下面的代码接收。
int total = ((ownMoney[0] << 8) | (ownMoney[1] & 0xFF ) &0xFF );
一看吓了一跳 56325,这就出大问题了,B心想,A是我铁哥们儿,肯定不会骗我,肯定是那个地方数据出错了,于是有了下面的对话
B:兄弟你电脑CPU是什么的?
A:是intel的啊
B:发送数据的时候有做什么处理吗?
A:没有做任何处理
B:额,我明白了
刚好B的机器也是Intel的CPU,B找到原因之后背了一遍我编写的口诀,低地址是低位是小端,低低地址是高位为大端。
B分析了一下数据的发送流程,A发送两个字节的short型数据,因为A是小端所以,先发送过来的是低位数据,后发送的是高位,我先接收的也是低位,后接收的是高位。
B修改程序后
int total = (ownMoney[0] &0xFF ) | ( (ownMoney[1] << 8) & 0xFF ) );
一看,额,1500,心里松了一口气,这就对了。我们来看看出现刚刚这个问题的原因。
A是 Intel CPU (小端机器), 0x05DC这个数,低地址存放的是DC,高地址是05, B接受了放在 字符数组中, 因为B也是小端机器,B还原数据的时候是在低地址放在了高位,也就是0xDC,这是 不对的。
那总不能每次发送数据都问一下别人是什么CPU吧?
于是人们就约定将数据的低地址处放数据的高位(也叫大端法),于是A就遵循了这个约定, 发送之前将数据位置改了一下,因为之前低地址放的是低位。之前A的数据是这样放的
| 低地址 | 高地址 |
|---|---|
| DC | 05 |
| 低地址 | 高地址 |
|---|---|
| 05 | DC |
//这样改变位置的代码 short a = 0x05DC; //用一个字符指针指向a char* pointerOfA = (char *)&a; //把数据的低位值保存在一个变量里,也就是 DC char temp = *(pointerOfA ); //把高位的值放在低位 *pointerOfA = *(pointerOfA +1); *(pointerOfA +1) = temp; //再发送 send(sock, pointerOfA ,2,0);
如果遵守约定,B就不用问A你的机器是什么类型了,但是还有一个问题,因为B的机器类型可能是大端也可能是小端,那接受数据的时候还要去判断机器类型,这也太麻烦了,对,没错,底层的网络处理就是这么麻烦。
让世界更美好
这个世界变得越来越美好,是因为有前人无私的付出,计算机的世界也一样,在大小端数据转换中也有实现好了的函数,只等着你去调用。htons(unsigned short n):将short转为网络字节序 htonl(unsigned long n) : 将long转为网络字节序 htons 意思就是host to network ,后面一个代表数据类型
还有从网络字节序转成本机字节序的方法
ntohl ntohs
先就将到这里,如有错误,请大家批评

相关文章推荐
- 常见HTTP状态(304,200等)
- POJ1087(网络流,二分图匹配)
- 解决Android Studio Import Sample网络连接失败问题
- HTTP 方法:GET 对比 POST
- http各种状态码详解
- 计算机网络读书笔记-----应用层
- 无锁数据结构(Lock-Free Data Structures)
- 计算机网络读书笔记-----UDP vs TCP
- java网络编程(4)——udp实现聊天
- inux内核数据结构之kfifo
- 计算机网络读书笔记-----传输层
- TCP通信丢包原因总结
- kernel中常用数据结构之kfifo(改造为ring buffer)
- kernel中常用数据结构之链表
- 数据结构导论——泛读
- HttpClient详解(三)—get post封装实例
- HttpClient详解(二)—请求详解
- 计算机网络读书笔记-----数据链路层的可靠性
- 神经网络-并行BP算法
- 没必要对央行网络支付办法恐慌