SQL Server里Grouping Sets的威力
2015-07-30 08:06
375 查看
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务)。我不是说在生产里使用开发版,也不是说安装盗版SQL Server。
不可能的任务?未必,因为通过SQL Server里所谓的Grouping Sets就可以。在这篇文章里我会给你概括介绍下Grouping Sets,使用它们可以实现哪类查询,什么是它们的性能优势。
在每列分组
GROUP BY SalesPersonID, YEAR(OrderDate)
GROUP BY CustomerID, YEAR(OrderDate)
GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
当你想用传统T-SQL查询进行这些各自分组时,你需要多个语句,对各个记录集进行UNION ALL。我们来看这样的查询:
用这个T-SQL语句方法有多个缺点:
T-SQL语句本身很庞大,因为每个单独分组都是一个不同查询。
每查询1次,[b]Sales.SalesOrderHeader[/b]表需要访问4次。
每查询1次,你在执行计划里会看到SQL Server进行了4次的[b]索引查找(非聚集)(Index Seek (NonClustered) )[/b]。

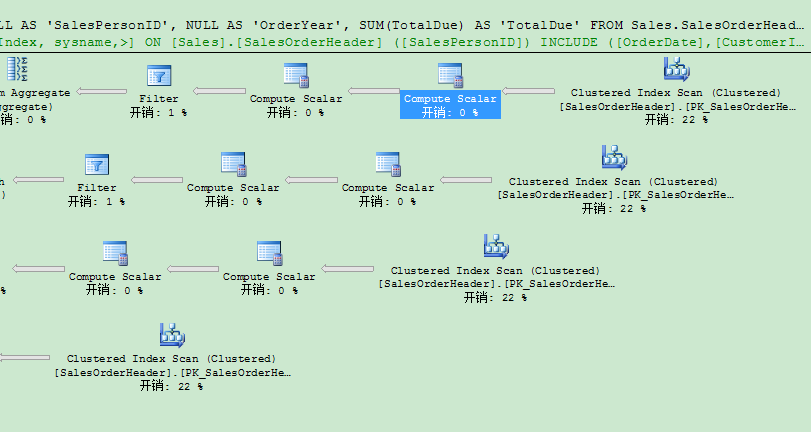
如果你使用自SQL Server 2008以后引入的grouping sets功能,就可以大大简化你需要的T-SQL代码。下面代码展示你同样的查询,但这次用grouping sets实现。
从代码本身可以看到,你只在GROUP BY GROUPING SETS子句里指定需要的分组集——其它的一切都由SQL Server搞定。指定的空括号是所谓的Empty Grouping Set,是跨整个表的聚集。当你看STATISTICS IO输出时,你会发现Sales.SalesOrderHeader只被访问了1次!这是和刚才手工实现的巨大区别。

在执行计划里,SQL Server使用了Table Spool运算符,它把获得的数据临时存储在TempDb里。来自临时表里创建的Worktable的数据在执行计划的第2个分支被使用。因此对来自表的每个分组数据没有重新扫描,这就给整个执行计划的带来了更好的性能。
我们再来看下执行计划,你会发现查询计划包含了3个[b]Stream Aggregate[/b]运算符(红色,蓝色,绿色高亮显示)。这3个运算符计算各个分组集:
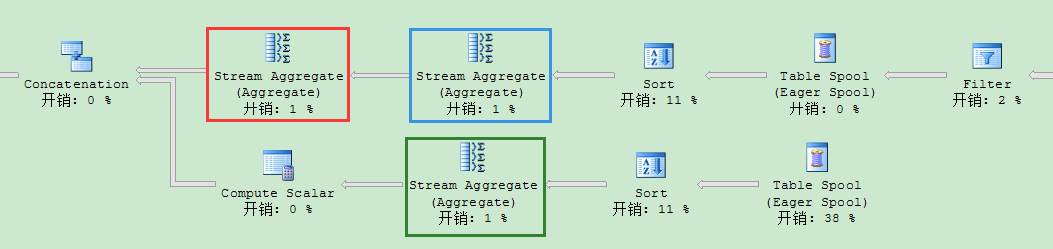
蓝色高亮的运算符计算[b]CustomerID, SalesPersonID, YEAR(OrderDate[/b]的分组集。
红色高亮的运算符计算[b]SalesPersonID, YEAR(OrderDate)[/b]的分组集。另外也计算每1列的分组集。
绿色高亮的运算符计算[b]CustomerID, YEAR(OrderDate)[/b]的分组集。
2个连续的Stream Aggregate运算符的背后想法是计算所谓的[b]Super Aggregates[/b]——聚集的聚集。
我希望现在你已经能够很好理解grouping sets,如果你能在你的数据库里使用这个功能可以在此留言,非常感谢!
感谢关注!
