引跑科技副总裁张晓东:引跑DBone数据库助力大数据建设
2015-07-19 19:16
429 查看
点击上面的链接文字,可以快速关注“东方云洞察”公众号今天正好接受了一个媒体访谈,也趁这个契机把云计算洞察领域的内容扩充一下,以后会花些精力给大家介绍一下大数据领域的东西。

以下摘自CSDN媒体访谈稿件,过两天大家就会看到上线,今天我就先发了。 大数据经过几年的市场预热,目前应用案例已经逐步丰富起来,热度逐步上升。今天有幸我们请到了引跑信息科技有限公司(以下简称引跑科技)的副总裁,张晓东先生做一个访谈。张总在数据领域从业多年,以前在 IBM、Oracle、华为等公司工作多年,担任了数据库技术专家、资深云架构师、战略部高级总监等职位。从业经历丰富,今天有幸能与张总交流,非常难得。
下面我们以问答的形式来了解一下引跑科技公司在大数据的成功经验。
引跑公司在2008年成立,是由我们的创始人杨素东整合了一些来自国外Google、HP实验室的一些人才和力量构建的,杨总也获得了国家千人计划、中国云计算专家委员会等一系列荣誉。公司主要专注于做技术,以前和EMC、HP等公司有一些合作,并没有特意的在国内宣传,所以大家对我们不是很熟悉。目前我们拥有近300人的团队,其中75%是研发人员。引跑科技是全球领先的云计算技术与服务提供商,拥有大数据平台(EngineOne)、虚拟化平台(ScaleOne)、云应用平台(AppOne)、云管理平台(MasterOne)四大平台产品及不同行业云解决方案,并拥有多项核心发明专利与软件著作权。一下子说这么多名词大家可能有点晕,简单来说,我觉得引跑科技最核心的竞争力就是我们的并行分布式数据库产品DBone和分布式存储Storeone。在这两块领域,我们有信心和全球最顶尖的企业竞争。

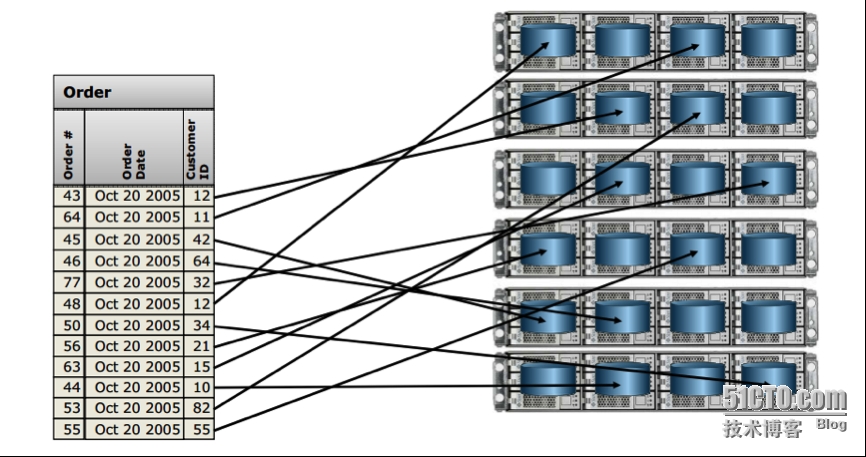
下图说明了DBOne分布式数据库系统大规模数据存储的基本原理和方法。
引跑的分布式数据库产品竞争对手主要是以Oracle Exadata、SAP HANA等产品为目标。适合的应用场景也主要以大数据分析为主,这种架构能够很好的解决超大表的查询、以及PB级别数据处理的性能问题,并能兼顾分布式事务处理的需求,当然强分布式事务的能力可不是哪个MPP数据库都具备的,引跑的DBone在这个领域还是很有核心能力的。相对于Hadoop等开源大数据处理解决方案,引跑的EnginOne大数据整体解决方案,能够很好的支持上亿级大表的嵌套查询,3-4层的嵌套查询能够很好的支持,通过两阶段提交的方式, 能很好的支持强事物。下面的表格列出了我们的大数据平台和Hadoop2.0为核心的解决方案对比。


早期我们借助了一些开源数据库产品的实现架构和部分功能代码,例如PostgreSQL、MySQL数据库等。分布式存储方面对于谷歌的GFS架构也有一定的参考,但是代码都是我们经过几年的不断改进积累下来的,目前已经完全实现的自主可控,在某些军方项目上都严格的做过和开源软件的代码比对,这对我们是最好的肯定。
