信号与通信系统
2015-07-25 17:57
447 查看
话音和图像信号都是连续变化的模拟信号,把它们数字化是现代通信网络支
持各种通信业务的基础。
模拟信号数字化必须经过三个过程,即抽样、量化和编码。现以实现话音数
字化的脉冲编码调制(PCM,Pulse Coding Modulation)技术为例简要说明
如下:
1. 抽样(Samping)
抽样是把模拟信号以其信号带宽2 倍以上的频率提取样值,变为在时间轴上离散的抽样信号的过程。例如,话音信号带宽被限制在0.3~3.4 kHz 内,用8 kHz 的抽样频率(fs),就可获得能取代原来连续话音信号的抽样信号。
2. 量化(quantizing)
抽样信号虽然是时间轴上离散的信号,但仍然是模拟信号,其样值在一定的取值范围内,可有无限多个值。显然,对无限个样值一一给出数字码组来对应是不可能的。为了实现以数字码表示样值,必须采用“四舍五入”的方法把样值分级“取整”,使一定取值范围内的样值由无限多个值变为有限个值。这一过程称为量化。
量化后的抽样信号与量化前的抽样信号相比较,当然有所失真,且不再是模拟信号。这种量化失真在接收端还原模拟信号时表现为噪声,并称为量化噪声。量化噪声的大小取决于把样值级“取整”的方式,分的级数越多,即量化级差或间隔越小,量化噪声也越小。
3. 3. 编码(Coding)
量化后的抽样信号在一定的取值范围内仅有有限个可取的样值,且信号正、负幅度分布的对称性使正、负样值的个数相等,正、负向的量化级对称分布。若将有限个量化样值的绝对值从小到大依次排列,并对应地依次赋予一个十进制数字代码(例如,赋予样值0 的十进制数字代码为0),在码前以“+”、“-”号为前缀,来区分样值的正、负,则量化后的抽样信号就转化为按抽
样时序排列的一串十进制数字码流,即十进制数字信号。简单高效的数据系统是二进制码系统,因此,应将十进制数字代码变换成二进制编码。根据十进制数字代码的总个数,可以确定所需二进制编码的位数,即字长。这种把量化的抽样信号变换成给定字长的二进制码流的过程称为编码。
例如,话音信号的样值有±128(27=128)个,即256(28=256)个,对应的十进制数字代码为±(0~127),并可变换成字长8 位的二进制编码。通常,将二进制码元“0”或“1”的时长定义为1 比特(Bit),并将8 位二进制码称为一个字节(Byte)。
话音PCM 的抽样频率为8 kHz,每个量化样值对应一个8 位二进制码,故话音数字编码信号的速率为8 bits×8kHz = 64 kb/s。
量化噪声随量化级数的增多和级差的缩小而减小。量化级数增多即样值个数增多,就要求更长的二进制编码。因此,量化噪声随二进制编码的位数增多而减小,即随数字编码信号的速率提高而减小。
话音信号非均匀量化的必要性和实现方法
均匀量化是在抽样信号的取值范围内均匀划分量化等级的量化方法。它产生的量化噪声也是均匀的,与信号在取样点的幅度无关。因此,均匀量化会出现话音弱时的信噪比低、干扰大,而话音强时的信噪比高、干扰小的反常情况。原CCITT 有关建议求,在8 位二进制编码的条件下,话音的量化信噪比应大26dB。由于话音大都集中在小信号范围内,均匀量化编码在话音幅度小时不能满足信噪比大于26dB 的要求,而在话音幅度大时满足要求却卓卓有余。因此,在维持8 位二进制编码条件,即量化级总数不变的前提下,把话音的取值范围分成若干个区间,在样值小的区间增多量化级数,而在样值大的区间减少量化级数的非均匀量化方案就应运而生了。
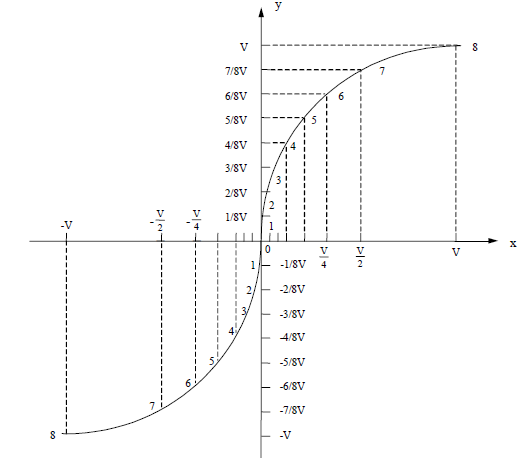
非均匀量化的实现方法通常有两种:一种是北美和日本的μ律压扩;另一种是欧洲和我国所采用A 律压扩。A 律压扩的13 折线分段方法如图所示 。Y 轴被均匀分为8 段,每段又分为16 份,每份表示一个量化级,则Y 轴一共有16×8=128 个量化级。X轴的划分与Y 轴不同,它用不均匀分段的方法以达到非均匀量化的目的,划分规律是每次按被分段长的二分之一来进行分段。
持各种通信业务的基础。
模拟信号数字化必须经过三个过程,即抽样、量化和编码。现以实现话音数
字化的脉冲编码调制(PCM,Pulse Coding Modulation)技术为例简要说明
如下:
1. 抽样(Samping)
抽样是把模拟信号以其信号带宽2 倍以上的频率提取样值,变为在时间轴上离散的抽样信号的过程。例如,话音信号带宽被限制在0.3~3.4 kHz 内,用8 kHz 的抽样频率(fs),就可获得能取代原来连续话音信号的抽样信号。