不可能的任务?未必,因为通过SQL Server里所谓的Grouping Sets就可以。在这篇文章里我会给你概括介绍下Grouping Sets,使用它们可以实现哪类查询,什么是它们的性能优势。
使用Grouping Sets的聚合
假设你有个订单表,你想进行跨多个分组的T-SQL聚集查询。在[b]AdventureWorks2012[/b]数据库的[b]Sales.SalesOrderHeader[/b]表的环境里,这些分组可以类似如下:在每列分组
GROUP BY SalesPersonID, YEAR(OrderDate)
GROUP BY CustomerID, YEAR(OrderDate)
GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate)
当你想用传统T-SQL查询进行这些各自分组时,你需要多个语句,对各个记录集进行UNION ALL。我们来看这样的查询:
SELECT * FROM ( -- 1st Grouping Set SELECT NULL AS 'CustomerID', NULL AS 'SalesPersonID', NULL AS 'OrderYear', SUM(TotalDue) AS 'TotalDue' FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL UNION ALL -- 2nd Grouping Set SELECT NULL AS 'CustomerID', SalesPersonID, YEAR(OrderDate) AS 'OrderYear', SUM(TotalDue) AS 'TotalDue' FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL GROUP BY SalesPersonID, YEAR(OrderDate) UNION ALL -- 3rd Grouping Set SELECT CustomerID, NULL AS 'SalesPersonID', YEAR(OrderDate) AS 'OrderYear', SUM(TotalDue) AS 'TotalDue' FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL GROUP BY CustomerID, YEAR(OrderDate) UNION ALL -- 4th Grouping Set SELECT CustomerID, SalesPersonID, YEAR(OrderDate) AS 'OrderYear', SUM(TotalDue) AS 'TotalDue' FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL GROUP BY CustomerID, SalesPersonID, YEAR(OrderDate) ) AS t ORDER BY CustomerID, SalesPersonID, OrderYear GO
用这个T-SQL语句方法有多个缺点:
T-SQL语句本身很庞大,因为每个单独分组都是一个不同查询。
每查询1次,[b]Sales.SalesOrderHeader[/b]表需要访问4次。
每查询1次,你在执行计划里会看到SQL Server进行了4次的[b]索引查找(非聚集)(Index Seek (NonClustered) )[/b]。
如果你使用自SQL Server 2008以后引入的grouping sets功能,就可以大大简化你需要的T-SQL代码。下面代码展示你同样的查询,但这次用grouping sets实现。
SELECT CustomerID, SalesPersonID, YEAR(OrderDate) AS 'OrderYear', SUM(TotalDue) AS 'TotalDue' FROM Sales.SalesOrderHeader WHERE SalesPersonID IS NOT NULL GROUP BY GROUPING SETS ( -- Our 4 different grouping sets (CustomerID, SalesPersonID, YEAR(OrderDate)), (CustomerID, YEAR(OrderDate)), (SalesPersonID, YEAR(OrderDate)), () ) GO
从代码本身可以看到,你只在GROUP BY GROUPING SETS子句里指定需要的分组集——其它的一切都由SQL Server搞定。指定的空括号是所谓的Empty Grouping Set,是跨整个表的聚集。当你看STATISTICS IO输出时,你会发现Sales.SalesOrderHeader只被访问了1次!这是和刚才手工实现的巨大区别。
在执行计划里,SQL Server使用了Table Spool运算符,它把获得的数据临时存储在TempDb里。来自临时表里创建的Worktable的数据在执行计划的第2个分支被使用。因此对来自表的每个分组数据没有重新扫描,这就给整个执行计划的带来了更好的性能。
我们再来看下执行计划,你会发现查询计划包含了3个[b]Stream Aggregate[/b]运算符(红色,蓝色,绿色高亮显示)。这3个运算符计算各个分组集:
蓝色高亮的运算符计算[b]CustomerID, SalesPersonID, YEAR(OrderDate[/b]的分组集。
红色高亮的运算符计算[b]SalesPersonID, YEAR(OrderDate)[/b]的分组集。另外也计算每1列的分组集。
绿色高亮的运算符计算[b]CustomerID, YEAR(OrderDate)[/b]的分组集。
2个连续的Stream Aggregate运算符的背后想法是计算所谓的[b]Super Aggregates[/b]——聚集的聚集。
小结
在今天的文章里我给你介绍了grouping sets,在SQL Server 2008后引入的增强T-SQL。如你所见grouping sets有2个大优点:简化你的代码,只访问一次数据提高查询性能。我希望现在你已经能够很好理解grouping sets,如果你能在你的数据库里使用这个功能可以在此留言,非常感谢!
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2014/09/15/the-power-of-grouping-sets-in-sql-server/
相关文章推荐
- iBatis + SQL Server 项目开发实战小结
- SQL Server里PIVOT运算符的”红颜祸水“
- sphinxse mysql 5.6编译错误
- MySQL-adv-02
- MySQl-adv-01
- postgresql9.5 物化视图测试
- SQL中,WHERE HAVING的区别
- 数据库服务器mysql性能调优
- 复盘eygle在甲骨文大会上演讲中的示例,看看什么是大师的由点及面
- 《一起学》系列11:Redis入门
- 系列11:Redis入门
- python如何实现excel数据添加到mongodb
- sql server 2000中禁止创建表(权限设置方法)
- sql server创建临时表的两种写法和删除临时表
- sql server 2000 数据库自动备份设置方法
- MYSQL中having和where的区别
- MySQL日期和时间函数讲解(以及时间转换)
- BDR 0.9.0版本测试
- mysql学习——基本语句
- Sqlite碰到的坑