最后,我想说,越来越多的公司在大数据领域寻找发展的机会或是提升运营的效率,这说明企业有着向数据驱动的商业模式转型的需要。所以,大数据时代的企业应该采取以下的公式:新技术+新观念+商业转型=大数据策略。大数据技术和商业的结合刚刚开始,未来的发展非常值得期待。

扫描二维码关注【东方云洞察】公众号实时了解深度的公有云市场分析和洞察结果!点击右上角,在弹出的菜单中发送给朋友、分享到朋友圈。请在公众号搜索并关注:DongCloudInsight 或 东方云洞察。[b]需要点对点交流请加微信:jackyzhang523[/b]帮助您了解公有云相关的深度洞察结果。带来极具深度和最新鲜的:云市场分析、云机会洞察分析、云重大事件快评、云杂谈、云论坛资讯,以及公有云领域最高端的CEO面对面深度研讨。--- 最专注、专业的“公有云洞察”分享;关注全球,聚焦中国。
以下摘自CSDN媒体访谈稿件,过两天大家就会看到上线,今天我就先发了。 大数据经过几年的市场预热,目前应用案例已经逐步丰富起来,热度逐步上升。今天有幸我们请到了引跑信息科技有限公司(以下简称引跑科技)的副总裁,张晓东先生做一个访谈。张总在数据领域从业多年,以前在 IBM、Oracle、华为等公司工作多年,担任了数据库技术专家、资深云架构师、战略部高级总监等职位。从业经历丰富,今天有幸能与张总交流,非常难得。
下面我们以问答的形式来了解一下引跑科技公司在大数据的成功经验。
1. 张总,请先自我介绍下、所在公司以及负责领域。
大家好,我是张晓东,在引跑信息科技有限公司负责解决方案销售和市场营销相关的工作,今天很高兴能有机会给大家介绍一下引跑公司的大数据平台及相关产品,并分享一下个人对这个领域的一些看法。大数据很火,未来几年还将继续火下去,就像3年前的云计算一样,我们都知道云计算现在已经从炒作概念,到了实际落地阶段,谁干的怎么样市场已经给出了初步的答案。大数据处在概念炒作的晚期,市场应用预热的早期,所以未来几年对于大数据我们应该投入更多的关注。引跑公司在2008年成立,是由我们的创始人杨素东整合了一些来自国外Google、HP实验室的一些人才和力量构建的,杨总也获得了国家千人计划、中国云计算专家委员会等一系列荣誉。公司主要专注于做技术,以前和EMC、HP等公司有一些合作,并没有特意的在国内宣传,所以大家对我们不是很熟悉。目前我们拥有近300人的团队,其中75%是研发人员。引跑科技是全球领先的云计算技术与服务提供商,拥有大数据平台(EngineOne)、虚拟化平台(ScaleOne)、云应用平台(AppOne)、云管理平台(MasterOne)四大平台产品及不同行业云解决方案,并拥有多项核心发明专利与软件著作权。一下子说这么多名词大家可能有点晕,简单来说,我觉得引跑科技最核心的竞争力就是我们的并行分布式数据库产品DBone和分布式存储Storeone。在这两块领域,我们有信心和全球最顶尖的企业竞争。
2. 你们是基于什么样的机缘开发出引跑DBone的?