2. 量化(quantizing)
抽样信号虽然是时间轴上离散的信号,但仍然是模拟信号,其样值在一定的取值范围内,可有无限多个值。显然,对无限个样值一一给出数字码组来对应是不可能的。为了实现以数字码表示样值,必须采用“四舍五入”的方法把样值分级“取整”,使一定取值范围内的样值由无限多个值变为有限个值。这一过程称为量化。
量化后的抽样信号与量化前的抽样信号相比较,当然有所失真,且不再是模拟信号。这种量化失真在接收端还原模拟信号时表现为噪声,并称为量化噪声。量化噪声的大小取决于把样值级“取整”的方式,分的级数越多,即量化级差或间隔越小,量化噪声也越小。
3. 3. 编码(Coding)
量化后的抽样信号在一定的取值范围内仅有有限个可取的样值,且信号正、负幅度分布的对称性使正、负样值的个数相等,正、负向的量化级对称分布。若将有限个量化样值的绝对值从小到大依次排列,并对应地依次赋予一个十进制数字代码(例如,赋予样值0 的十进制数字代码为0),在码前以“+”、“-”号为前缀,来区分样值的正、负,则量化后的抽样信号就转化为按抽
样时序排列的一串十进制数字码流,即十进制数字信号。简单高效的数据系统是二进制码系统,因此,应将十进制数字代码变换成二进制编码。根据十进制数字代码的总个数,可以确定所需二进制编码的位数,即字长。这种把量化的抽样信号变换成给定字长的二进制码流的过程称为编码。
例如,话音信号的样值有±128(27=128)个,即256(28=256)个,对应的十进制数字代码为±(0~127),并可变换成字长8 位的二进制编码。通常,将二进制码元“0”或“1”的时长定义为1 比特(Bit),并将8 位二进制码称为一个字节(Byte)。
话音PCM 的抽样频率为8 kHz,每个量化样值对应一个8 位二进制码,故话音数字编码信号的速率为8 bits×8kHz = 64 kb/s。
量化噪声随量化级数的增多和级差的缩小而减小。量化级数增多即样值个数增多,就要求更长的二进制编码。因此,量化噪声随二进制编码的位数增多而减小,即随数字编码信号的速率提高而减小。
话音信号非均匀量化的必要性和实现方法
均匀量化是在抽样信号的取值范围内均匀划分量化等级的量化方法。它产生的量化噪声也是均匀的,与信号在取样点的幅度无关。因此,均匀量化会出现话音弱时的信噪比低、干扰大,而话音强时的信噪比高、干扰小的反常情况。原CCITT 有关建议求,在8 位二进制编码的条件下,话音的量化信噪比应大26dB。由于话音大都集中在小信号范围内,均匀量化编码在话音幅度小时不能满足信噪比大于26dB 的要求,而在话音幅度大时满足要求却卓卓有余。因此,在维持8 位二进制编码条件,即量化级总数不变的前提下,把话音的取值范围分成若干个区间,在样值小的区间增多量化级数,而在样值大的区间减少量化级数的非均匀量化方案就应运而生了。
非均匀量化的实现方法通常有两种:一种是北美和日本的μ律压扩;另一种是欧洲和我国所采用A 律压扩。A 律压扩的13 折线分段方法如图所示 。Y 轴被均匀分为8 段,每段又分为16 份,每份表示一个量化级,则Y 轴一共有16×8=128 个量化级。X轴的划分与Y 轴不同,它用不均匀分段的方法以达到非均匀量化的目的,划分规律是每次按被分段长的二分之一来进行分段。

相关文章推荐
- ZeroClipboard2.0 复制功能
- Java 内存的划分
- 特别篇-SetWindowExtEx,SetViewportExtEx解析
- C语言,变量与内存
- 编程语言的语法与语义
- Surface Pro 3/Surface 3升级Win10在某些零售店完成 win10正式版升级截图
- poj 1251 Jungle Roads
- python 简单日志文件
- C# 配置错误定义了重复的“system.web.extensions/scripting/scriptResourceHandler”节
- [Unity3D]Unity3D圣骑士当游戏开发商遭遇Mecanim动画系统
- emacs 新手笔记(三) —— 为 emacs 做一点简单的定制
- nodejs async 库使用
- Android.9图片评论(一个)
- 模拟器报Installation error: INSTALL_FAILED_CONTAINER_ERROR解决方法
- 一周感悟
- 分组背包
- POJ1988基本的并查集
- opencv像素基本操作及图像遍历at
- 浅谈tomcat的配置及数据库连接池的配置
- jquery基础认识