DBone是在我们老板杨素东的带领下开发出来的产品,他在美国留学和工作期间,和一些Google的朋友一起想做一些音频、视频分析的项目,结果数据量很大的时候传统的数据库无法支撑,不得已只好借鉴Google的分布式数据库架构,开始了分布式数据库的探索和实践。2008年杨总带领一些核心的团队成员回国创业,并专注在分布式数据库、分布式存储方面。经过这些年的打磨,已经成为一个完全自主产权的分布式数据库商业产品,可以作为国内自主可控的大数据基础平台。3. DBone是款什么样的数据库?具有哪些特性?与其他同类数据库相比有哪些优势?
总体而言,DBone是一款MPP架构的分布式数据库,按照传统的数据库分类来说是一款基于ShareNothing架构的数据库产品。MPP架构是一种无共享架构设计,MPP无共享架构是最易于扩展的架构,是云数据库和数据分析的最佳选择;通过MPP共享架构可以提供自动化的并行处理机制,使数据分布在所有的并行节点上,每个节点只处理其中一部分数据;MPP无共享架构是当前最优化的I/O处理架构,所有的节点同时进行并行处理,节点之间完全无共享,无I/O冲突;MPP无共享架构增加节点实现线性扩展,增加节点可线性增加存储、查询和加载性能。DBOne分布式数据库系统的高性能得益于其良好的体系结构。在DBOne系统中,每个分布式数据存储节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。 DBOne与传统的SMP架构数据库明显不同,通常情况下,DBOne系统中不存在共享资源,因此对它而言,可以使用的资源比传统SMP数据库系统要多,当需要处理的事务或数据达到一定规模时,DBOne的效率要比传统数据库高几倍甚至几十倍。我给大家提供几个图吧,更容易理解。DBOne分布式数据库通过MPP无共享架构把数据库表内数据行尽可能的均匀分布到每个节点。下图说明了DBOne分布式数据库系统大规模数据存储的基本原理和方法。
引跑的分布式数据库产品竞争对手主要是以Oracle Exadata、SAP HANA等产品为目标。适合的应用场景也主要以大数据分析为主,这种架构能够很好的解决超大表的查询、以及PB级别数据处理的性能问题,并能兼顾分布式事务处理的需求,当然强分布式事务的能力可不是哪个MPP数据库都具备的,引跑的DBone在这个领域还是很有核心能力的。相对于Hadoop等开源大数据处理解决方案,引跑的EnginOne大数据整体解决方案,能够很好的支持上亿级大表的嵌套查询,3-4层的嵌套查询能够很好的支持,通过两阶段提交的方式, 能很好的支持强事物。下面的表格列出了我们的大数据平台和Hadoop2.0为核心的解决方案对比。
4. 该数据库其架构是怎样的?有开源技术吗?
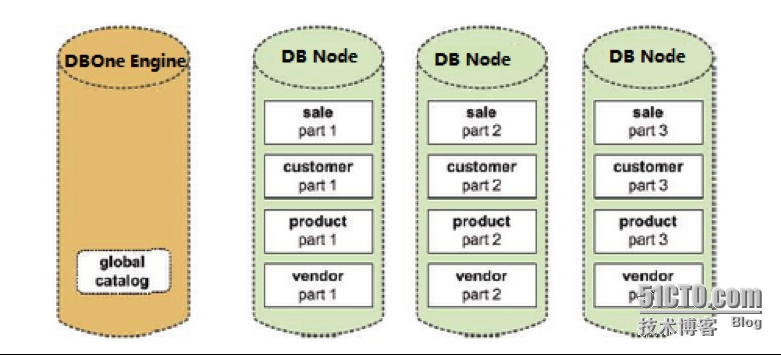
DBOne分布式数据库是一个弹性的、高性能、高可靠性,支持多应用、事务处理的分布式关系型数据库系统,支持热迁移、热备份、热恢复,提供标准的JDBC,ODBC, JSON, OGC等接口,或查询服务器(QueryServer)模式,支持所有主流应用开发语言如Java, C#, C, C++, Python, Perl等。DBOne分布式数据库提供一站式数据库管理工具,方便客户对数据库的部署、迁移、备份、恢复、容灾等常用操作。同时可用于OLTP、OLAP类型的应用,可管理海量的结构化、半结构化、地理空间数据,同时拥有弹性扩展的能力。架构如下图所示,大体上讲就是一个引擎层进行统一管理和调度,其负责SQL解析、优化、路由、分发、合并等操作, 同时将底层的众多存储节点管理起来。分布式存储节点使用引跑自行设计和完全自主可控的IDB(Intple DB)关系型数据库产品,每个数据服务节点处理具体的数据相关操作。早期我们借助了一些开源数据库产品的实现架构和部分功能代码,例如PostgreSQL、MySQL数据库等。分布式存储方面对于谷歌的GFS架构也有一定的参考,但是代码都是我们经过几年的不断改进积累下来的,目前已经完全实现的自主可控,在某些军方项目上都严格的做过和开源软件的代码比对,这对我们是最好的肯定。
5. 在开发DBone过程中有没有遇到难点?是如何解决的?
数据库作为一个基础平台,需要适配上层的应用,底层需要和操作系统、存储、硬件等进行适配,所以DBone的开发过程中有很多繁琐的工作要去做,需要不断的试验和修订才能更好的适配上下两层。最终我们提供了对业界开放标准的完全支持,例如:JDBC,ODBC,JSON, OGC等接口,或查询服务器(QueryServer)模式,支持所有主流应用开发语言如Java, C#, C, C++, Python, Perl等。 另外一个问题就是性能问题,DBone是通过一个引擎层作为上层的核心,客户的请求通过智能路由转发,自动的发送到相应的数据处理节点上。原理上虽然简单,但是涉及到高负载、大数据量的时候,处理效率的高低是最关键的技术难点,这其中涉及到很多的算法实现、优选以及通过发现问题,而解决问题的痛苦过程。 我们的研发团队对于这些问题的解决,主要是两个方式:1、学习和参考业界最新的算法实践、技术和解决方案,内部研讨适合我们的最佳方案,以改进性能问题。2、通过系统性思考解决实际问题,而不是仅仅为了攻克一个技术难关花费太多宝贵的时间和精力。对于我们这样一家300人的小公司而言,如何最高效的解决客户的问题才是最关键的。 我举个简单例子,在并行分布式数据库架构中扩展性是非常重要的功能,当新添加物理节点后,Shard数据重分布的效率问题一直是非常头疼的问题。我们在算法上做了优化,能够保证可移动的数据量最小,从而减少了时间。但是,这对高并发、负载很高的某些用户场景而言,还是不够。所以我们又从整体出发,在实例级别做了优化,通过整体拷贝的方式,优化一般算法情况下大量Shard中数据都需要重分布引起的性能问题。6. DBone在国内外使用场景如何?可否列举一二。
目前DBone主要应用于大数据分析场景,例如电信公司的历史话单和网元数据分析,从而识别用户画像,为精准营销服务。银行系统的征信分析和用户欺诈等风险分析都会需要DBone这样的大数据平台做支撑。 对于某些用户业务系统构建在Oracle多节点RAC之上的应用场景,我们会通过DBone的分布式数据库和用户生产系统进行连接,搭建双活集群,主要分担其中的分析型任务,甚至在外地城市构建异步双活容灾系统,这样使得客户的业务系统能够比较平滑的进行迁移。 近两年,政府大数据的分析应用逐步热闹起来,我们也在广东核高基项目、杭州政务云、气象局等领域有项目实践。预计未来的1年内大数据应用的热潮将更加繁荣,会给类似于引跑科技公司这样的大数据厂商提供更多的机会。7. 公司未来有什么规划吗?
公司的核心产品是并行分布式数据库和分布式存储,在这个基础上构建整体的大数据竞争力,这几年通过客户项目的积累,逐步发展了一些应用层面的产品,例如日志管理、舆情分析、企业安全网盘、内容管理等。在底层我们也有相应的硬件虚拟化产品和云计算解决方案。未来公司主要聚焦点还是在大数据基础架构解决方案层面,会紧密的团结很多ISV合作伙伴,共同做大数据市场。在硬件方面我们也是以合作为核心,2015年初,基于H3C的服务器推出了引跑大数据一体机,将来这仍然是我们的市场拓展重要方式,目前曙光、浪潮等国内知名服务器厂商都是我们重要的合作伙伴。8. 很多会人说数据库分久必合,合久必分,对此你是怎么看待的?
合久必分、分久必合貌似来源于国家和社会的变动规律。对于具体技术领域而言,这么说也不一定适合。就拿数据库领域数据的构建方式ShareNothing和Share Everything来说,以前一直是并行发展的两种架构,分别适用于OLAP和OLTP场景,然而现在随着硬件的进步,原有的架构模式也需要与时俱进,这泾渭分明的两种实现方式,目前也在融合。对,就是融合。 以OracleRAC为例,以前一直是共享存储的模式,比较适合于OLTP的场景。而Exadata在原有RAC基础上做了一些革新,其存储采用了半分布式架构,其存储的服务器和MPP存储实现模式很像,计算式分开的,最终汇总对上层RAC提供看似统一的共享存储。 我个人的观点来看,我觉得未来ShareNothing的架构将会发展的更加快速,并会逐步侵蚀OLTP的领域,这主要得益于硬件处理能力的进步,而成本降低很多。另外一个就是大数据浪潮使得传统的数据库实现架构无法满足大数据量的处理要求,无法满足客户的业务需求。需求是推动技术进步的最佳驱动力 所以从集中式和分布式这两个角度来看,我认为未来分布式的发展机遇更加大。它们之间会有一些相互借鉴和融合,但是未来3-5年不会有分久必合的状况。分布式架构具有更好的可扩展性,对基础软硬件的可靠性、可用性依赖度更低,可以采用更加开放、廉价的产品构建。但我们也要看到其给应用设计、研发、运维管理所带来的挑战。最后,我想说,越来越多的公司在大数据领域寻找发展的机会或是提升运营的效率,这说明企业有着向数据驱动的商业模式转型的需要。所以,大数据时代的企业应该采取以下的公式:新技术+新观念+商业转型=大数据策略。大数据技术和商业的结合刚刚开始,未来的发展非常值得期待。
扫描二维码关注【东方云洞察】公众号实时了解深度的公有云市场分析和洞察结果!点击右上角,在弹出的菜单中发送给朋友、分享到朋友圈。请在公众号搜索并关注:DongCloudInsight 或 东方云洞察。[b]需要点对点交流请加微信:jackyzhang523[/b]帮助您了解公有云相关的深度洞察结果。带来极具深度和最新鲜的:云市场分析、云机会洞察分析、云重大事件快评、云杂谈、云论坛资讯,以及公有云领域最高端的CEO面对面深度研讨。--- 最专注、专业的“公有云洞察”分享;关注全球,聚焦中国。

相关文章推荐
- 简单易懂云计算(转自天涯感谢原楼主iamsatisfied)
- 2011云计算知识库:盘点千奇百怪的云名称
- Patrol 7 架构下?的处理方法
- 康诺云推出三款智能硬件产品,为健康管理业务搭建数据池
- 中病毒后常用的解决方法病毒终极解决方案
- QQ尾巴 InfoMs.Ime 解决方案
- IE对CSS样式表的限制分析与解决方案
- 开源MySQL高效数据仓库解决方案:Infobright详细介绍
- MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
- 惊现支撑1亿pv/天的超级数据库解决方案
- 关于bluehost空间上wordpress后台变为英文的解决方案
- select * from sp_who的解决方案
- php+mysql大量用户登录解决方案分析
- php+ajax导入大数据时产生的问题处理
- C# 大数据导出word的假死报错的处理方法
- 用Python实现协同过滤的教程
- Python利用多进程将大量数据放入有限内存的教程
- mongodb常遇到的错误。
- 3ff8 《sharepoint 2010云计算解决方案》使用SQL Azure 的BI 解决方案
- IaaS, PaaS, SaaS 解释